

End-to-end congestion control methods, such as TCP and QUIC, are the main ways of avoiding congestion on the Internet, and much research has gone into improving the latency performance of TCP. In a recent paper, we at Domos, describe a fundamental limitation of these methods — they cannot avoid latency spikes.
Our paper addresses an awkward problem that is obvious to a part of the community (hello control theory people), but which many researchers and engineers frequently either ignore or overlook. The initial motivation for the work was a recent workshop at the Internet Architecture Board (IAB). During the workshop, a common misunderstanding (even among experts in the field) became apparent — that end-to-end congestion control can deliver reliable low latency if we just tune it correctly.
That is not true for networks where link capacity can change rapidly, such as Wi-Fi and 5G.
Two recent survey papers (Survey 1 and Survey 2) both state that large variations in capacity are one of the main problems for congestion control in 5G networks. Yet, there are no references to fundamental limitations in either survey.
TCP, bufferbloat, and the promise of a responsive Internet
Bufferbloat has been identified as a common source of latency on the Internet. Nichols and Van Jacobson describe Bufferbloat as ‘unnecessary queuing’. Bufferbloat is caused by poor congestion signalling leading to a ‘standing queue’ at bottleneck interfaces.
A standing queue adds latency without improving throughput and is therefore just wasting everyone’s time. Lots of progress has been made on reducing bufferbloat in the Internet, perhaps most notably by Dave Taht, Toke Høiland-Jørgensen, Jim Gettys, and Kathleen Nichols. In the latest iOS release, there is a tool called RPM, which is designed to measure and detect bufferbloat, and browser tools exist as well.
Removing unnecessary queuing is a win-win. However, to get close to the ideal speed-of-light Internet, removing standing queues is not enough. Transient queues, often called ‘good queues’ because they help improve link utilization, can be large enough to contribute significantly to performance problems.
How good is TCP latency under perfect conditions?
In the paper, we model the best possible case for an end-to-end congestion controller and work out how much latency we’d see on the bottleneck link if its capacity is suddenly reduced. The mathematics is simple, and we can compute the peak latency using the factor of capacity change (1/r) and how much time it takes to send a signal from the point of congestion to the traffic source (d). ‘d’ depends on the speed of light. One trip around the earth at the speed of light takes 133 milliseconds, so the speed of light is significant in these calculations. As we can see in Figure 3, the queuing latency can grow to several hundred milliseconds for values of C and d that are not uncommon on the Internet.
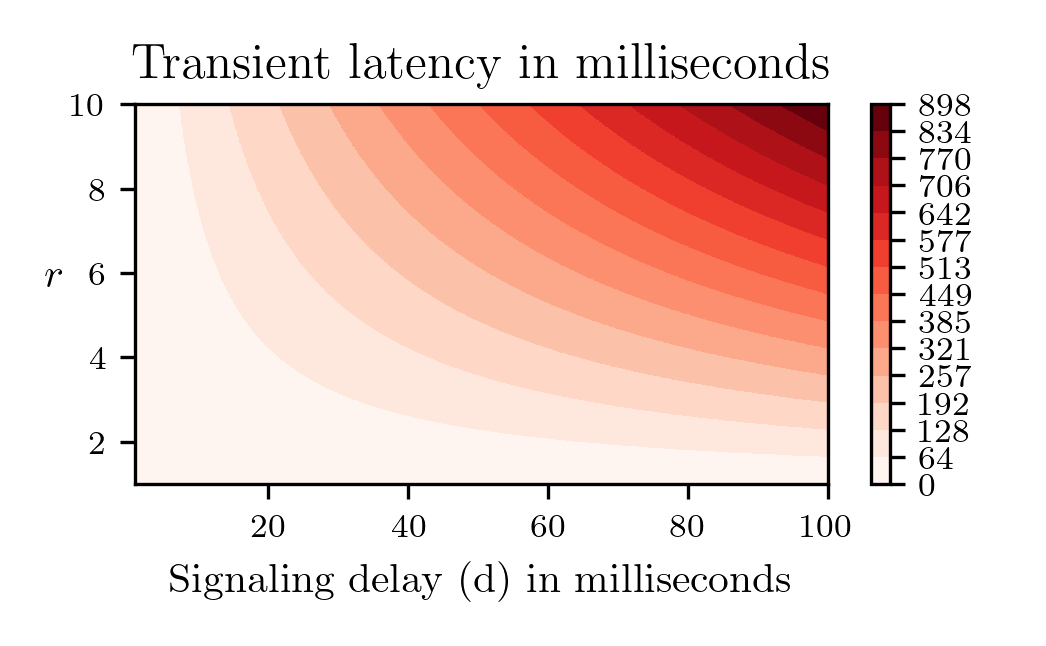
A key point is that this is the theoretical optimum for any and all end-to-end congestion control algorithms. The results are valid for all versions of TCP, QUIC, adaptive bitrate streaming methods, and all other end-to-end congestion control schemes you can possibly think of. Congestion signalling methods cannot work around this problem either, so our analysis is also valid for Explicit Congestion Notification methods such as Low Latency Low Loss Scalable Throughput (L4S).
How can latency spikes be avoided?
We have concluded that end-to-end congestion control alone is not enough to provide the reliable low-latency Internet that 5G marketers have promised us. What are our other options?
We have come up with a list of solutions that can help us out in different scenarios:
- See the future. If a congestion controller can react before capacity is reduced, then peak delays are smaller (this is equivalent to reducing d). This might be possible for cases where capacity drops are a result of things moving around.
- Underutilize the link. If we use the link at 10% capacity, then a capacity drop to 1/10th is not noticed. This is a good solution if the bandwidth is cheap enough, but it is expensive to build networks that are 10 times as big as they need to be!
- Treat traffic differently. This is like underutilization, but smarter. The idea is to underutilize the link, but only for traffic that is latency sensitive. Never fill more than 1/10th or 1/20th of the capacity with time-sensitive traffic, and suddenly you can handle large capacity drops. The rest of the link can be filled with traffic that is not as latency sensitive. The caveat is that when the capacity drops, the latency-sensitive traffic must be given priority on the link until capacity bounces back up. If this is handled at the point of congestion, then we can have the best of both worlds.
- Link diversification. If the same traffic is sent over more than one link, then the end-to-end connection can be made much more reliable because the chance of both links reducing capacity at the same time is small (assuming they are not correlated!).
I will leave you with a question: Are we trying to make end-to-end congestion control work for cases where it can’t possibly work? If so, then accepting the limitation we describe here is a necessary step towards making the reliable low-latency Internet a reality.
Bjørn Ivar Teigen is Head of Research at Domos, and a PhD candidate at the University of Oslo. His research interests are in queuing theory, distributed systems, and Machine Learning with applications in modelling and optimizing real-world networks.
Discuss on Hacker NewsThe views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Re your pt 3, I would have called out the potential of fair queuing and in running your latency sensitive flows at , say, 1/10th the rate of the capacity seeking ones. This is essentially the optimum we have today with qdiscs like fq-codel and cake, and works very well with modern day lower bitrate voip, request/response, and videoconferencing.
Aside from that I agree with your main points and loved the heatmap. Thx for the cite, too!
There’s been promising work here to make 5G, WiFi and Starlink behave better at the point of congestion:
https://forum.openwrt.org/t/cake-w-adaptive-bandwidth/108848/
And this also, being used in google’s wifi products, leveraging even more of kathie nichol’s later work on these subjects.
https://chromium.googlesource.com/chromiumos/third_party/kernel/+/refs/heads/stabilize-quickfix-13310.76.B-chromeos-4.14-gw/net/sched/sch_arl.c
How can I reproduce these simulations? What link models are you using? How can I model the latency and delay variations of the links?
@Dave
Thanks for the feedback! Agree with your points as well, fq-codel and cake are both great and deserve more deployment.
The cake with adaptive bandwidth stuff is interesting. Have seen the discussions but haven’t delved into the detail yet.
@Christian
The results are based on a first-principles analysis, not on simulations. In the paper (https://arxiv.org/abs/2111.00488) I explain how the results are derived. If you have any more questions feel free to contact me at bjorn@domos.no.
Re pt 1: Signalling beforehand is very possible with heavily scheduled links (in rough order of possibility), like starlink, wifi, lte, cable and gpon. Presently, for example, starlink is adjusting available bandwidth on a 15s interval, wifi is a function of stations * the needed txop size (waaay more complicated for mu-mimo).
Very interesting article, thanks! I’m an engineer for a cellular operator, where E2E congestion has historically struggled with the radio air interface volatility – e.g. available bandwidth to a terminal varying by an order of magnitude or more in under a second due to reduced SINR, fading, reflections etc. By the time the TCP server reacts the conditions have often changed – and the radio layers are busily doing their own retransmissions and transmission modifications (ARQ and HARQ). But these radio layer retransmissions are not visible to the transport layer, meaning the transport layer will retransmit segments that are already queued at the radio layers. So a ‘joined up’ approach between the radio and transport layers could mitigate that…also to note that radio schedulers transmit based on (1) the received signal strength of the user’s terminal, which is constantly signaled to the radio base station, and (2) the size of the user’s individual packet queue. Scheduler buffers per user may be allowed to build up to make best use of good signal strength when available, which may be another cause of bufferbloat. Thanks!
@Kevin Thanks for the interest! The issues you describe are very familiar from my experience working with WiFi. Seems like TCP was very much designed for wired links and the variable latency and bitrate of wireless really mess with some of the algorithms.
Interesting stuff, and lots of room for improvement!