

Have you ever wondered why your (or someone else’s) implementation doesn’t work perfectly, even though you have followed (as much as possible) the protocol specification? It could be due to the ambiguities inside the specification itself. How can we fix this problem? In this blog post, I’ll explain the issues and introduce a new tool to help.
Where do these ambiguities come from?
Why do we use English to write specifications? English, as a natural language, is inherently ambiguous, but it’s popular for creating specification documentation. This might sound contradictory, but it does make some sense. There are multiple ways, and languages, to specify a formal protocol document but the stricter the language is, the harder it is to read and develop specifications. Formal specification language is precise and great for validating protocol behaviours, but the learning curve to use it is a great hurdle. Due to this, the common practice remains of specifying protocol behaviours in English, including sometimes adding other components (such as pseudo-code or diagrams) inside the specification to avoid ambiguity.
How are specifications written?
A common practice is that a Working Group will gather and decide how and what the protocol behaviour should be, and one or more authors will generate the corresponding specification components, as shown in Figure 1. The components could involve textual sentences, ASCII art, pseudo-code and sometimes reference code.
While all these components, combined, are effective at avoiding misconveying protocol behaviours, we still have a limited understanding of whether ambiguities exist among the components.
A tool to help: SAGE
To help with these longstanding issues, fellow researchers from the University of Southern California and the Budapest University of Technology and Economics, researched a semi-automated approach to protocol analysis and code generation from natural language specifications and the result was SAGE. SAGE reads the natural-language protocol specification (such as an RFC or Internet Draft) and marks sentences for which it cannot generate a unique semantic representation, or which fail on the protocol’s unit tests. The former sentences are likely semantically ambiguous whereas the latter represents under-specified behaviours. In either case, the author of the specification can then revise the sentences and rerun SAGE until the resulting RFC can be cleanly turned into code. SAGE’s process involves three major components: Semantic Parsing, Disambiguation, and Code Generation.
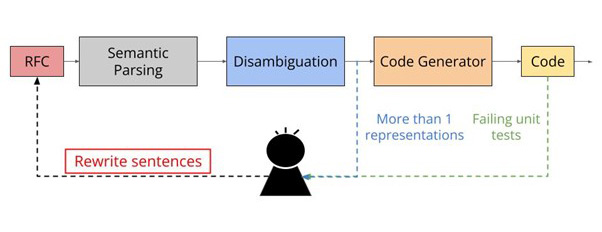
The SAGE process works like this:
- It identifies ambiguities and under-specification by parsing a specification and gives an intermediate representation, called logical forms (LFs);
- SAGE then uses these LFs to resolve any ambiguities that are due to limitations of semantic parsing tools and identifies when to seek human input to expand its own vocabulary to parse a sentence;
- It automatically generates executable codes after disambiguation.
Identification of ambiguities and under-specification
To identify ambiguities, we need to understand the semantics of a specification, which is commonly termed semantic parsing in the Natural Language Processing (NLP) paradigm. Once we extract the semantics, we leverage the semantic representations to analyse the existence of ambiguities. When a sentence generates zero or more than one semantic representation, we consider it a true ambiguity.
When some specifications fail to precisely describe a part of the protocol behaviour (or even omit the description), instances of under-specification could exist. For such under-specification, we leverage unit tests/reference implementations/third-party implementations to interoperate with the generated executable code and identify the buggy points.
For either ambiguities or under-specification, we provide feedback to SAGE users and suggest sentences be rewritten until executable code can interoperate with the reference implementation or third-party implementations.
SAGE-discovered ambiguities in ICMP
An example that shows the existence of ambiguities is the Internet Message Control Protocol (ICMP). ICMP, defined in RFC 792 in 1981 and used by core tools like ping and traceroute, is a simple protocol whose specification should be easy to interpret. After applying SAGE on the ICMP RFC, we discovered five instances of ambiguities and six instances of under-specification. We categorized the cases (Table 1) that contribute to zero or more than one semantic representation and that imprecisely specify implementations.
| Category | Example | Count |
| More than one LF | To form an echo reply message, the source and destination addresses are simply reversed, the type code changed to 0, and the checksum recomputed. | 4 |
| 0 LF | Address of the gateway to which traffic for the network specified in the Internet destination network field of the original datagram’s data should be sent. | 1 |
| Imprecise sentence | If code = 0, an identifier to aid in matching echos and replies, may be zero. | 6 |
What’s next?
Our system demonstrates great potential for automating protocol code generation from unambiguous texts and effectively identifying ambiguous sentences. However, it still has limitations. SAGE can process self-contained sentences but needs an additional mechanism to extract and analyse context if the semantics of a sentence are dependent on additional information not included in the sentence. Furthermore, SAGE processes one specification at a time. Still, we reasonably expect that functionality can be extended to aggregate information across multiple specifications (or even unify the configuration across multiple layers of protocols). Ultimately, we would like to see a comprehensive system that can consume specifications of multiple layer protocols and automatically generate code.
Read more in our papers “Semi-Automated Protocol Disambiguation and Code Generation” and “Tools for Disambiguating RFCs” or check out SAGE on GitHub.
Yu-Chuan (Jane) Yen is a PhD candidate at the University of Southern California.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.