

Round-trip time (RTT) is a key indicator of network performance. Abnormal changes in RTT can be indicative of pathological conditions such as network congestion, declining user Quality of Experience (QoE), or routing attacks.
In our recent paper at ACM SIGCOMM 2022, my co-authors and I at Princeton University proposed DART (Data-plane Actionable Round-trip Times), a system for continuous RTT monitoring directly in the data plane. DART leverages commodity programmable switches to operate on high volumes of data at line rate. While these switches come with memory and compute constraints, DART handles these by being both accurate and memory-efficient.
In this post, we discuss the key challenges involved with monitoring RTT continuously and the insights that enable us to address these.
Why perform continuous RTT monitoring?
Consider the following traffic-interception attack (Figure 1) where the communication between a client and a server in the US is hijacked.
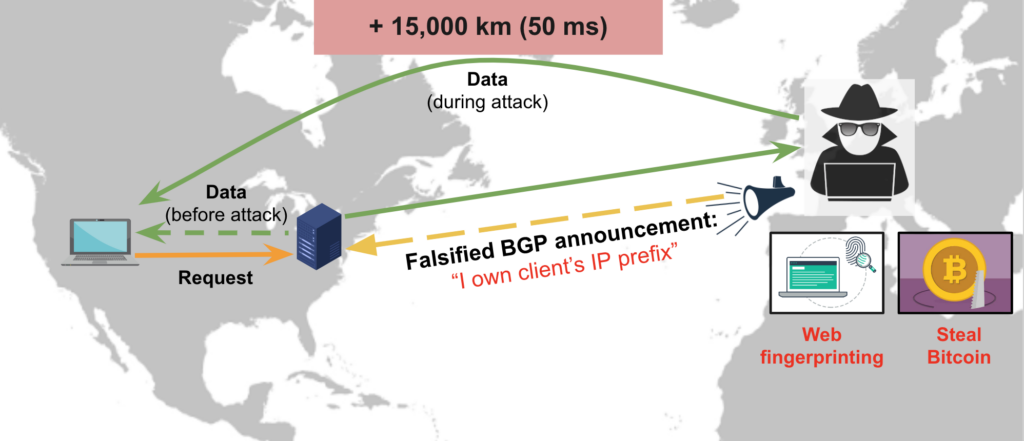
The adversary, located in Europe, eavesdrops on the traffic before forwarding it to the intended recipient. Their intention might be to perform web fingerprinting, steal cryptocurrency, or carry out other nefarious activities. Such attacks, usually launched by making falsified BGP announcements, can be notoriously difficult to detect using conventional methods.
However, notice that the traffic travels an additional 15,000km, consuming at least 50ms more RTT. Wouldn’t it be great if we could use the sudden rise in RTT during the launch of this attack to detect and stop it?
Why is it challenging to monitor RTT continuously?
For RTT monitoring data to be useful, it needs to be accurate, timely, and actionable. For example, during the aforementioned attack, the system should detect and mitigate it before the adversary sees too much of the sensitive traffic.
Existing tools such as ping and traceroute measure RTTs by sending active probes to a target host and timing the responses. This method introduces additional traffic in the network and does not capture the RTTs experienced by real users of applications.
Instead, measuring RTTs passively by observing user traffic provides a more accurate estimate. Operators can monitor RTTs at a vantage point en route to many end hosts (for example, near a campus or enterprise edge) and easily aggregate RTTs to all their clients. Monitoring at the edge offers the additional advantage of computing internal leg RTT (between the monitor and the end user) and external leg RTT (between the monitor and the remote end host) separately.
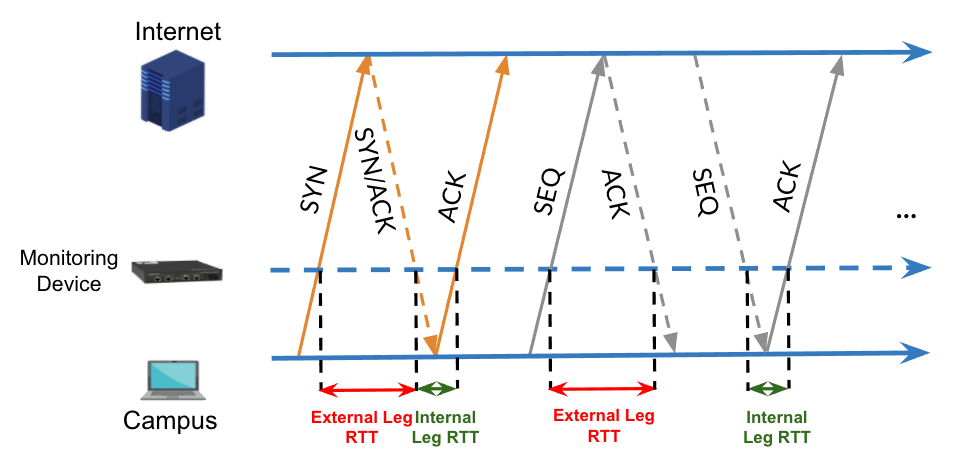
Passive RTT monitoring for TCP involves matching sequence (SEQ) packets with their ACKs (Figure 2). While only the TCP three-way handshake can be used to compute an RTT sample, this does not capture changes in RTTs over the lifetime of long flows (for example, video streaming). Therefore, we must monitor RTTs continuously, beyond the initial TCP handshake.
For non-TCP traffic, such as QUIC and RTP-based video conferencing, RTTs from co-located TCP traffic between the same end-points or IP prefixes can help estimate RTT for the non-TCP traffic.
It’s important to note that computing RTTs continuously is challenging because:
- The idiosyncrasies of the TCP protocol, including packet retransmissions and reordering, can make some RTT samples inaccurate.
- Software tools like tcptrace and pping maintain expensive per-flow state and perform complex computations to ensure accuracy.
- Real-time RTT monitoring in software is too slow for networks with high traffic volumes. Fortunately, the emergence of commodity programmable switches (for example, Intel Tofino) and the P4 language makes it possible to monitor RTTs and make adaptation decisions directly in the data plane. However, the high-speed data plane imposes significant constraints on packet processing. It limits memory size and complex arithmetic, allows bounded processing in a single pass of the packet, and incurs additional costs if more passes (recirculations) are needed.
To address these challenges, we developed DART which builds upon a strawman design based on previous work from our research group.
How DART works
Continuous RTT measurement requires a hash table, called the Packet Tracker table, to store SEQ packet records until the corresponding ACKs arrive (Figure 3).
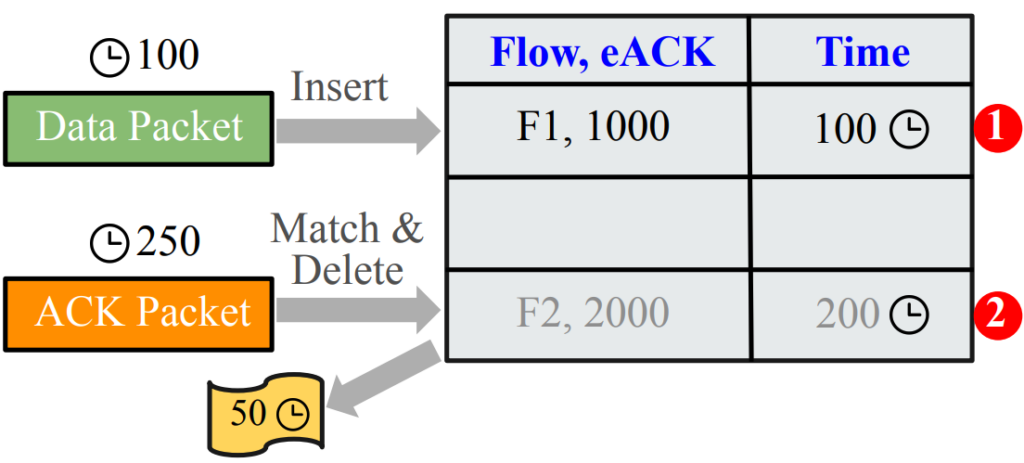
The table is indexed by the SEQ packet’s unique identifier — the flow identifier (4-tuple of client and server IP addresses and TCP port numbers) and a unique packet identifier within the flow (the expected ACK number or eACK). A record with the timestamp is created when a SEQ packet arrives (labelled 1 in Figure 3). When a matching ACK packet arrives, we look up the SEQ entry using the key (labelled 2). We subtract the SEQ timestamp from the ACK timestamp to compute the RTT sample.
Unfortunately, the strawman design can lead to incorrect RTT samples. And even if correctness is somehow ensured, an additional challenge arises because TCP can ACK multiple SEQ packets cumulatively to reduce overhead. DART handles these challenges using two key insights.
Tracking valid sequence number ranges
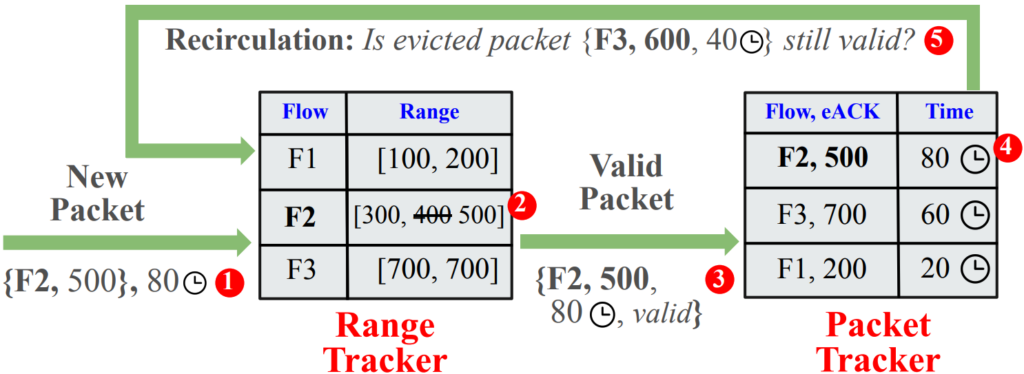
To avoid storing SEQ records that could cause ambiguous RTT samples, we tracked the valid range of TCP sequence numbers for each active flow. To this end, we placed a Range Tracker table in front of our Packet Tracker table, with the flow 4-tuple as the key and the valid range as the value (Figure 4).
Lazy eviction with a second chance
Second, to prevent unmatched SEQ records from waiting indefinitely, we performed lazy eviction at the Packet Tracker table. This means that upon a hash collision between a new SEQ record and an existing record, we temporarily evicted the existing record, recirculated it to the front and re-evaluated it against its flow record in the Range Tracker table. If we saw ACKs to packets newer than this evicted record in the valid range, then we knew it was no longer useful and purged it. If the evicted record was still valid, we reinserted it and gave it a second chance of contributing to an RTT sample.
How DART performs
We have implemented a hardware prototype of DART for the Intel Tofino and have shown that it can help detect the interception attack within 22 SEQ packets (two seconds).
We’ve also shown that DART can closely match the accuracy of the software tool tcptrace, while still operating at line rate on high volumes of data.
It is worth noting that attack detection is merely one use-case of DART — it can help detect network congestion, perform efficient traffic engineering, select servers for cloud gaming, and so on.
Read our paper Continuous In-Network Round-Trip Time Monitoring and listen to my talk at SIGCOMM 2022 to learn more about DART.
Satadal ‘Sata’ Sengupta is a PhD student in the Computer Science department at Princeton University.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
So happy more and more are listening to networks like kathie nichols was suggesting WAY back in 2017: https://pollere.net/Pdfdocs/ListeningGoog.pdf