

Secure and reliable Internet protocols are critical for day-to-day life. They support our national security, transportation, energy, water supply, banking, and other essential infrastructure, as well as non-necessities like online video games and movie streaming services. Such protocols are not only more important with time, but also more complex, with the emergence of technologies like 5G, the rise in cyber warfare and cybercrime, and the technological implications of rapid globalization. Thus, protocol security is an important problem, with many competing approaches such as fuzzing, languages with built-in safety features, simulation testing, and so on.
At the Northeastern University Networks and Distributed Systems Security (NDS2) lab, we study how to find vulnerabilities in protocols, and we invent methods and tools that can do this task automatically. Several of the tools created by our group include KORG, SNAKE, and TCPwn.
These tools require a formal representation of the protocol, called a Finite State Machine (FSM). The FSM is a graph with nodes and edges, where nodes represent protocol states (like ‘connection closing’ or ‘connection established’) and transitions encode changes in state (like, ‘after receiving an ACK, move to the established state’). Although FSMs sound simple, in reality, they are challenging to code correctly, because they need to capture all the high-level protocol behaviours under some formal network semantics. Formalizing a protocol FSM is made even more challenging when the protocol specification, typically written in English text, is ambiguous or as sometimes occurs, omits important information.
With the recent interest in using data to automatically solve problems in several fields, we asked the question: ‘Can we automatically learn protocol FSMs from their prose specifications?’ We examined IETF Request for Comments (RFC) documents, which describe Internet protocols in English like Transmission Control Protocol (TCP), Datagram Congestion Control Protocol (DCCP), Stream Control Transmission Protocol (SCTP), Licklider Distribution Protocol (LDP), and so on. We built a Natural Language Processing (NLP) pipeline that could read these documents, understand which parts described states, variables, events, triggers, transitions, messages, and so on, and then extract and automatically attack corresponding FSMs.
There are two main challenges in building such an NLP pipeline. The first is that off-the-shelf NLP tools are not typically trained on technical datasets such as RFCs, and thus they will break when used directly on technical documents. The second challenge is how to create a method that generalizes across many protocols. We solved the first challenge by learning a technical language embedding model from all the RFC documents. We solved the second challenge by creating a grammar representative of all the protocols.
Specifically, our approach consisted of four steps. First, we collected a corpus of RFC-related documents such as technical forums, blogs, research papers, and specification documents. We exploited these documents to learn a distributed word representation, also known as an embedding model, for technical language. In particular, we used a BERT embedding model, which we pre-trained using the masked language model and the next sentence prediction objective with networking data. This step did not require any manual annotation!
Second, we designed a grammar that described the main elements of a protocol FSM such as special tags for states and variables, and we trained NLP models to annotate RFC documents with this grammar. As we could not use off-the-shelf NLP models, because they are trained on newswire text and misinterpret technical language, we trained our own models (a linear conditional random fields model, and a neural analogue) on technical forums, RFC documents, and so on. We took a zero-shot approach, meaning we tested our models on RFC documents that were completely unobserved during training.
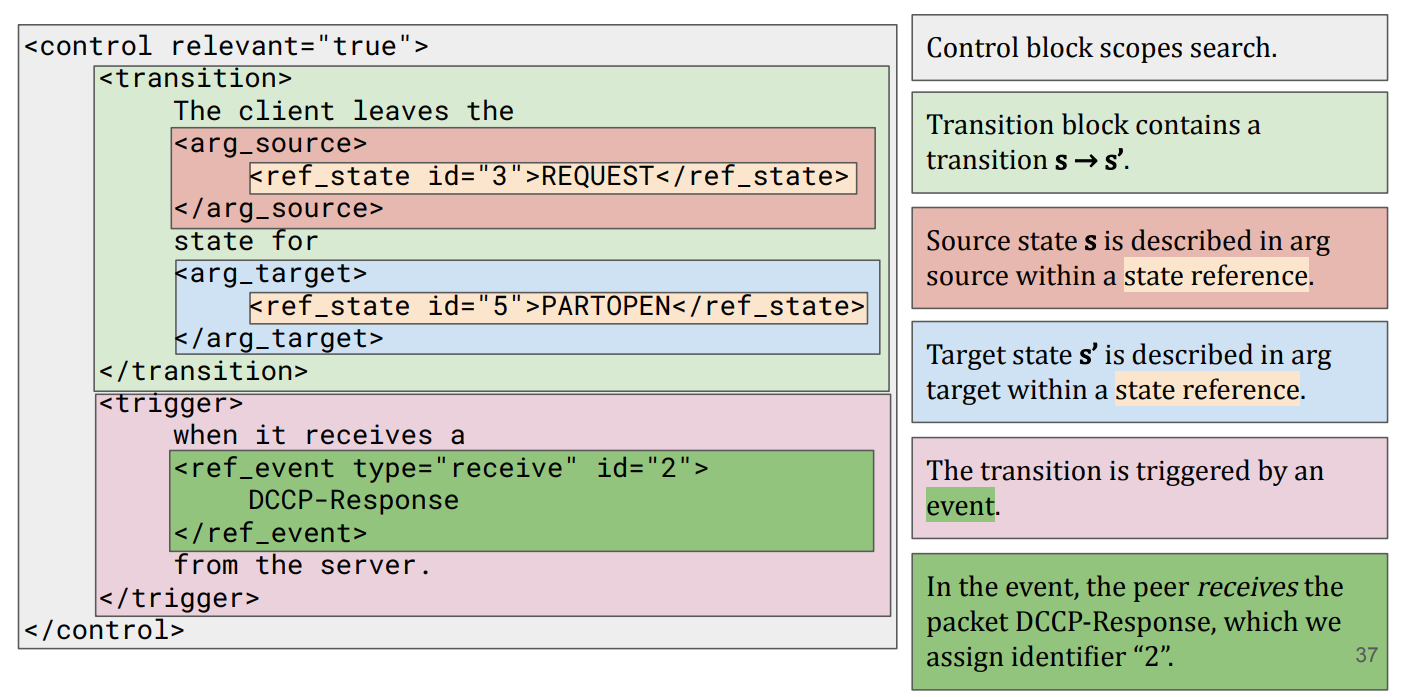
Third, we heuristically mapped the NLP-annotated text to actual FSMs. This process involved a search algorithm defined over the XML structure of the grammar, as well as multiple heuristics for removing incorrect transitions from the extracted FSM.
The fourth and final step was to validate the extracted FSM by using it for a real-world application. For our motivating application, we used our automated attack synthesis tool, KORG. We found well-known attack strategies against TCP and DCCP, showing that the automatically extracted FSMs were accurate enough for attack discovery.
What next? In the future, for RFC creators, we hope our work can help automate the process of identifying omissions, ambiguities, and logical flaws in RFC documents while they are being written. Second, for creators of bug or attack discovery tools, we hope our work can illuminate an exciting (and open) area of research — how to extract models automatically from existing resources of information, so tools such as our own can be leveraged by protocol developers. Translating academic research to real-world utilities is always challenging, and at NDS2, we are very excited about how techniques like NLP can help us do exactly that.
More details are available in our paper, “Automated Attack Synthesis by Extracting Finite State Machines from Protocol Specification Documents’’, which appeared in IEEE Security and Privacy 2022. The code is open-source and available here. Read more about automated attack synthesis using KORG in this post.
This work was a collaboration with Maria Leonor Pacheco and her advisor Dan Goldwasser from Purdue University, as well as myself, my lab-mate Ben Weintraub, and our advisor Cristina Nita-Rotaru at NDS2. Maria is a Postdoctoral Researcher at Microsoft Research NYC and will become an Assistant Professor at CU Boulder in Fall 2023.
Max von Hippel is a 4th year PhD student in computer science in the NDS2 Lab at Northeastern University, advised by Dr. Cristina Nita-Rotaru. His research focuses on the automatic synthesis of attacks against protocols.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.