

Internet congestion control mechanisms were initially designed for scenarios where networks are overloaded, that is, sending rates would be either moderate or large compared to available link capacities. Moreover, it has been common to assume that applications produce long, ‘greedy’ flows, which are able to saturate a path’s capacity over time.
Things have changed. Over the last two decades, Internet capacities have grown vastly. Since the 2010s, social networking applications — not only web-based but also real-time gaming, video conferencing and messengers — have become ever more popular. Websites, messengers and games produce transfers that usually need only a handful of packets. One-way video such as Netflix often consists of short bursts with long pauses, and the rate of an interactive video or audio application is commonly limited by the codec. None of these applications is easily able to probe for the available capacity.
In this scenario, Internet congestion control algorithms are less aware of the available capacity and therefore use a rate that is unnecessarily low because they lack a proper feedback signal. Protocols such as TCP and QUIC have an increasingly large operational space where they do not obtain any capacity feedback at all. Three measurement studies confirm this:
- A recent measurement study revealed that in a large dataset consisting of traffic traces that were captured on a Tier-1 Internet Service Provider (ISP) backbone in Chicago between June 2008 and March 2016, 85% of all TCP connections carried between 100B and 10KB of data.
- During measurement of one week in 2017 in the mobile search service of Baidu Inc., 80.27% of all TCP connections terminated in a slow start.
- In our paper, we looked at the 15-minute-long traces for each month from January 2019 to November 2021 at the transit link of the Japanese WIDE backbone network. Our findings revealed that 85.5% of the TCP connections have no retransmissions.
In all these cases, more than 80% of TCP connections did not obtain any information about the available capacity.
This situation has not gone unnoticed by companies such as Google which heavily rely on minimizing the completion time of short data transfers. Accordingly, Google has put forward a number of fixes for this problem in recent years — reducing the number of management round-trips with QUIC and TCP Fast Open (TFO), increasing TCP’s Initial Window from 4 to 10 to improve the slow-start behaviour and the new BBR congestion control mechanism which, different from most other congestion control proposals, not only affects congestion avoidance but slow start as well.
However, in our paper, fellow researchers from the University of Oslo, University of South-Eastern Norway, Lancaster University and I posit that such end-to-end improvements will not be sufficient. This is because end-to-end congestion control standards are meant to operate uniformly on a worldwide basis, but this is not how capacities truly evolve.
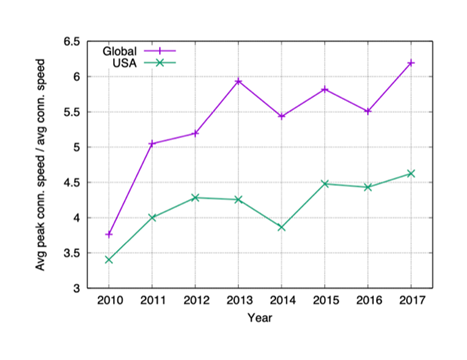
Firstly, across the world, it seems that low-end connectivity does not disappear just as quickly as the high-end improves. Figure 1 depicts data from Akamai’s ‘state of the art’ Internet reports, which show that while the average capacity has roughly quadrupled, both globally and in the USA, from 2010 to 2017, the global average peak capacity in 2017 is seven times more than in 2010. In the USA, the average peak capacity was 5.4 times larger. We observed a similar trend in our measurement lab datasets, covering throughput measurements across 90 economies. This growing range of capacities that a congestion control mechanism needs to deal with means that we cannot simply increase standard parameters such as TCP’s initial window forever.
Secondly, in the modern era, we commonly use wireless links to connect to the Internet for all our applications, and such connections are often the bottleneck. It is, therefore, no longer correct to assume that the bottleneck capacity of an end-to-end Internet path remains stable. Link layer rate adaptation mechanisms have long existed in Wi-Fi, for example, and such fluctuations are only bound to become more severe in the future. Consider, for example, millimetre Wave (mmWave) — a new technology adopted by 5G, IEEE 802.11ay, and vehicular communications. Here, obstacles can entirely hinder any communication, leading to sudden outages and high fluctuations in the available capacity. A recent paper used a real-life mmWave trace to show that such fluctuations in the data rate are very problematic for modern congestion control mechanisms. This is because the end-to-end control loop is only informed about a capacity drop but may never learn that capacity has become available again, resulting in an underload problem.
In our paper, we suggest that the focus of Internet congestion control should shift away from the current end-to-end approach. This would allow replacing the present design of ‘one size fits all circumstances’ with a selective set of mechanisms so that congestion control can operate with suitable feedback signals in different network environments. However, there are many open research questions that would first have to be answered to make such an architectural shift a reality.
We outline some possible future directions for researchers in the paper ‘Future Internet Congestion Control: The Diminishing Feedback Problem’.
Safiqul Islam is an Associate Professor at the University of South-Eastern Norway. His research interests include performance analysis, evaluation, and optimization of transport layer protocols.
I would like to thank my co-authors Professor Michael Welzl, Dr. Peyman Teymoori, Professor David Hutchison, and Professor Stein Gjessing for their contributions in our paper, especially Michael for co-authoring this blog post.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
I wish those behind mmwave had looked harder at the minstrel rate control algorithm, common in wifi.
https://blog.cerowrt.org/post/minstrel/
The present implementation using “variance” presents a more stable outcome friendlier to other congestion control algorithms and AQMs.