

The last decade has seen a concerted effort to improve the performance and efficiency of networked systems. This has led to the development of several technologies, including kernel bypass libraries, Network Interface Cards (NICs) to which processing can be offloaded, and new kernel interfaces.
eBPF is one such technology that allows networked programs to run their logic in the Linux kernel, avoiding processing overheads due to the network stack and system call overheads. Many eBPF-based network functions, including load-balancers, firewalls, and network monitors, are used in production today.
However, eBPF has not seen similarly widespread adoption in other types of networked applications, such as web servers and databases. In this blog post, we argue that this gap stems from limitations in the current eBPF architecture — specifically, the kernel runtime, APIs, and compiler toolchain.
These limitations affect networked applications (and not network functions) because of important differences:
- Offloading strategies: They differ in how program logic needs to be split between userspace components and in-kernel components
- Runtime limitations: They differ in the type of processing they perform, and thus in the types of CPU instructions they can benefit from.
We had two goals in writing this blog post:
- To help developers reason about when and why eBPF-based offloading is likely to be beneficial.
- To highlight opportunities for improving eBPF so that a broader range of applications can take advantage of it.
These findings come from our observations shared in a study called ‘Demystifying Performance of eBPF Network Applications‘ published in the 3rd volume of Proceedings of The ACM on Networking (PACMNET).
Offloading strategy
While the data path of eBPF-based network functions runs entirely inside the kernel (with all logic implemented in eBPF), it is far less feasible to adopt the same approach for general networked applications. This is due to several restrictions, including verifier constraints (such as limits on program complexity and loops) as well as runtime limitations (for example, the inability to perform blocking operations such as file I/O or waiting for messages from other services). Below, we share two observations affecting the performance of programs.
Because of these implementation challenges, previous efforts have considered partial offloading, where only a portion of the program is run in the kernel. For example, BMC — an eBPF-based key-value store accelerator — demonstrated that caching hot data in the kernel could yield a 2.5x throughput improvement.
The question that BMC and others have not addressed is, how does this offloading affect the performance of program logic running in userspace? To answer that question, we ran BMC and used a workload that generated 60K requests per second. 55K of those requests hit the in-kernel cache, while the other 5K needed to be processed in userspace. We compared the performance of this setup to a baseline where BMC was not used.
Our results, depicted in Figure 1, show that the kernel-accelerated version increased latency for requests handled in userspace, which highlights a tradeoff between offloading and not. The answer depends on what percentage of traffic needs to go to userspace and how important that traffic is.
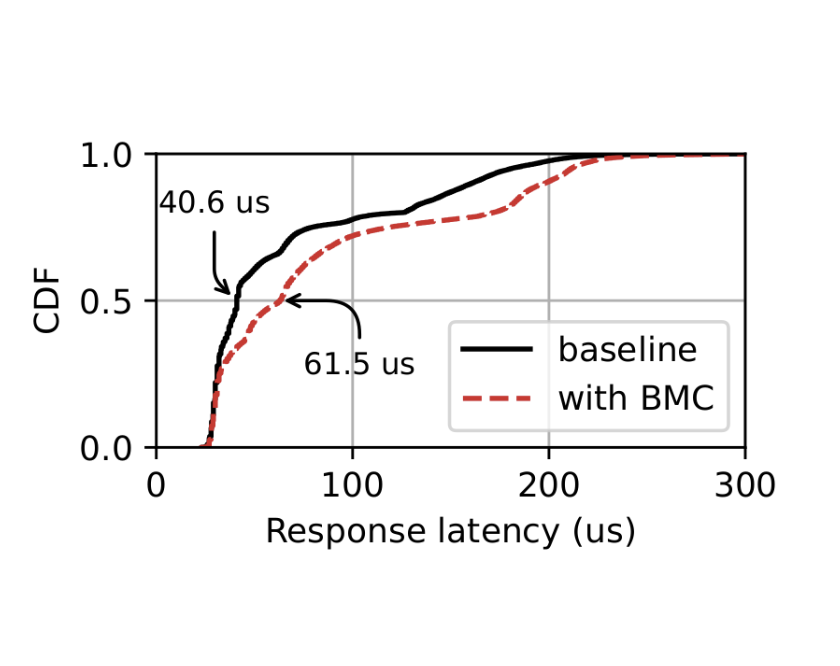
Figure 1 — Comparing the latency of traffic going to the user-space with and without in-kernel acceleration.
Our paper discusses some approaches to mitigate this problem. Many require changes to the eBPF runtime. For instance, one approach we discuss adds priority scheduling.
Moreover, when offloading an application, there are multiple hooks to select (Figure 2). For example, the program can attach to the NIC driver (the XDP hook) and operate on individual packets, which avoids context-switching, data-copying, and network stack processing. Some applications rely on the services of the transport protocol, like in-order packet delivery. These applications can attach to the socket layer (the SK_SKB hook) that is after the network stack processing and still benefit from offloading.
We noticed that invoking an eBPF program from different hooks imposed different latency costs. Invoking a program is the process of preparing a context object, jumping to the program, and, after the program returns, applying the action. Table 1 shows the values for XDP and SK_SKB. While invoking XDP takes only 38 ns, invoking a program attached to SK_SKB takes more than 1 µs, because it needs to interact with socket queues. As a result, programs attached to SK_SKB experience more overhead just in terms of invocation latency.
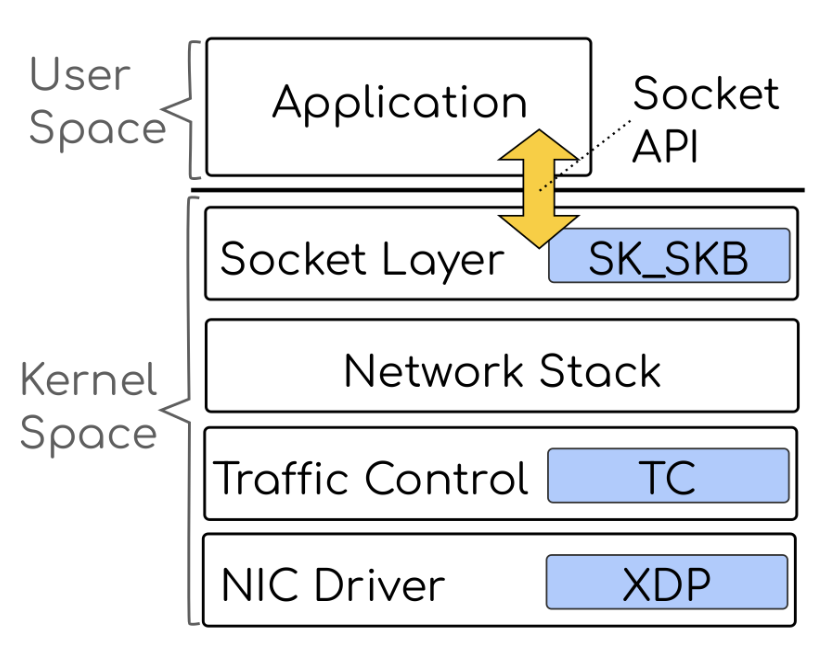
Figure 2 — Placement of eBPF hooks on the network path.
| Hook | Latency (ns) |
| XDP | 38 |
| SK_SKB | 1,350 |
On learning about the high invocation latency of SK_SKB hook, you might think that applications that rely on transport protocol services should not be offloaded. But we believe this highlights an opportunity to improve the eBPF runtime. With tighter integrations with network stack, these overheads may be reduced.
Limitations of the eBPF runtime
A program run by the eBPF runtime will always be slower than (or at best have the same performance as) native code run in userspace. This is because the eBPF runtime limits what instructions the program can use.
As an example, we benchmarked copying 1KB of data inside a kernel module and in an eBPF program (see Table 2). We observed that this operation takes 10x longer in eBPF because the eBPF Just-In-Time (JIT) compiler has emitted less efficient instructions. This means offloading a program that performs large memory copies will experience extra overhead compared to when it is running in userspace.
| Scenario | Time (ns) |
| Kernel module | 32 |
| eBPF | 340 |
This shows how important the eBPF JIT compiler is for application performance, and points to another way to improve runtime when offloading applications. However, making these changes is complex and needs closer coordination between the compiler and the eBPF JIT, which increases kernel complexity.
This post covers only part of the analysis in our paper. We encourage you to read the full study, and we welcome discussion on how the eBPF architecture could evolve to support a wider range of networked applications.
Farbod Shahinfar is a graduate student at Politecnico di Milano. He is interested in computer systems, focusing especially on the intersection of operating systems and data centre networks.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.