

The Internet has many flows. It is important to have a mechanism that decides what share of the total available bandwidth is allocated to each flow. Given the large number of flows on the Internet, it is infeasible to do this in a centralized fashion. Hence more distributed and scalable mechanisms are needed. Congestion Control Algorithms (CCAs) form a key component of this infrastructure.
Network endpoints use CCAs to determine the rate at which to send packets using end-to-end signals such as packet loss and delays. When multiple flows share the same link (and the same FIFO queue), the CCAs are responsible for converging to a bandwidth allocation that achieves some network-wide objective. Usually, this involves some notion of fairness. In a recent paper, my fellow researchers and I from the MIT Computer Science and Artificial Intelligence Lab (CSAIL) show that although designed to achieve reasonable inter-flow fairness, current methods to develop delay-bounding CCAs cannot always avoid starvation, which is an extreme form of unfairness.
This happens because real-world phenomena such as ACK-aggregation, token bucket filters and variability in OS scheduling cause packets to be lost and delayed for reasons other than congestion. This can fool CCAs into mis-estimating congestion. While some amount of unfairness, such as loss-based TCP’s Round-Trip Time (RTT) unfairness has always been tolerated, starvation is both unexpected and unacceptable for many applications. We were also surprised by how prevalent the problem was. We defined a class of CCAs that we called ‘delay-convergent’ and showed that every such CCA will suffer from starvation. Every bufferbloat-resistant CCA that has been proposed so far (that we are aware of) is delay-convergent and hence susceptible to the starvation issue we identified. This includes BBR, Copa, PCC, FAST and Vegas.
The conditions under which starvation occurs are also likely to be common on the Internet. Let us take BBR, a widely deployed CCA originally proposed by Google, as an example. BBR is a complex algorithm. For the purposes of this blog post, it suffices to know that when there is some jitter (of any kind) in the delays experienced by packets, BBR will maintain a queuing delay that is equal to the propagation delay. The problem occurs when two flows having two different propagation delays share the same FIFO queue. In this case, they try to maintain different queuing delays, which makes them fundamentally incompatible with each other. As a result, the one with the smaller propagation delay will interpret the higher queuing delay maintained by the other flow as congestion, and slow down.
In summary, when two long-running flows with different propagation delays share the same bottleneck queue, the one with the smaller delay starves if the flows also experience some delay jitter. The higher the bottleneck rate, the larger the ratio of throughputs obtained by the two flows. This also works with more than two flows.
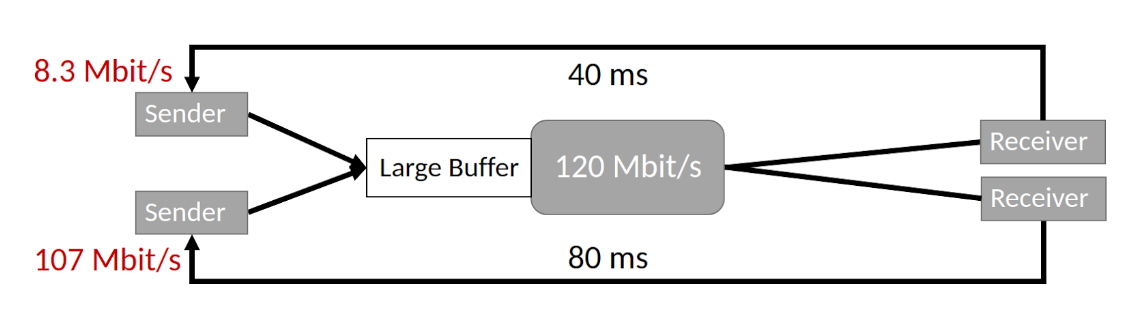
To test this experimentally, we emulated a network (shown below) with a bottleneck link rate of 120 Mbit/s using Mahimahi. We gave the two flow propagations a delay of 40 ms and 80 ms respectively. The 40 ms flow got 8.3 Mbit/s while the other got 107 Mbit/s. The difference is more than 10×! This is easy to reproduce across a wide variety of parameters. In fact, we did not even explicitly add any jitter. OS jitter added due to the Mahimahi emulation was sufficient.
Why do all delay-bounding delay-convergent CCAs starve? Because packets are delayed due to congestive and non-congestive reasons, it is difficult for the CCA to estimate the delay due to congestion (that is, queuing at the bottleneck); it can only measure end-to-end delay. Thus they can only measure congestive delay up to some finite precision determined by the characteristics of the non-congestive delay.
Most theoretical analyses that prove the CCAs are fair ignore this detail. In practice, non-congestive delay can range from a few milliseconds over ethernet to 100 ms in wireless networks. Now, modern CCAs also try to bound delay to a finite value even as the buffer becomes arbitrarily large. This is important to combat bufferbloat.
Combined with imprecision in estimating congestion, this means that there is only a finite, and often small, number of queuing delays that the CCA can distinguish between. However, it needs to operate across a large range of link rates, from 100 Kbit/s to several Gbit/s. One cannot map a small number of distinguishable delays to such a large range. This causes the starvation issue we identify.
While this was a hand-wavy argument and missed many details, our paper provides a detailed model and rigorous proof that shows how all delay-bounding, delay-convergent CCAs must suffer from such problems. It also analyses how this affects practical algorithms including BBR, Vegas, FAST, Copa and PCC.
What does this mean for operators? If we cannot trust end-to-end CCAs, we must provide in-network support. Strategies used today include fair queuing and ECN-enabled routers. Where fair queuing is infeasible due to traffic volume, we simply rate-limit incoming traffic to a point where they are unlikely to cause congestion at a core router as a rate-limiting router may be able to provide some type of fair queuing. Other techniques include centralized allocators such as Microsoft’s SWAN and Google’s BwE.
Further, we only proved that delay-bounding, delay-convergent CCAs do not work. While all existing delay-bounding CCAs we are aware of are also delay-convergent, it may be possible to construct one that isn’t and avoid the starvation issue. In this case, we can rely fully on CCAs to ensure proper bandwidth sharing, at least in the cases where no flow is malicious. This would save the cost of deploying fair queuing, SWAN, or BWE.
For more information read our paper “Starvation in End-to-End Congestion Control” which was presented at SIGCOMM 2022.
Venkat Arun is a PhD student at MIT’s Computer Science and Artificial Intelligence Lab (CSAIL) with an interest in using formal methods to understand the performance of networks.
Mohammad Alizadeh and Hari Balakrishnan contributed to this work.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Thx for calling out fair queuing. I long ago concluded (without rigorous proof) that delay based transports worked best in a FQ’d environment.
The fq+codel/pie/cake algorithms take classic fair queuing a step further by an incentive structure that essentially garuntees a flow with an arrival rate lower than the departure rate of all the other flows, would see *zero* queuing aside from jitter induced effects elsewhere.
We call this “flow queuing”:
See: https://ieeexplore.ieee.org/document/8469111
for more details.
As effective as this mechanism already is, I keep hoping that the packet pacing folk (another key idea) will stop sending packets back to back but fully spread out, OR take advantage of microscopic differences in service time when packets are back to back or not, to tune their behaviors.
Also, delay and jitter, in a modern DC chock full of overlays, is really enormous. Here are some recent results from a DC I have under tests. The different CC’s and AQMs I used were irrelevant compared to the underlying infrastructure’s whims. https://lqos.taht.net/p2p-tests/
“For the purposes of this blog post, it suffices to know that when there is some jitter (of any kind) in the delays experienced by packets, BBR will maintain a queuing delay that is equal to the propagation delay. ” Could you please explain on this?