

APNIC’s core registry services are whois, Registration Data Access Protocol (RDAP), Resource Public Key Infrastructure (RPKI), Internet Routing Registry (IRR), and the Reverse Domain Name System (rDNS). The availability of these APNIC core services for Q3 2025 is shown in Table 1.
| Service | Q1 availability | Q2 availability | Q3 availability |
| whois and IRR | 99.991% | 99.996% | 99.999% |
| RDAP | 99.998% | 99.998% | 99.997% |
| RPKI | 99.999% | 99.983% | 99.994% |
| rDNS | 99.998% | 99.999% | 100% |
Cloudflare outage and its impact on APNIC core services
Cloudflare had a large outage on 18 November 2025, which they detailed in their post-mortem. While this is a Q4 incident, it’s worth mentioning in this post for timeliness.
These days, when a major cloud provider has an outage, the effects are widespread. In Q3, Cloudflare served an average of six trillion requests a day — roughly 20% of global web traffic.
APNIC uses Cloudflare’s global network to deliver content more quickly and to protect APNIC origin servers from bot traffic and other security threats. Among the core services listed in the availability table above, both RDAP and the RPKI Repository Data Protocol (RRDP) depend on Cloudflare.
For RDAP, APNIC uses Cloudflare’s load-balancing and response-caching features (see the blog post on the RDAP architecture for more details) to improve resilience and reduce latency.
For RRDP, which is inherently highly cacheable, Cloudflare’s caching further boosts performance and ensures the service remains accessible even during an outage or when maintenance is required on APNIC’s origin servers.
Incident response
During the Cloudflare outage on Tuesday, 18 November 2025, the RDAP and RPKI RRDP services began returning high error rates. Our internal monitoring alerted the on-call engineer, who then assembled the response team. From our various monitoring vantage points, we observed Cloudflare responses failing and then recovering in a pattern that closely matched the five-minute cycle of good and bad configuration data described in Cloudflare’s post-mortem.
Figure 1 shows the volume of 5xx HTTP status codes returned by the RDAP service. The two major peaks — the first from 21:53 to 22:08 (UTC +10) and the second from 22:43 to 22:48 (UTC +10) — were periods during which all requests from our global monitoring locations received error responses.
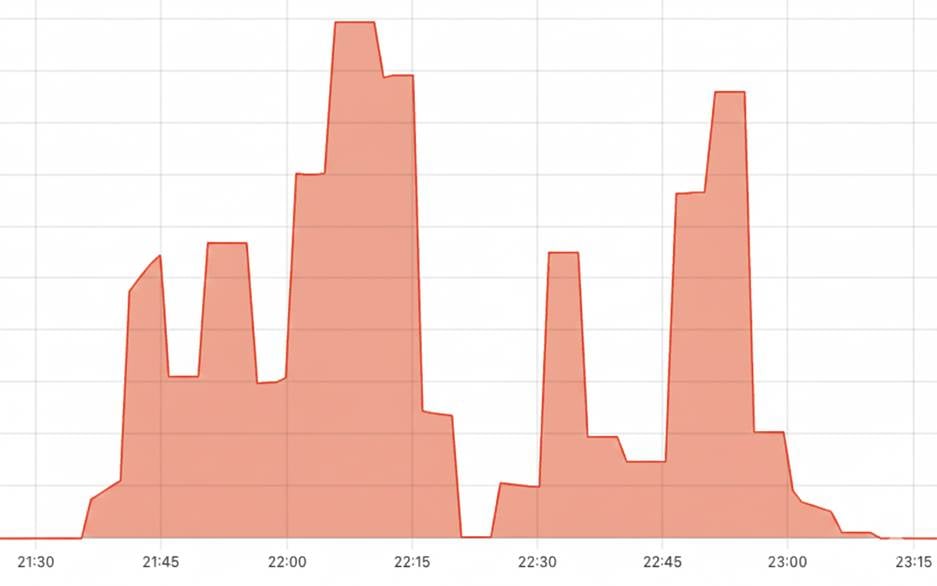
After monitoring the situation, we decided to update the DNS for the RRDP service to route clients directly to our on-premises servers, bypassing Cloudflare. This change was made at 22:41 (UTC +10) and restored normal operation for RRDP.
Although RPKI relying party software will generally fall back to rsync when RRDP is unavailable, reducing the operational impact, we still chose to bypass Cloudflare to ensure the service returned to a stable and reliable state as quickly as possible.
At 22:43 (UTC +10), we observed another five-minute period during which all monitored Cloudflare-proxied services returned errors. After this, error rates began to decline, and RDAP and other services recovered. Only minor issues were observed after 23:00 (UTC +10), and we formally closed the incident at 00:30 (UTC +10) on Wednesday, 19 November.
Lessons learned
Outages are always opportunities to learn and strengthen resilience. From this incident, we identified two key takeaways.
First, having documented and regularly practised steps to bypass Cloudflare for more of our services would reduce outage impact. While we have this in place for RRDP, we can improve documentation and failover practice for RDAP and other web services, enabling our response team to restore services quickly and confidently.
Second, APNIC’s status page, the primary channel for service health updates and outage announcements, should remain available during incidents. Currently, it is also proxied by Cloudflare and was affected during this outage. We plan to separate it further from our production infrastructure to ensure it stays online even when other services are impacted.
We will implement these improvements over the coming months, enhancing service reliability and reducing the impact of future disruptions.
This quarter’s measurements demonstrate that APNIC’s core registry services continue to maintain very high availability, even as the Internet’s operational environment grows more complex and interconnected. The Cloudflare outage was a timely reminder that external dependencies, even on highly reliable global platforms, can create cascading impacts. By strengthening our failover processes, improving the resilience of the status page, and continuing to invest in robust monitoring, APNIC will be better positioned to respond quickly, maintain service continuity, and support the community’s need for a stable, secure, and highly available registry.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.