

A lot of Cloudflare’s technology is well documented. For example, how we handle traffic between the eyeballs (clients) and our servers has been discussed many times on the Cloudflare blog: ‘A brief primer on anycast (2011)‘, ‘Load Balancing without Load Balancers (2013)‘, ‘Path MTU discovery in practice (2015)‘, ’Cloudflare’s edge load balancer (2020)‘, ‘How we fixed the BSD socket API (2022)‘.
However, we have rarely talked about the second part of our networking setup — how our servers fetch the content from the Internet. In this blog post, we’re going to cover this gap. We’ll discuss how we manage Cloudflare IP addresses used to retrieve the data from the Internet, how our egress network design has evolved and how we optimized it for the best use of available IP space.
Brace yourself. We have a lot to cover.
Terminology first!
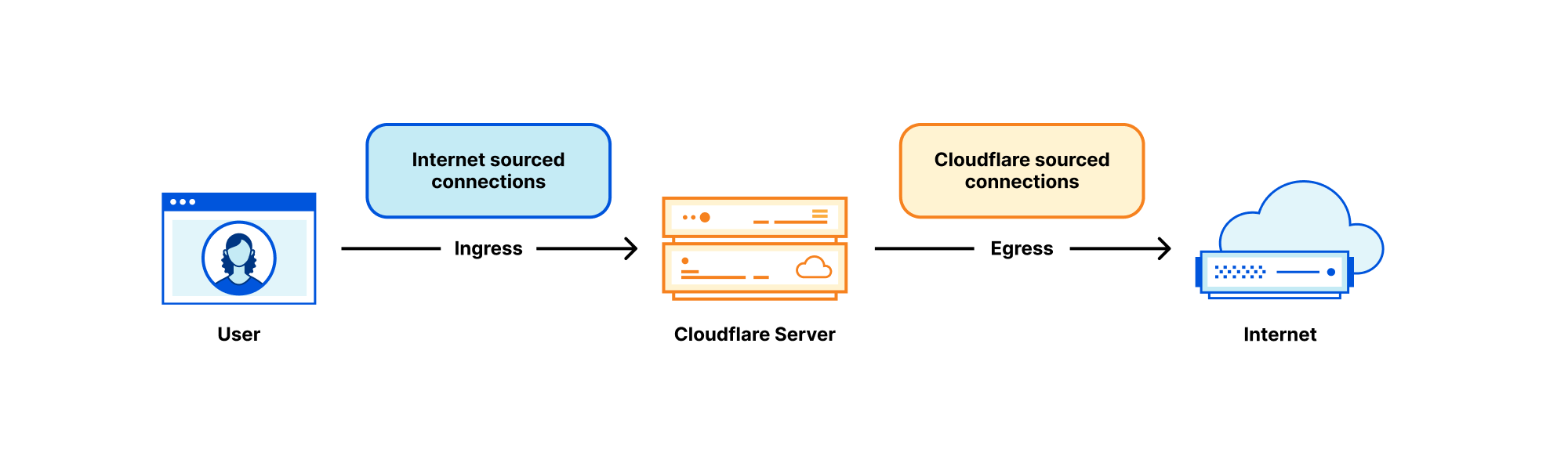
Each Cloudflare server deals with many kinds of networking traffic, but two rough categories stand out:
- Internet sourced traffic — Inbound connections initiated by eyeball to our servers. In the context of this blog post, we’ll call these ‘ingress connections’.
- Cloudflare sourced traffic — Outgoing connections initiated by our servers to other hosts on the Internet. For brevity, we’ll call these ‘egress connections’.
The egress part, while rarely discussed in this blog post, is critical for our operation. Our servers must initiate outgoing connections to get their jobs done! For example:
- In our Content Delivery Network (CDN) product, before the content is cached, it’s fetched from the origin servers. See ‘Pingora, the proxy that connects Cloudflare to the Internet (2022)‘, Argo and Tiered Cache.
- For the Spectrum product, each ingress TCP connection results in one egress connection.
- Workers often run multiple subrequests to construct an HTTP response. Some of them might be querying servers to the Internet.
- We also operate client-facing forward proxy products — like WARP and Cloudflare Gateway. These proxies deal with eyeball connections destined to the Internet. Our servers need to establish connections to the Internet on behalf of our users.
And so on.
Anycast on ingress, unicast on egress
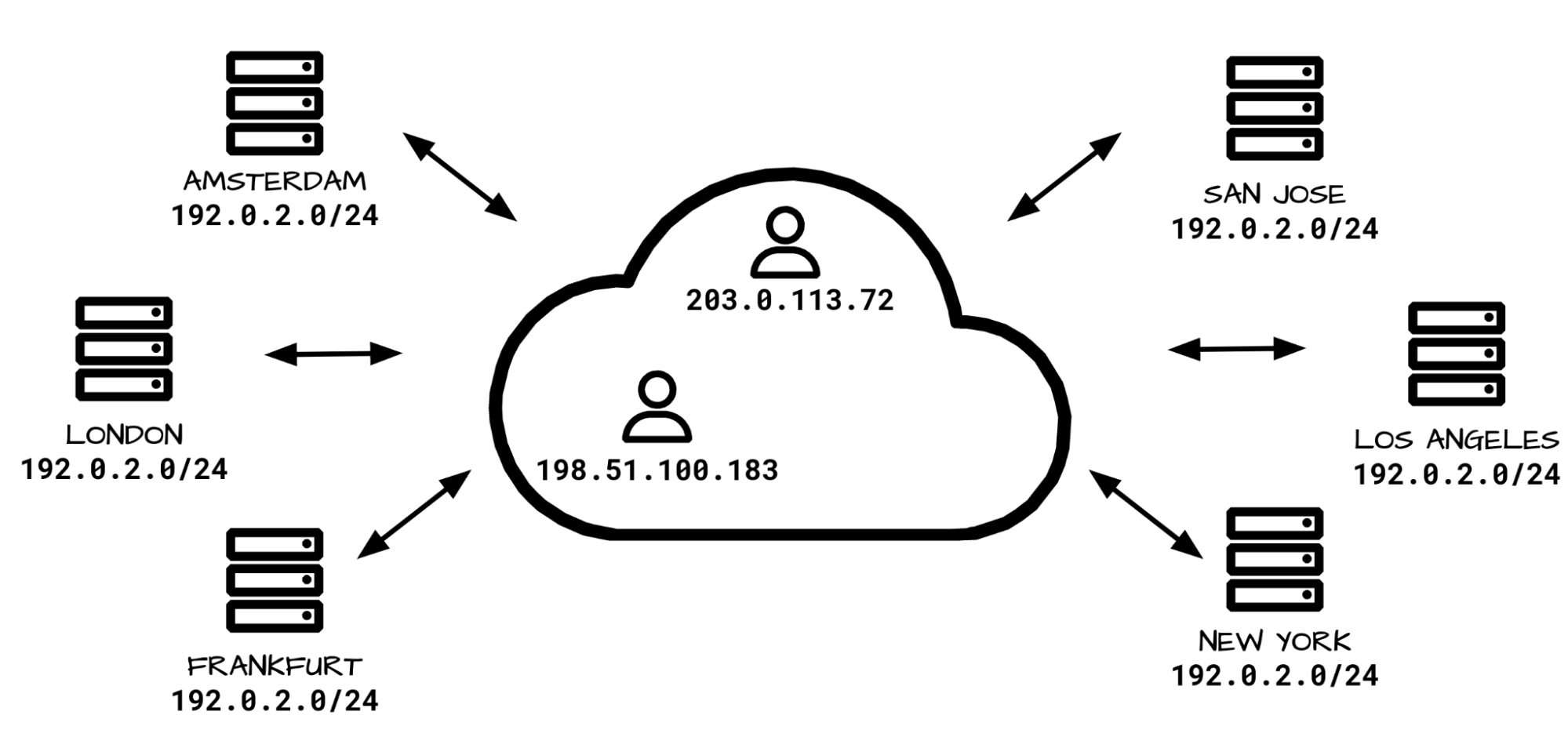
Our ingress network architecture is very different from the egress one. On ingress, the connections sourced from the Internet are handled exclusively by our anycast IP ranges. Anycast is a technology where each of our data centres ‘announces’ and can handle the same IP ranges. With many destinations possible, how does the Internet know where to route the packets? Well, the eyeball packets are routed towards the closest data centre based on Internet BGP metrics, often it’s also geographically the closest one. Usually, the Border Gateway Policy (BGP) routes don’t change much, and each eyeball IP can be expected to be routed to a single data centre.
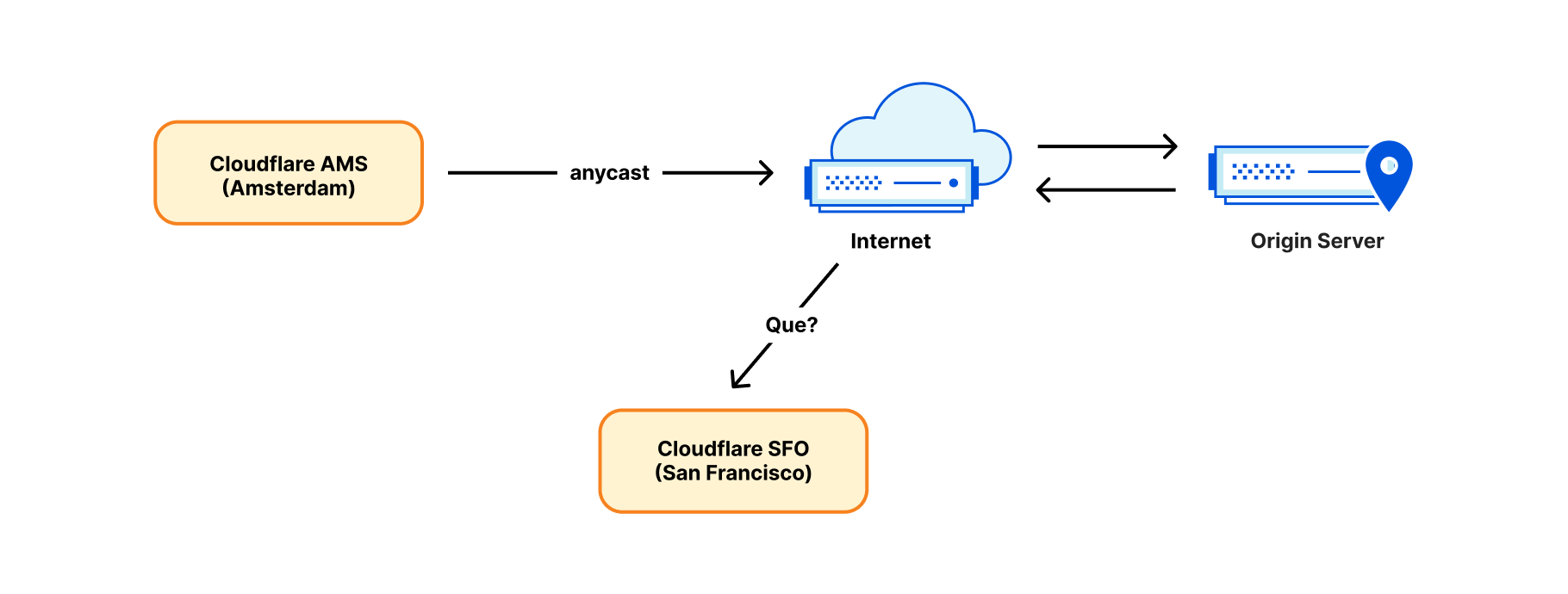
However, while anycast works well in the ingress direction, it can’t operate on egress. Establishing an outgoing connection from an anycast IP won’t work. Consider the response packet. It’s likely to be routed back to the wrong place — a data centre geographically closest to the sender, not necessarily the source data centre!
For this reason, until recently, we established outgoing connections in a straightforward and conventional way — each server was given its own unicast IP address. ‘Unicast IP’ means there is only one server using that address in the world. Return packets will work just fine and get back exactly to the right server identified by the unicast IP.
Segmenting traffic based on egress IP
Originally connections sourced by Cloudflare were mostly HTTP fetches going to origin servers on the Internet. As our product line grew, so did the variety of traffic. The most notable example is our WARP app. For WARP, our servers operate a forward proxy and handle the traffic sourced by end-user devices. It’s done without the same degree of intermediation as in our CDN product. This creates a problem. Third-party servers on the Internet — like the origin servers — must be able to distinguish between connections coming from Cloudflare services and our WARP users. Such traffic segmentation is traditionally done by using different IP ranges for different traffic types (although recently we introduced more robust techniques like Authenticated Origin Pulls).
To work around the trusted vs untrusted traffic pool differentiation problem, we added an untrusted WARP IP address to each of our servers:
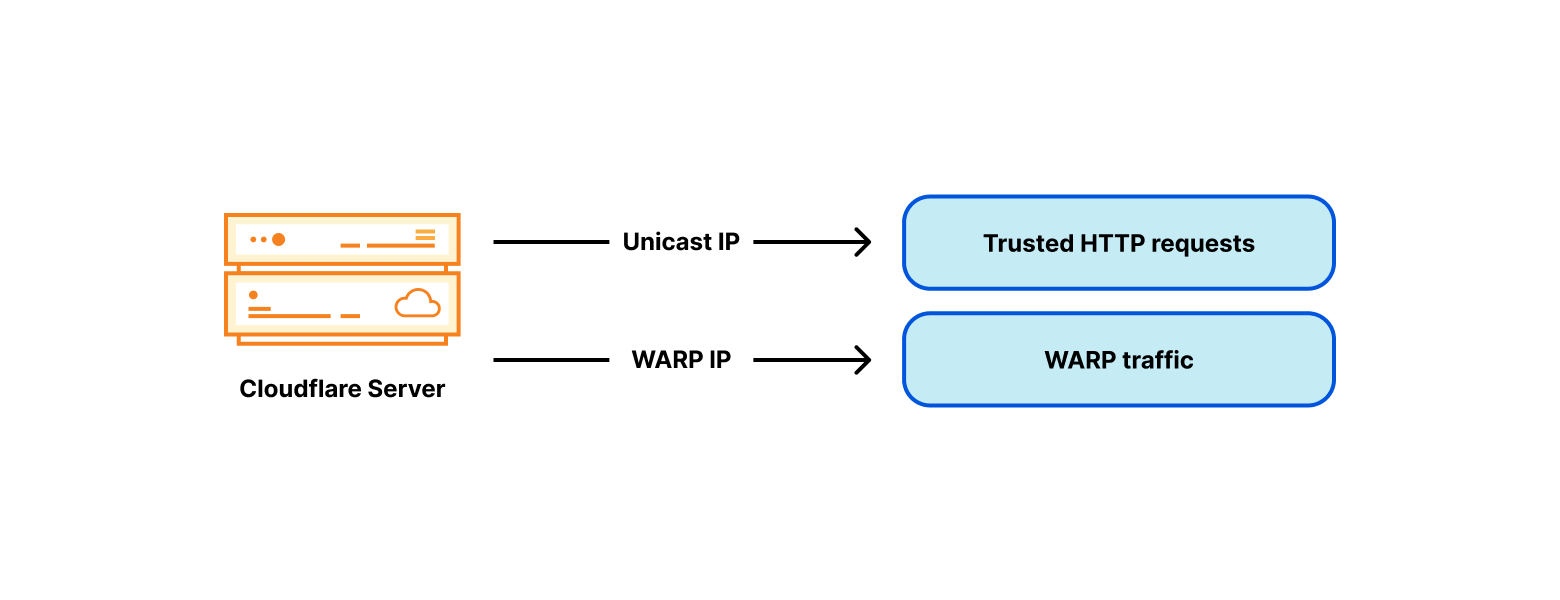
Country code tagged egress IP addresses
It quickly became apparent that trusted vs untrusted weren’t the only tags needed. For WARP service we also need country code tags. For example, United Kingdom-based WARP users expect the bbc.com website to just work. However, the BBC restricts many of its services to people just in the UK.
It does this by geofencing — using a database mapping public IP addresses to economies, and allowing only the UK ones. Geofencing is widespread on today’s Internet. To avoid geofencing issues, we need to choose specific egress addresses tagged with an appropriate country code, depending on the WARP user location. Like many other parties on the Internet, we tag our egress IP space with country codes and publish it as a geofeed (like this one). Notice, the published geofeed is just data. The fact that an IP is tagged as say UK does not mean it is served from the UK, it just means the operator wants it to be geolocated to the UK. Like many things on the Internet, it is based on trust.
Notice, at this point we have three independent geographical tags:
- The country code tag of the WARP user — the eyeball connecting IP.
- The location of the data centre the eyeball connected to.
- The country code tag of the egressing IP.
For the best service, we want to choose the egressing IP so that its country code tag matches the economy from the eyeball IP. But egressing from a specific country code tagged IP is challenging — our data centres serve users from all over the world, potentially from many economies! Remember, due to anycast, we don’t directly control the ingress routing. Internet geography doesn’t always match physical geography. For example, our London data centre receives traffic not only from users in the United Kingdom, but also from Ireland and Saudi Arabia. As a result, our servers in London need many WARP egress addresses associated with many economies:
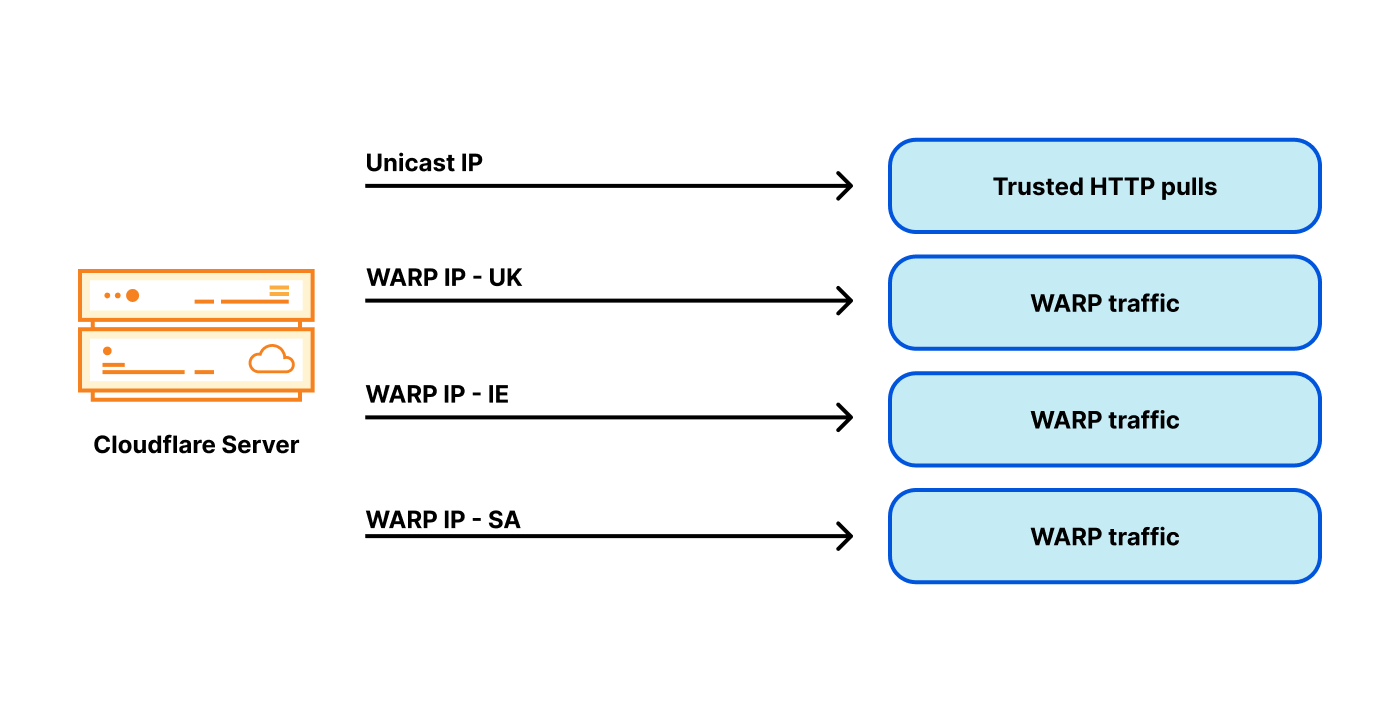
Can you see where this is going? The problem space just explodes! Instead of having one or two egress IP addresses for each server, now we require dozens, and IPv4 addresses aren’t cheap. With this design, we need many addresses per server, and we operate thousands of servers. This architecture becomes very expensive.
Is anycast a problem?
Let me recap: With anycast ingress, we don’t control which data centre the user is routed to. Therefore, each of our data centres must be able to egress from an address with any conceivable tag. Inside the data centre, we also don’t control which server the connection is routed to. There are potentially many tags, many data centres, and many servers inside a data centre.
Maybe the problem is the ingress architecture? Perhaps it’s better to use a traditional networking design where a specific eyeball is routed with DNS to a specific data centre or even a server?
That’s one way of thinking, but we decided against it. We like our anycast on ingress. It brings us many advantages:
- Performance: With anycast, by definition, the eyeball is routed to the closest (by BGP metrics) data centre. This is usually the fastest data centre for a given user.
- Automatic failover: If one of our data centres becomes unavailable, the traffic will be instantly, automatically rerouted to the next best place.
- DDoS resilience: During a denial-of-service attack or a traffic spike, the load is automatically balanced across many data centres, significantly reducing the impact.
- Uniform software: The functionality of every data centre and of every server inside a data centre is identical. We use the same software stack on all the servers around the world. Each machine can perform any action, for any product. This enables easy debugging and good scalability.
For these reasons, we’d like to keep the anycast on ingress. We decided to solve the issue of egress address cardinality in some other way.
Solving a million-dollar problem
Out of the thousands of servers we operate, every single one should be able to use an egress IP with any of the possible tags. It’s easiest to explain our solution by first showing two extreme designs.
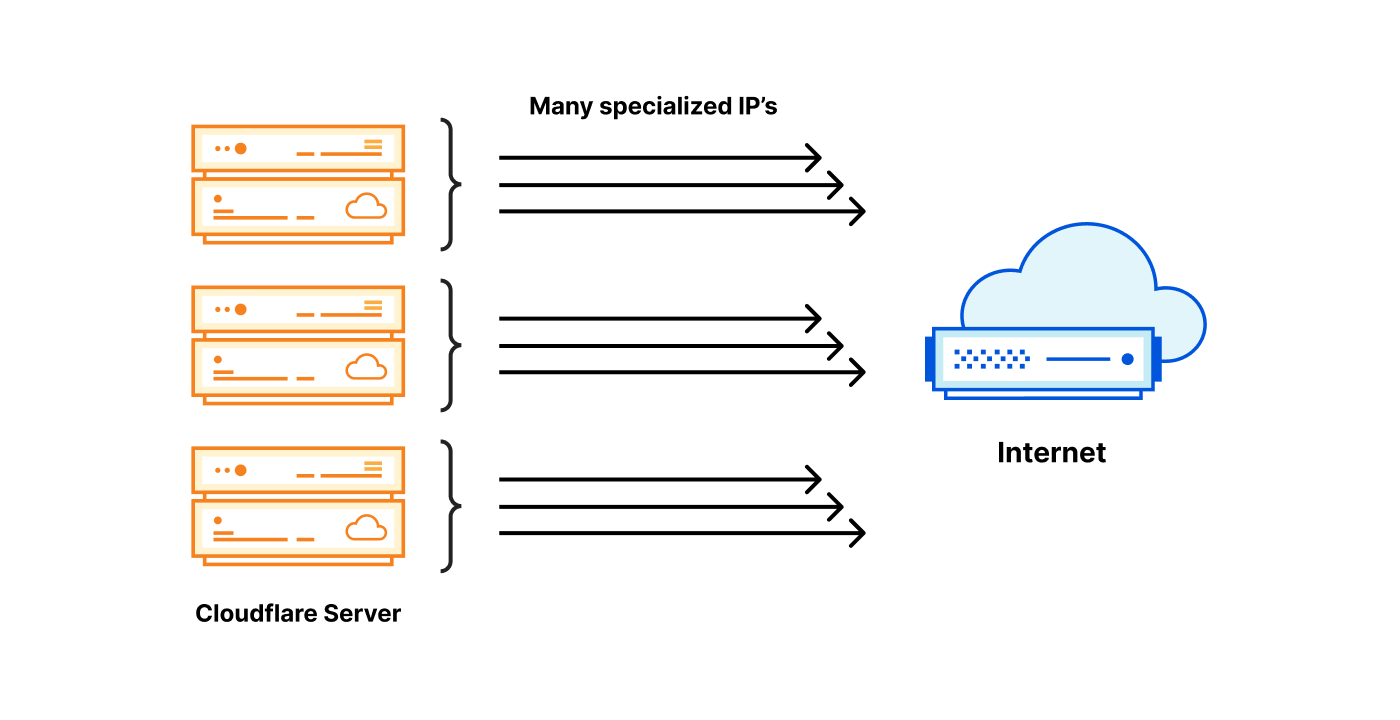
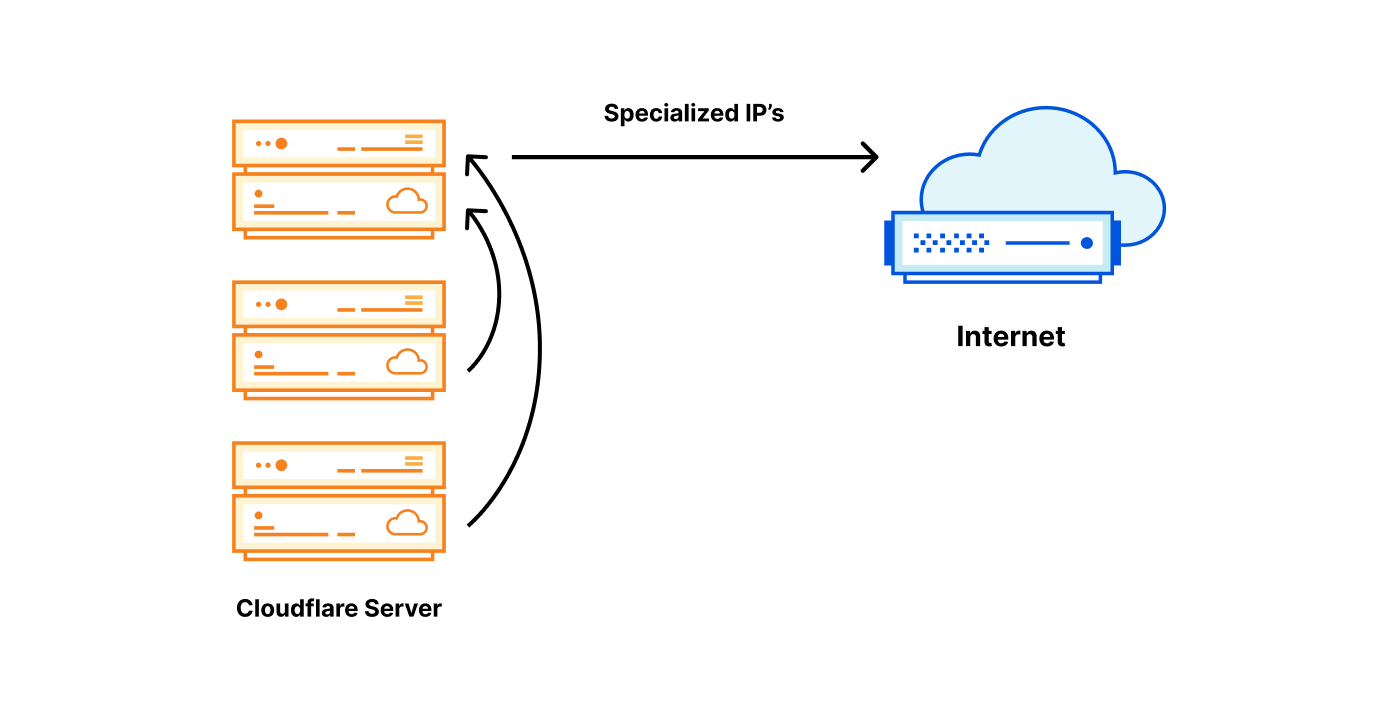
Both options have pros and cons:
| Specialized IP on every server | Specialized IP on one server |
| Super expensive $$$, every server needs many IP addresses. | Cheap $, only one specialized IP needed for a tag. |
| Egress always local — fast | Egress almost always forwarded — slow |
| Excellent reliability — every server is independent | Poor reliability — introduced chokepoints |
There’s a third way
We’ve been thinking hard about this problem. Frankly, the first extreme option of having every needed IP available locally on every Cloudflare server is not totally unworkable. This is, roughly, what we were able to pull off for IPv6. With IPv6, access to the large needed IP space is not a problem.
However, in IPv4 neither option is acceptable. The first offers fast and reliable egress but requires great cost — the IPv4 addresses needed are expensive. The second option uses the smallest possible IP space, so it’s cheap, but compromises on performance and reliability.
The solution we devised is a compromise between the extremes. The rough idea is to change the assignment unit. Instead of assigning one /32 IPv4 address for each server, we devised a method of assigning a /32 IP per data centre, and then sharing it among physical servers.
| Specialized IP on every server | Specialized IP per data centre | Specialized IP on one server |
| Super expensive $$$ | Reasonably priced $$ | Cheap $ |
| Egress always local — fast | Egress always local — fast | Egress almost always forwarded — slow |
| Excellent reliability — every server is independent | Excellent reliability — every server is independent | Poor reliability — many choke points |
Sharing an IP inside data centre
The idea of sharing an IP among servers is not new. Traditionally this can be achieved by source-NAT on a router. Sadly, the sheer number of egress IPs we need and the size of our operation, prevent us from relying on stateful firewall / NAT at the router level. We also dislike shared state, so we’re not fans of distributed NAT installations.
What we chose instead, is splitting an egress IP across servers by a port range. For a given egress IP, each server owns a small portion of available source ports — a port slice.
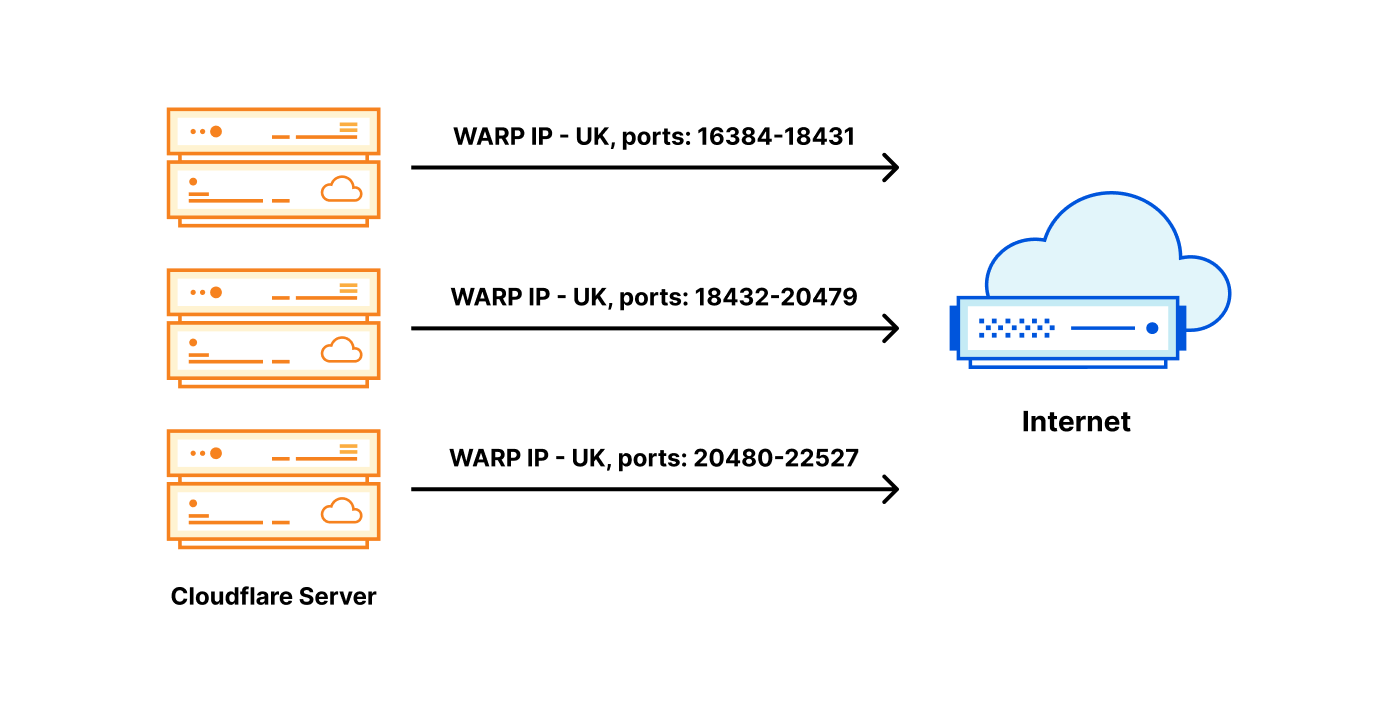
When return packets arrive from the Internet, we have to route them back to the correct machine. For this task, we’ve customized ‘Unimog’ — our L4 XDP-based load balancer — (‘Unimog, Cloudflare’s load balancer (2020)‘) and it’s working flawlessly.
With a port slice of say 2,048 ports, we can share one IP among 31 servers. However, there is always a possibility of running out of ports. To address this, we’ve worked hard to be able to reuse the egress ports efficiently. See the ‘How to stop running out of ports (2022)‘, ‘How to share IPv4 addresses (2022)‘ and our Cloudflare.TV segment.
This is pretty much it. Each server is aware of which IP addresses and port slices it owns. For inbound routing, Unimog inspects the ports and dispatches the packets to the appropriate machines.
Sharing a subnet between data centres
This is not the end of the story though, we haven’t discussed how we can route a single /32 address into a data centre. Traditionally, in the public Internet, it’s only possible to route subnets with a granularity of a /24 or 256 IP addresses. In our case, this would lead to a great waste of IP space.
To solve this problem and improve the use of our IP space, we deployed our egress ranges as… anycast! With that in place, we customized Unimog and taught it to forward the packets over our backbone network to the right data centre. Unimog maintains a database like this:
198.51.100.1 — forward to LHR
198.51.100.2 — forward to CDG
198.51.100.3 — forward to MAN
...With this design, it doesn’t matter to which data centre return packets are delivered. Unimog can always fix it and forward the data to the right place. Basically, while at the BGP layer, we are using anycast, due to our design, semantically an IP identifies a data centre and an IP and port range identify a specific machine. It behaves almost like a unicast.
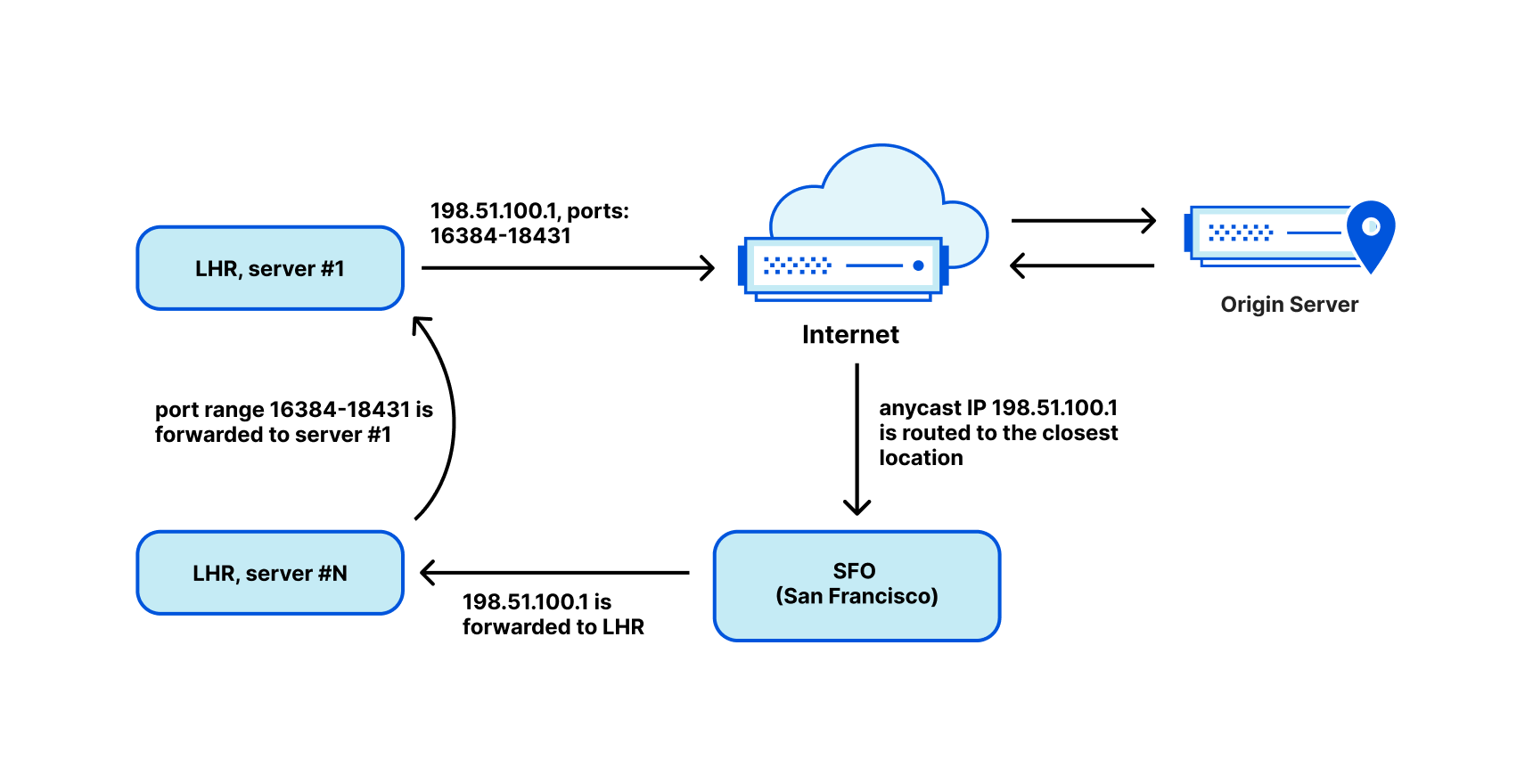
We call this technology stack ‘soft-unicast’ and it feels magical. It’s like we did unicast in software over anycast in the BGP layer.
Soft-unicast is indistinguishable from magic
With this setup we can achieve significant benefits:
- We are able to share a /32 egress IP among many servers.
- We can spread a single subnet across many data centres, and change it easily on the fly. This allows us to fully use our egress IPv4 ranges.
- We can group similar IP addresses together. For example, all the IP addresses tagged with the ‘UK’ tag might form a single continuous range. This reduces the size of the published geofeed.
- It’s easy for us to onboard new egress IP ranges, like customer IPs. This is useful for some of our products, like Cloudflare Zero Trust.
All this is done at a sensible cost, at no loss to performance and reliability:
- Typically, the user is able to egress directly from the closest data centre, providing the best possible performance.
- Depending on the actual needs we can allocate or release the IP addresses. This gives us flexibility with IP cost management; we don’t need to overspend upfront.
- Since we operate multiple egress IP addresses in different locations, the reliability is not compromised.
The true location of our IP addresses is ‘the cloud’
While soft-unicast allows us to gain great efficiency, we’ve hit some issues. Sometimes we get the question ‘Where does this IP physically exist?’. But it doesn’t have an answer! Our egress IPs don’t exist physically anywhere. From a BGP standpoint, our egress ranges are anycast, so they live everywhere. Logically each address is used in one data centre at a time, but we can move it around on demand.
Content Delivery Networks misdirect users
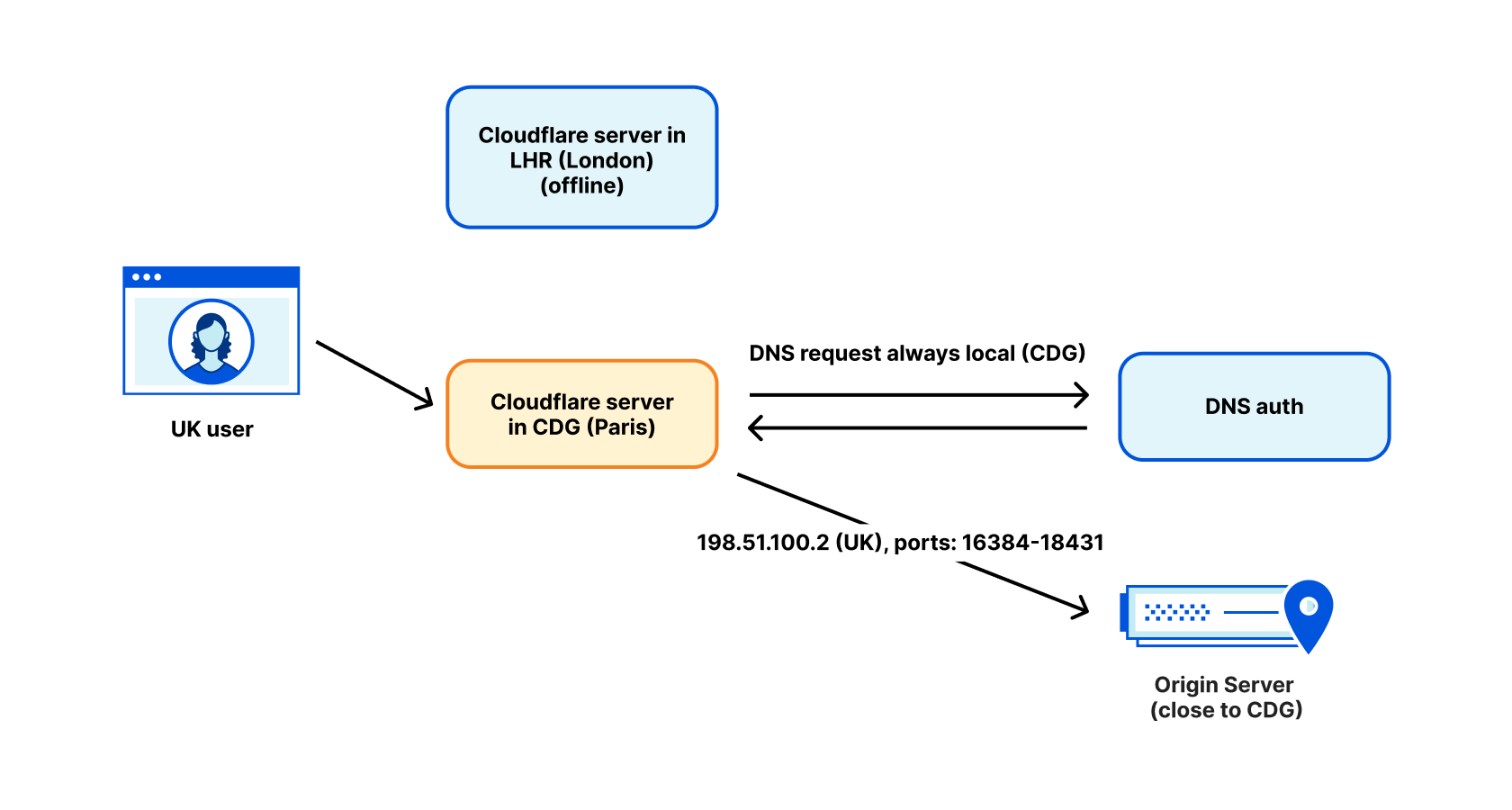
As another example of problems, here’s one issue we’ve hit with third-party CDNs. As we mentioned before, there are three country code tags in our pipeline:
- The country code tag of IP eyeball is connecting from.
- The location of our data centre.
- The country code tag of the IP addresses we chose for the egress connections.
The fact that our egress address is tagged as ‘UK’ doesn’t always mean it actually is being used in the UK. We’ve had cases when a UK-tagged WARP user, due to the maintenance of our LHR data centre, was routed to Paris. A popular CDN performed a reverse lookup of our egress IP, found it tagged as ‘UK’, and directed the user to a London CDN server. This is generally OK… but we actually egressed from Paris at the time. This user ended up routing packets from their home in the UK, to Paris, and back to the UK. This is bad for performance.
We address this issue by performing DNS requests in the egressing data centre. For DNS we use IP addresses tagged with the location of the data centre, not the intended geolocation for the user. This generally fixes the problem, but sadly, there are still some exceptions.
The future is here
Our 2021 experiments with Addressing Agility proved we have plenty of opportunity to innovate with the addressing of the ingress. Soft-unicast shows us we can achieve great flexibility and density on the egress side.
With each new product, the number of tags we need on the egress grows — from traffic trustworthiness, and product category, to geolocation. As the pool of usable IPv4 addresses shrinks, we can be sure there will be more innovation in the space. Soft-unicast is our solution, but for sure it’s not our last development.
For now though, it seems like we’re moving away from traditional unicast. Our egress IPs really don’t exist in a fixed place anymore, and some of our servers don’t even own a true unicast IP nowadays.
After fruitful encounters with such diverse topics as programming industrial robots, distributed K/V databases and web server scalability, Marek Majkowski has settled on network programming as his main area of interest. Currently working at Cloudflare, Marek has authored many critical systems, most notably the DDoS mitigation pipeline.
This post was originally published on the Cloudflare Blog.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
I’ve never read such a proud accounting of how one breaks the internet. You should be ashamed of yourselves but I know cloudflare has no shame. It only has profit motive and if the norms of the internet have to fall and everything centralizing in a few corporations, so be it.