

Data heavy video applications like augmented and virtual reality (AR/VR), cloud gaming and video conferencing demand very low communication latency.
While communication technologies such as 5G and fibre-to-the-home (FTTH) are meeting this requirement from the network side, the current architecture of the Internet, more precisely the operation of the Transmission Control Protocol (TCP) congestion control algorithms, is causing issues.
In this post, I want to highlight these as well as a collection of new services and methods that my colleagues and I assessed as part of our paper we presented at ANRW’20 that are working towards solving them.
The problem with TCP
To achieve full network capacity utilization, a large amount of buffering in the routers or switches is required. However, in these buffers the packets suffer additional queuing delays. In unfortunate situations, this latency is the accumulation of the queuing delay of multiple devices. This additional latency also makes the TCP’s congestion control algorithm work harder to react to congestion events (like packet drops) quickly.
As a consequence, TCP versions prevalent on the Internet today are drastically reducing their sending rate in case of event congestion (for example, halving their congestion window). In the event that congestion does happen packets will be dropped due to a full buffer or exceeding the delay threshold configured in the active queue management (AQM).
If the return-trip-time (RTT) between the sender and the receiver is low enough, the sending rate will grow quickly until the bottleneck reaches capacity. However, if the delay is high, the sender adapts slowly, which leads to underutilization.
Ideally it would be nice if the TCP sender could guess the amount of congestion better. In that case, the sender can avoid the drastic reduction of the congestion window and align the sending rate more tightly to its actual fair capacity share.
Dealing with congestion better by prioritizing fair traffic
Luckily, TCP versions with this behaviour already exist, such as DCTCP, BBRv2 and TCP Prague. However, they need help with congestion feedback from the network.
Read: Modelling BBR’s interactions with loss-based congestion control
One such feedback method is the Explicit Congestion Notification (ECN), which uses specific fields from the IP header: ECN Capable Transport (ECT) and Congestion Experienced (CE). The exact semantics of the ECN is the subject of active debate in the IETF, with one proposed application showing promise: Low Latency, Low Loss, Scalable Throughput (L4S).
L4S
A L4S service would allow network administrators to configure their router’s AQM to mark the packets as per CE if the target queueing delay is exceeded. The L4S compatible TCP versions could then deduce the degree of congestion by the ratio of normal and CE-marked packets and thus reduce the sending rate accordingly. During normal operation, this method would completely avoid packet drops caused by congestion and retain high utilization and low latency. Unfortunately though, this solution doesn’t work on today’s Internet.
Even if communication partners are supporting ECN (with the “same-as-drop” semantic defined in RFC 3168) the intermediate routers need to do it too. Without that there are no guarantees for proper operation.
It is also a problem if the L4S traffic is queued in the same buffer with the non-L4S (classic) traffic. However, it is possible to achieve a fair share among them with capable AQM algorithms like PI2 or Core Stateless AQM (CSAQM), but the L4S traffic will suffer large delays. That is because the classic traffic will fill the buffer or reach the target delay (which is high to achieve good utilization).
L4S + Fair Queue AQMs
One possible solution to this problem is to use Fair Queue (FQ) AQMs in the bottleneck, for example, FQ-CoDeL or FQ-PIE. These would allow all flows to get their own queue, all served equally.
A drawback, though, is that FQ algorithms are memory hungry and require transport header inspection, which is not always available. Also, while the software implementation of many queues would be possible, the hardware (or programmable data plane) implementation of them is much harder.
An alternative solution is only defining two queues: one for the L4S and one for the classic traffic. This would also be easy to implement everywhere.
One such two-queue, L4S-capable AQM configuration is DualPI2, which classifies traffic by inspecting the ECT bit and directs the packets into the L4S or classic queue. Then, the PI2 AQM algorithm calculates a drop probability, and the DualPI2 will derive the drop probability from that to the classic queue and the marking probability to the L4S queue.
With this solution, DualPI2 achieves equal sharing of the bottleneck capacity between the two types of traffic. However this algorithm expects that the TCP versions competing in the L4S queue are using the same congestion model (likewise in the classic queue). But this assumption cannot be met due to the constant evolution of the TCP versions.
Virtual-Dual Queue Core-Stateless AQMs
The Virtual-Dual Queue Core-Stateless AQM (VDQ-CSAQM ) is another new L4S compatible AQM that does not assume compatible TCP versions in any queue.
Similar to the FQ AQMs, it is capable of applying the right amount of marking or dropping ratio for every flow. For example, DCTCP and BBRv2 are not compatible — they deduce their sending rates differently from the same ratio of ECE acknowledgements — but VDQ-CSAQM can achieve good fairness between them.
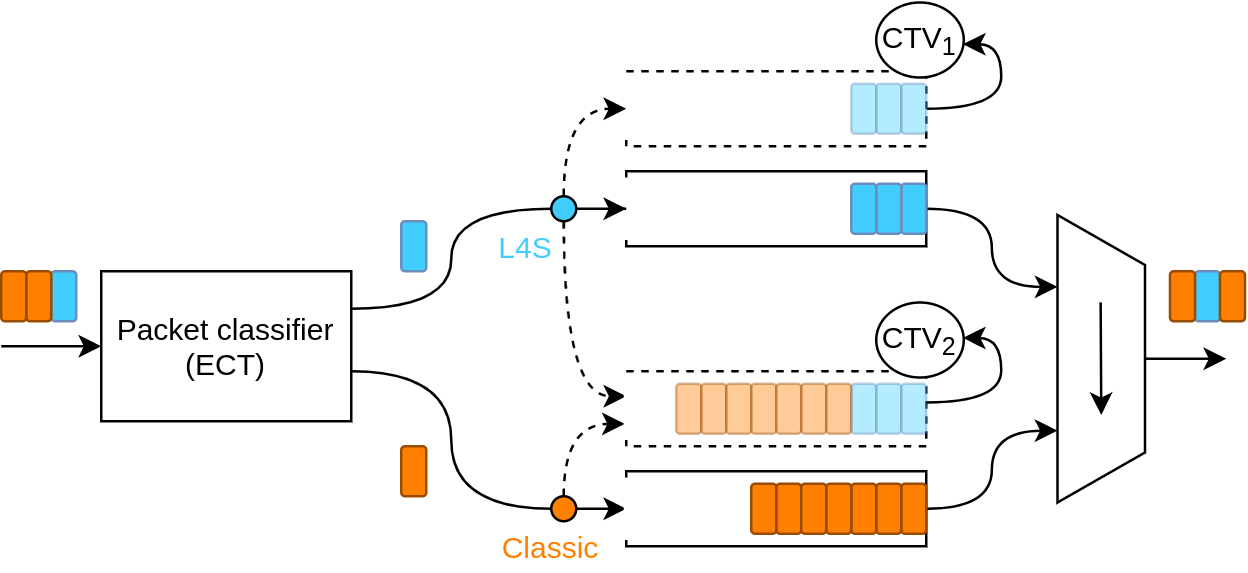
Further, the VDQ-CSAQM, unlike FQ algorithms, can be implemented in programmable switches. And its parameterization is not RTT dependent as opposed to DualPI2, therefore, it can achieve better fairness in traffic mixtures with heterogeneous RTTs. But there’s a catch.
VDQ-CSAQM is based on the per-packet value (PPV) concept, whereby marker nodes near the source of the traffic (or network edge) assign a value to every packet of every flow (or traffic aggregate). This value is derived from a function, for example, a throughput-value function (TVF), which assigns higher values to lower sending rates. This PPV is then stored in the packet itself.
In case of congestion at the bottleneck, the VDQ-CSAQM marks or drops packets with the lowest PPVs first. According to the TVF the flow with the highest (or most unfair) sending rate will be marked with the lowest packet value so that will reduce its sending rate. This operation always forces the greediest flow to reduce its sending rate. The algorithm actually maintains two Congestion Threshold Values (CTVs) to avoid the expensive search of the minimum PPV in the queues, and mark/drop packets with PPVs under the CTV.
Importantly, VDQ-CSAQM is agnostic to the number of the flows: the algorithm deals with millions of flows without any scaling issues and provides a FQ degree of fairness.
The weakest point of the solution is the need for storing the PPVs. In a private network, the administrator can decide in which header they put the PPVs but on the public Internet that is not currently possible. As such, standardized header fields are required for PPV to be viable.
Ferenc Fejes is a doctoral student at the Department of Information Systems, Eötvös Loránd University.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Good Direction, Maybe in the limit domain, L4S can get more useful when TCP congestion control can be modified