
_for_the_high-end_consumer_market_(2019-04-20_10.23.53_piqsels.com_en).jpg){kind=link}
RPKIViews discovers and stores all the world’s RPKI data and makes it easily accessible in its original form to support a broad set of applications. Freshly signed RPKI material is collected globally from multiple topologically and geographically diverse vantage points using both rsync and RRDP synchronization and stored in compacted form in so-called rpkispools.
The rpkispool format is a modern approach for materialization of RPKI data in order to support a range of use cases, such as auditing Certification Authorities (CAs) and conducting analytical research. Rpkispools can be used for replication of raw RPKI data and associated validation states as efficiently compressed, durable objects. The method relies on industry-standard tooling (ustar, Zstandard, and CCR) and is designed to support long-term preservation of RPKI data cost-effectively.
In this article, we’ll dive into some of the technical details of capturing the RPKI distributed database and approximating storage requirements.
Data structures overview
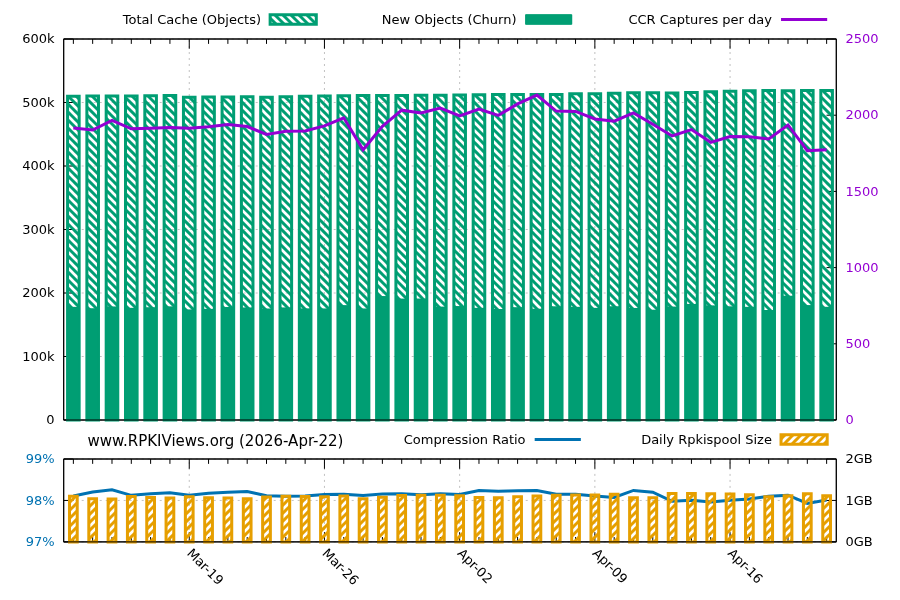
The rpkispool format revolves around a data structure called Canonical Cache Representation (CCR). To fully appreciate the function of CCRs, one should first consider the overall dimensions of the RPKI distributed database: As of April 2026, at any given time, a hot RPKI cache is around 1GB of Distinguished Encoding Rules (DER) — encoded data across ~ 515,000 objects.
Just like the Internet’s global Border Gateway Protocol (BGP) routing tables, the RPKI distributed database is constantly churning. Every few seconds, something changes somewhere. However, not everything changes all the time — the collection of data happens to remain mostly identical between two consecutive points in time. Assuming a capture rate of one full snapshot per minute, a naive implementation would need to store around 1.44TB per day or about half a petabyte a year, which is, put simply, unsustainable for most researchers.
Rpkispool offers a very different approach. Instead of storing full snapshot copies, only blobs of metadata for state reconstruction are stored alongside the raw RPKI data itself. This separation of concerns allows the state structures to refer to the raw RPKI data by SHA-256 hash, and in turn, the raw data can be stored in a fully deduplicated fashion. For example, a Route Origin Authorization (ROA) that didn’t change throughout the day is only stored once in the rpkispool for that day.
Another optimization is the use of Merkle trees in the state construction process: Sets of hashes that are consistently referenced together are stored only once, and such a set is then referenced by a single SHA-256 hash. When using the CCR format, it takes about 20MB to represent a particular moment in time (a big reduction compared with the 1GB required for a full materialized snapshot).
Using deterministic byte string formats leads to bizarre compression ratios. A single CCR takes 21MB and compresses to 10MB. But using Zstandard (Zstd), compressing 2,000 CCRs together reduces from 40GB in uncompressed form to merely 216MB in compressed form — a considerable reduction in size. Finally, by design, many byte strings appear identically encoded both in instances of CCR metadata and the raw RPKI data, which further optimizes the wire image for long-range Zstd compression.
Why was a repair needed?
A core feature of the CCR format is that certain byte strings are written out in a deterministic order to facilitate lookups based on hash comparisons. It was discovered that older versions of rpki-client in the period 1 January to 20 April 2026, applied an order reverse to the intended standard, breaking compatibility with other CCR implementations. Mea culpa.
The repair plan: Decompress all the RPKIViews.org rpkispools since the start of the year, read all the CCRs contained therein, re-sort the byte strings, write the standards-compliant CCRs back out, and finally recompress everything. To implement the re-sorting, I added a repair feature to the rpkitouch C utility and put a 16-core machine to work with a few gigs of free SSD disk space.
Some statistics collected during the repair process
In the span of two days, 110 rpkispools containing 190,601 CCRs and 19,452,194 RPKI objects were processed. Together, these are 62.86GB in compressed form and 4.37TB in uncompressed form. In the hypothetical full snapshot copy model, this might have been 190TB of material! This is worth salvaging in order to help establish the credibility of the approach and to aid future researchers.
There were some issuance discovery statistics about quantities of new material in that 110-day period of time: 2,379 distinct ASPA objects, 94,960 certificates, 486,213 ROA objects, 9,515,754 CRLs, and 9,522,408 manifest objects forming 1,936,647 unique event moments in the reconstructed issuance timeline. In this period, a total of 175,299 unique Manifest states were observed, which aggregated into 86,765 distinct validated ROA payload states and 5,749 distinct ASPA states. Phrased differently — every two minutes, someone somewhere adds or removes a ROA prefix, and globally, there is a change in ASPAs every 25 minutes.
New ROA issuances tend to cluster towards business days distributed across irregular moments, suggesting their creation to be rooted in human-driven activity. In contrast, Manifest objects tend to appear like clockwork at regular intervals, suggesting those instantiations are driven by automation.
Guidance for future researchers
The aforementioned repaired rpkispools were uploaded to the global RPKIViews mirrors (JP, EU, US) on 22 April 2026. The CCR files contained therein can be decoded by rpki-client 9.8 and higher and RIPE NCC’s rpki-commons library. Any binary data contained in rpkispools easily converts to JSON (-j) using rpki-client’s filemode (-f) functionality. Also noteworthy: CCR files can statelessly be converted to objects suitable for the Erik Synchronization Protocol, making them a useful backend storage format.
Job Snijders (homepage) is a consultant engineer who analyses and architects global networks for future growth. He specializes in Internet routing security and protocol design, and runs RPKIViews as a community project.
Originally published at Qrator Labs Radar.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.