

Digital communications systems always represent a collection of design tradeoffs. Maximizing one characteristic of a system may impair others, and various communications services may choose to optimize different performance parameters based on the intersection of these design decisions with the physical characteristics of the communications medium.
In this article, I’ll look at how TCP, the workhorse transport protocol of the Internet, interacts with the characteristics of the Starlink service.
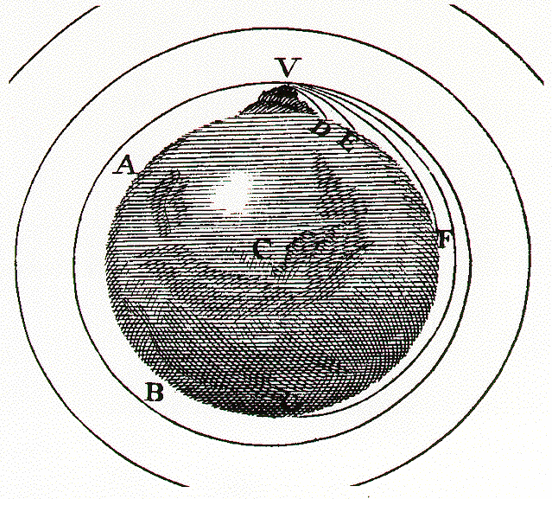
To start, it’s useful to recall a small item of Newtonian physics from 1687. On the surface of the Earth if you fire a projectile horizontally it will fall back to Earth due to the combination of the effects of the friction from the Earth’s atmosphere and the Earth’s gravitational force.
Assuming that the Earth has no friction-inducing atmosphere, if you fire this projectile horizontally fast enough it will not return to the Earth, but head into space. However, if you are high enough to clear various mountains that may be in the way, there is a critical velocity where the projectile will be captured by the Earth’s gravity and neither fall to the ground nor head out into space (Figure 1).
This orbital velocity at the surface of the Earth is some 40,320km/hour. The orbital velocity decreases with altitude, and at an altitude of 35,786km above the surface of the Earth, the orbital velocity of the projectile relative to a point on the surface of the spinning Earth is 0km/sec. This is the altitude of a geosynchronous equatorial orbit, where the orbiting object appears to sit at a fixed location in the sky.
Geosynchronous services
Geosynchronous satellites were the favoured approach for the first wave of satellite-based communications services. Each satellite could ‘cover’ an entire hemisphere. If the satellite was on the equatorial plane, then it was at a fixed location in the sky with respect to the Earth, allowing the use of a large antenna. These antennas were able to operate at a low Signal-to-Noise (SNR) ratio, allowing the signal modulation to use an encoding with a high density of discrete phase amplitude points, which lifted the capacity of the service.
All this must be offset against the less favourable aspects of a geosynchronous service. Consideration of crosstalk interference between adjacent satellites in geosynchronous orbits using the same radio frequencies resulted in international agreements that require a 2° spacing for geosynchronous satellites that use the same frequency, so this orbital slot is a limited resource that is limited to just 180 spacecraft if they all use K band (18 – 27Ghz) radio systems. At any point on the Earth, there is an upper bound to the signal capacity that can be received (and sent) using geosynchronous services.
Depending on whether the observer is on the equator directly beneath the satellite, or further away from this point, a geosynchronous orbit satellite is between 35,760 and 42,664km away, so a signal round trip time to the geosynchronous satellite and back will be between 238ms and 284ms in terms of signal propagation time.
In IP terms, that’s a round trip time of between 477 and 569ms and to this needs to be added the signal encoding and decoding times. In addition, there is a delay for the signal to be passed between the terrestrial endpoints and the satellite Earth stations. In practice, a round trip time of around two-thirds of a second (660ms) for Internet paths that include a geosynchronous satellite service is a common experience.
This extended latency means that the endpoints need to use large buffers to hold a copy of all the unacknowledged data, as is required by the TCP protocol. TCP is a feedback-governed protocol, using ACK pacing. The longer the round trip time the greater the lag in feedback, and the slower the response from endpoints to congestion or to available capacity. The congestion considerations lead to the common use of large buffers in the systems driving the satellite circuits, which can further exacerbate congestion-induced instability. In geosynchronous service contexts, individual TCP sessions are more prone to instability and experience longer recovery times following low events as compared to their terrestrial counterparts, when such counterparts exist.
Low Earth Orbit systems
A potential response to the drawbacks of geosynchronous satellites is to bring the satellite closer to Earth. This approach has several benefits. The Earth’s spinning iron core generates a magnetic field, which traps energetically charged solar particles and redirects them through what is called the ‘Van Allen Belt’, thus deflecting solar radiation. Not only does this allow the Earth to retain its atmosphere, but it also protects the electronics of orbiting satellites that use an orbital altitude below 2,000km or so from the worst effects of solar radiation (such as the recent solar storms). It’s also far cheaper to launch satellites into a low Earth orbit, and these days SpaceX can do so using reusable rocket boosters.
The reduced distance between the Earth and the orbiting satellite reduces the latency in sending a signal to the satellite and back, which can improve the efficiency of the end-to-end packet transport protocols that include such satellite circuits.
This group of orbital altitudes, from some 160km to 2,000km, are collectively termed Low Earth Orbit (LEOs). The objective here is to keep the satellite’s orbit high enough to prevent it from slowing down by grazing the upper parts of the Earth’s ionosphere, but not so high that it loses the radiation protection afforded by the inner Van Allen belt. At a height of 550km, the minimum signal propagation delay to reach the satellite and back from the surface of the Earth is just 3.7ms.
But all of this comes with some different issues. At a height of 550km an orbiting satellite can only be seen by a small part of the Earth. If the minimum effective elevation to establish communication is 25 degrees of elevation above the horizon, then the satellite’s footprint is a circle with a radius of 940km, or a circle of area 2M km2 (lower angles of elevation are possible but the longer path segment through the Earth’s atmosphere decreases the SNR, compromising the available signal capacity as well as increasing the total path delay).
To provide continuous service to any point on the Earth’s surface (510.1M km2) the minimum number of orbiting satellites is 500. This use of a constellation of satellites implies that an LEO satellite-based service is not a simple case of sending a signal to a fixed point in the sky and having that single satellite mirror that signal down to some other Earth location. A continuous LEO satellite service needs to hop across a continual sequence of satellites as they pass overhead and switch the virtual circuit path across to successive satellites as they come into view of both the end user and the user’s designated Earth station.
At an altitude of 550km, an orbiting satellite is moving with a relative speed of 27,000km/hour relative to a point on the Earth’s surface and passes across the sky from horizon to horizon in under five minutes. This has some implications for the design of the radio component of the service. If the satellite constellation is large enough, then the satellites are close enough to each other that there is no need to use larger dish antennae that require some mechanized steering arrangement that tracks individual satellites in their path across the sky, but this itself is not without its downside.
An individual signal carrier might be initially acquired as a weak signal (in relative terms), increases in strength as the satellite’s radio transponder and the Earth antenna move into alignment, and weakens again as the satellite moves on. Starlink’s antennae use a phased array arrangement using a grid of smaller antennae on a planar surface. This allows the antenna to be electronically steered by altering the phase difference between each of the antennae in the grid. Even so, this is a relatively coarse arrangement, so the signal quality is not consistent. This implies a constantly varying SNR as the phased array antenna tracks each satellite during its overhead path.
It appears that Starlink services use dynamic channel rate control as a response to this constantly varying SNR. The transmitter constantly adjusts the modulation and coding scheme to match the current SNR, as described in the IEEE 802.11ac standard. The modulation of this signal uses adaptive phase amplitude modulation, and as the SNR improves the modulator can use a larger number of discrete code points in this phase amplitude space, thus increasing the effective capacity of the service while using a constant frequency carrier signal. What this implies is that the satellite service is attempting to operate at peak carriage efficiency, and to achieve this the transmitter constantly adapts its signal modulation to take advantage of the instantaneous SNR from the satellite system. To the upper layer protocol drivers, the transmission service appears to have a constantly varying channel capacity and latency.
The Starlink satellite’s Ku-band downlink has a total of eight channels using frequency division multiplexing. Each channel has an analogue bandwidth of 240MHz. Each channel is broken into frames, which are subdivided using time division multiplexing into 302 intervals, each of 4.4μs, which together with a frame guard interval makes each frame 1,333μs, or 750 frames per second. Each frame contains a header that contains satellite, channel and modulation information. The implication is that there is a contention delay of up to 1.3ms assuming that each active user is assigned at least one interval per frame.
This leaves us with four major contributory factors for variability of the capacity of the Starlink service, namely:
- The variance in signal modulation capability is a direct outcome of the varying SNR of the signal.
- The variance in the satellite path latency is due to the relative motion of the satellite and the Earth antennae.
- The need to perform satellite switching regularly.
- The variability induced by sharing the common satellite transmission medium with other users, results in slot contention.
One way to see how these variability factors impact the service characteristics is to use a capacity measurement tool to measure the service capacity regularly. The results of such a capacity measurement test in a Starlink service are shown in Figure 2. Here the test is a Speedtest measurement performed on a four-hourly basis for the period August 2023 through March 2024. The service appears to have a median value of around 120 Mbps of download capacity, with individual measurements reading as high as 370 Mbps and as low as 10 Mbps, and 15 Mbps of upload capacity, with variance of between 5 Mbps to 50 Mbps.
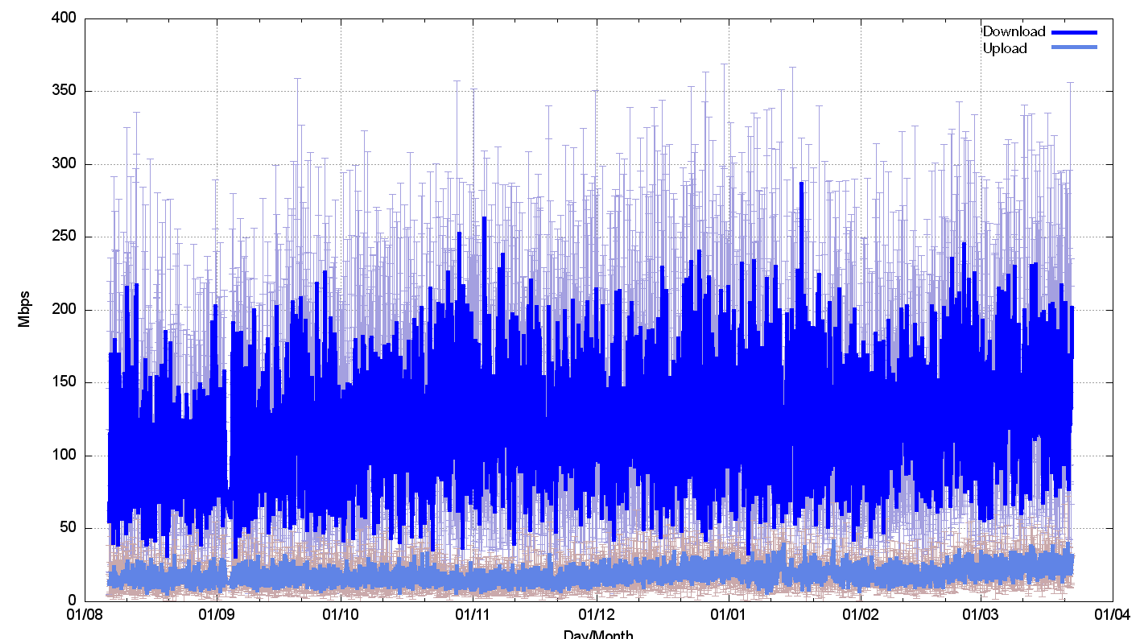
In Internet terms, ping is a very old, but still very useful tool, which probably explains its longevity. Figure 3 is a plot of a continuous (flood) ping across a Starlink connection from the customer side terminal to the first IP endpoint behind the Starlink Earth station for a 380-second interval (a ‘flooding’ ping sends a new ping packet each time a packet is received from the remote end).
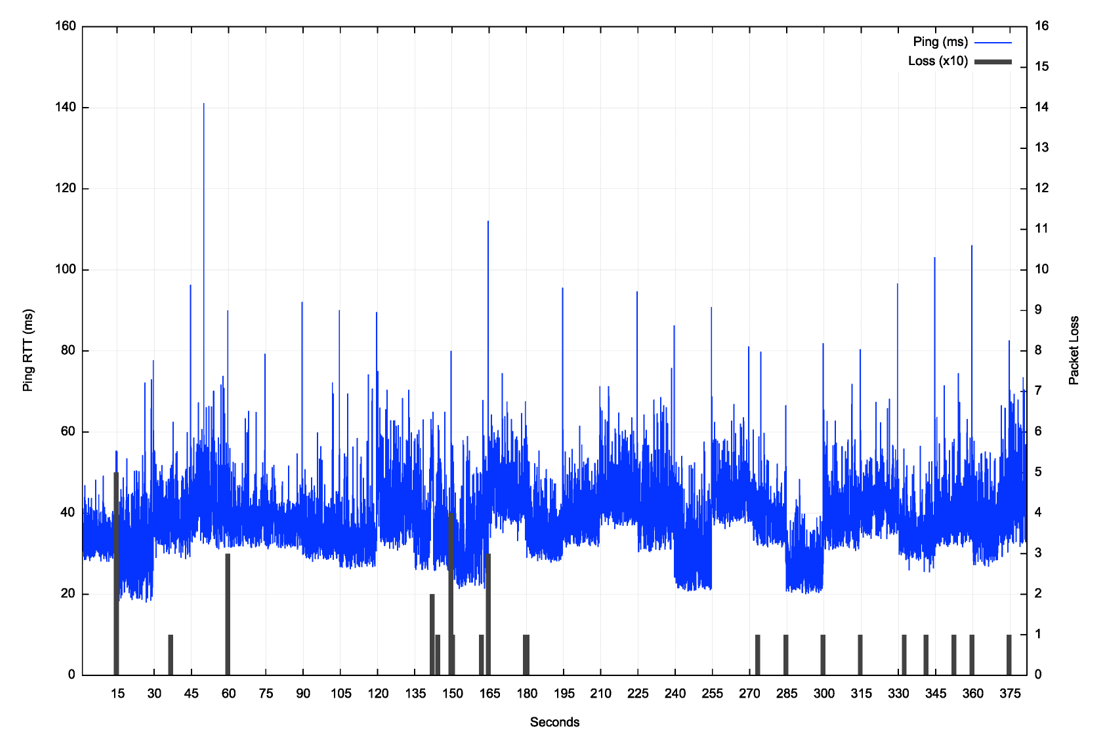
The first major characteristic that is visible in this ping data is that the minimum latency changes regularly every 15 seconds. It appears that this change correlates to the Starlink user’s terminal being assigned to a different satellite. That implies that the user equipment ‘tracks’ each satellite for a 15-second interval, which corresponds to a tracking angle of 11 degrees of arc.
The second characteristic is that loss events are seen to occur at times of switchover between satellites, as well as occurring less frequently as a result of either obstruction, signal quality or congestion.
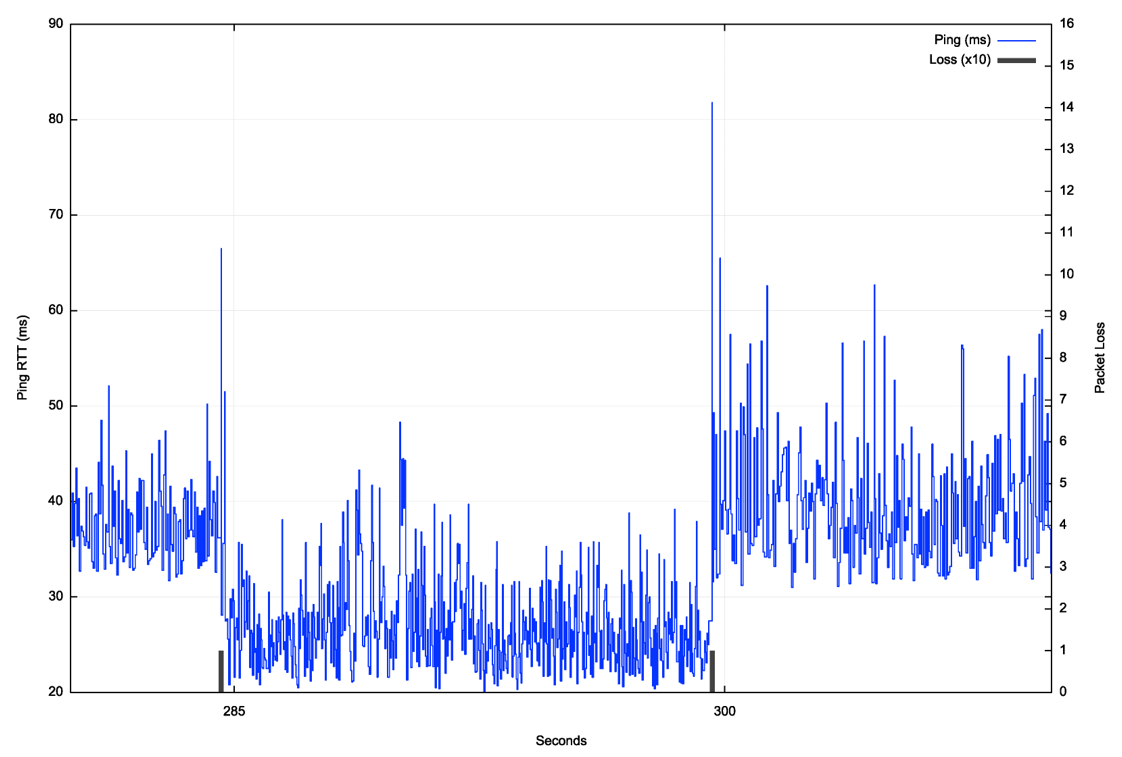
The third is that there is a major increase in latency at the point when the user is assigned to a different spacecraft. The worst case in this data set is a shift from 30ms to 80ms.
Finally, within each 15-second satellite tracking interval, the latency variation is relatively high. The average variation of jitter between successive RTT intervals is 6.7ms. The latency spikes at handover impose an additional 30ms to 50ms indicating the presence of deep buffers in the system to accommodate the transient issues associated with satellite handover. To illustrate this link behaviour the ping data set has been filtered to remove the effects of the satellite assignment at second 283 and second 298 (Figure 5).
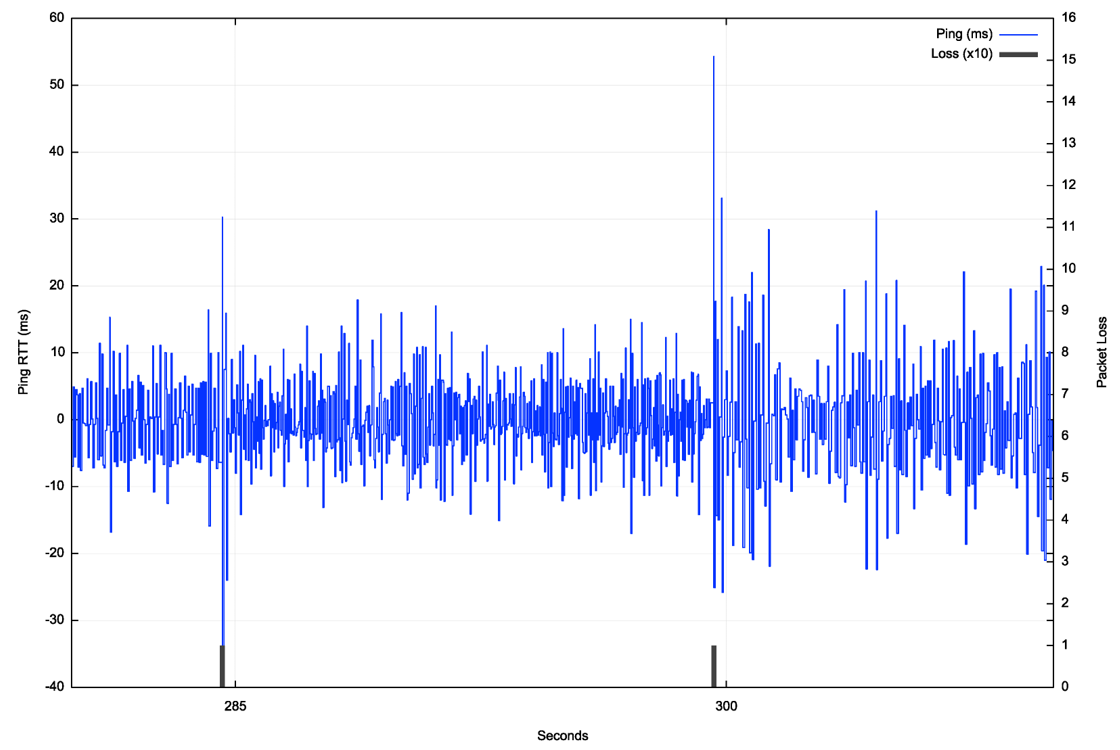
The overall packet loss rate, when measuring using 1-second paced pings over an extended period is a little over 1% as a long-term average loss rate.
TCP protocol performance
TCP (RFC 793) is an instance of a sliding window positive acknowledgement protocol. The sender maintains a local copy of all data that has been passed into the local system’s IP layer and will only discard that local copy of sent data when it has received a positive acknowledgement from the receiver.
Variants to TCP are based on the variations in the sender’s control of the rate of passing data into the network and variations in the response to data loss. The classic version of TCP uses linear inflation of the sending window size while there is no loss and halves this window in response to packet loss. This is the Reno TCP control algorithm. Its use in today’s Internet has been largely supplanted by the CUBIC TCP control algorithm, which uses a varying window inflation rate that attempts to stabilize the sending rate at a level just below the build-up of network queues (which ultimately leads to packet loss).
In general terms there is a small set of common assumptions about the characteristics of the network path for such TCP control algorithms:
- There is a stable maximal capacity of the path, where the term stability describes a situation where the available path capacity is relatively constant across several round-trip time (RTT) intervals.
- The amount of jitter (variation in end-to-end delay) is low in proportion to the RTT.
- The average packet loss rate is low. In the case of congestion-based loss TCP control algorithms packet loss is generally interpreted by the algorithm as a sign that the network’s buffers have filled, and loss is an indication of buffer overflow.
Obviously, as we’ve noted, the first two conditions do not necessarily hold for end-to-end paths that include a Starlink component. The loss profile is also different. There is the potential for congestion-induced packet loss, as is the case in any non-synchronous packet switched medium, but there is an additional loss component that can occur during satellite handover and a further loss component that can be caused by other impairments imposed upon the radio signal.
TCP typically tends to react to such environments by using conservative choices.
The RTT estimate is a smoothed average value of RTT measurements, to which is added the mean deviation of individual measurements from this average. For Starlink, with its relatively high level of individual variance in RTT measurements this means that the TCP sender may operate with an RTT estimate that is higher than the minimum RTT, which may result in a sending rate that is lower than the available end-to-end capacity of the system.
The occurrence of non-congestion-based packet loss can also detract from TCP performance. Conventionally, loss will cause the sender to quickly reduce its sending window, on the basis that if this loss is caused by network buffer overflow, then the sender needs to allow these buffers to drain, and then it will resume sending at a lower rate, which should restore coherency of the feedback control loop.
How does this work in practice?
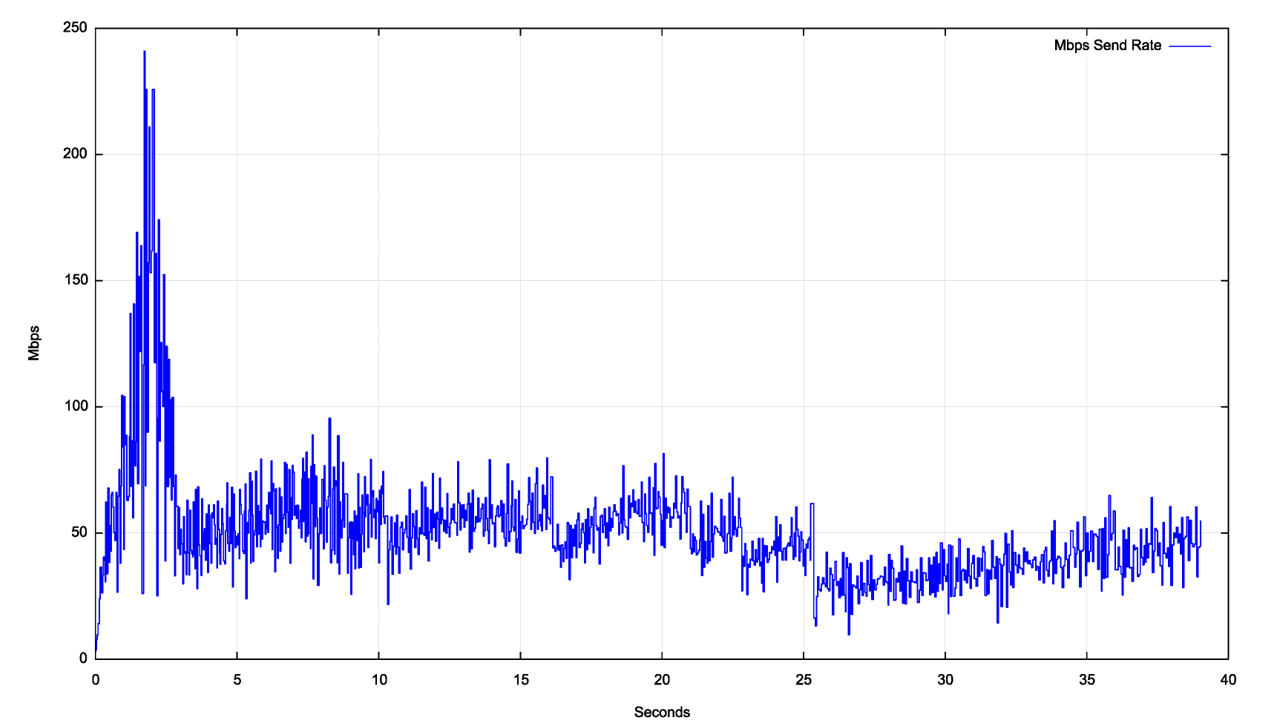
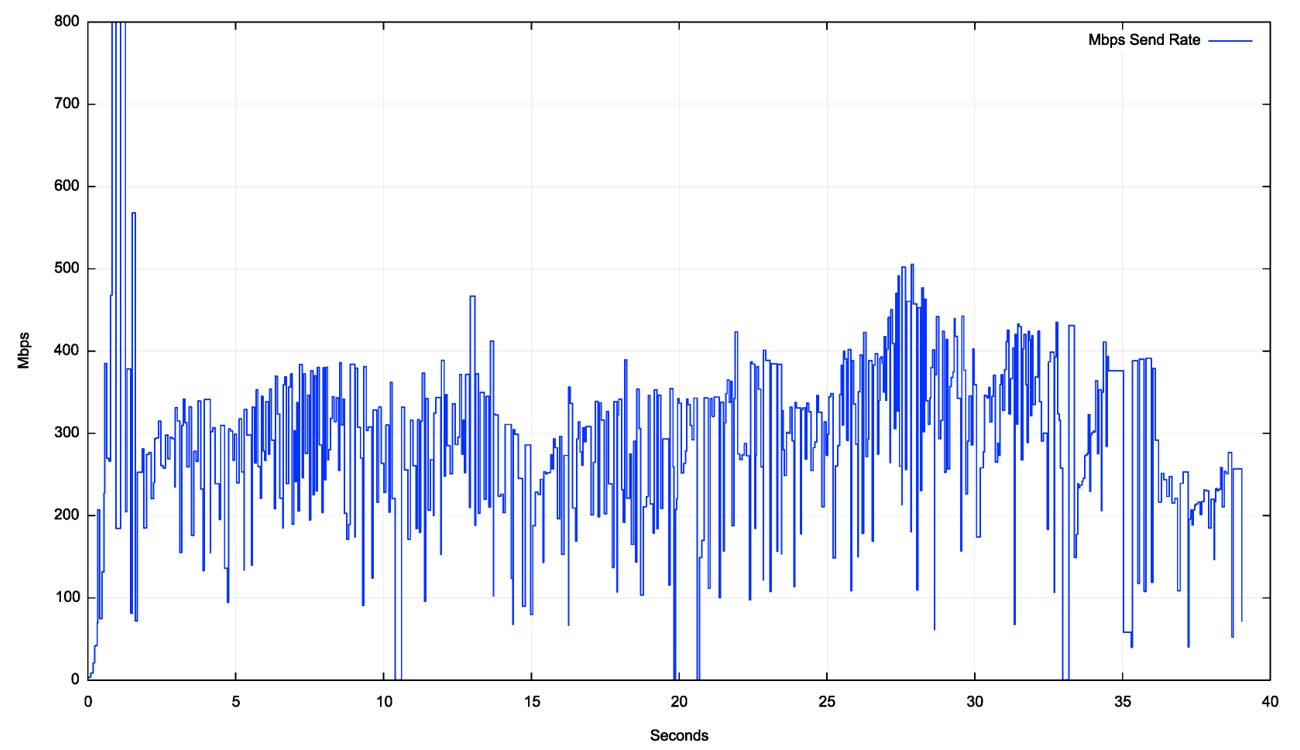
Figure 6 shows a detailed view of a TCP cubic session over a Starlink circuit. The initial two seconds show the slow start TCP sending rate inflation behaviour, where the sending window doubles in size for each RTT interval, reaching a peak of 240Mbps in two seconds. The sender then switches to a mode of rapid reduction of the sending window in the next second, dropping its sending rate to 50Mbps within one second. At this point the CUBIC congestion avoidance phase appears to kick in, and the sending rate increases to 70Mbps over the ensuing five seconds. There is a single loss event that causes the sending rate to drop in second 8 back to 40Mbps. The remainder of the trace shows this same behaviour of slow sending rate inflation and intermittent rate reductions, which is typical of CUBIC.
This CUBIC session managed an average transfer rate of some 45Mbps, which is well below the peak notional circuit capacity of some 250Mps.
Starlink is a shared medium, and the performance of the system in local times of light use (off-peak) is significantly different to the performance in peak times. Figure 7 shows the CUBIC performance profile during an off-peak time.
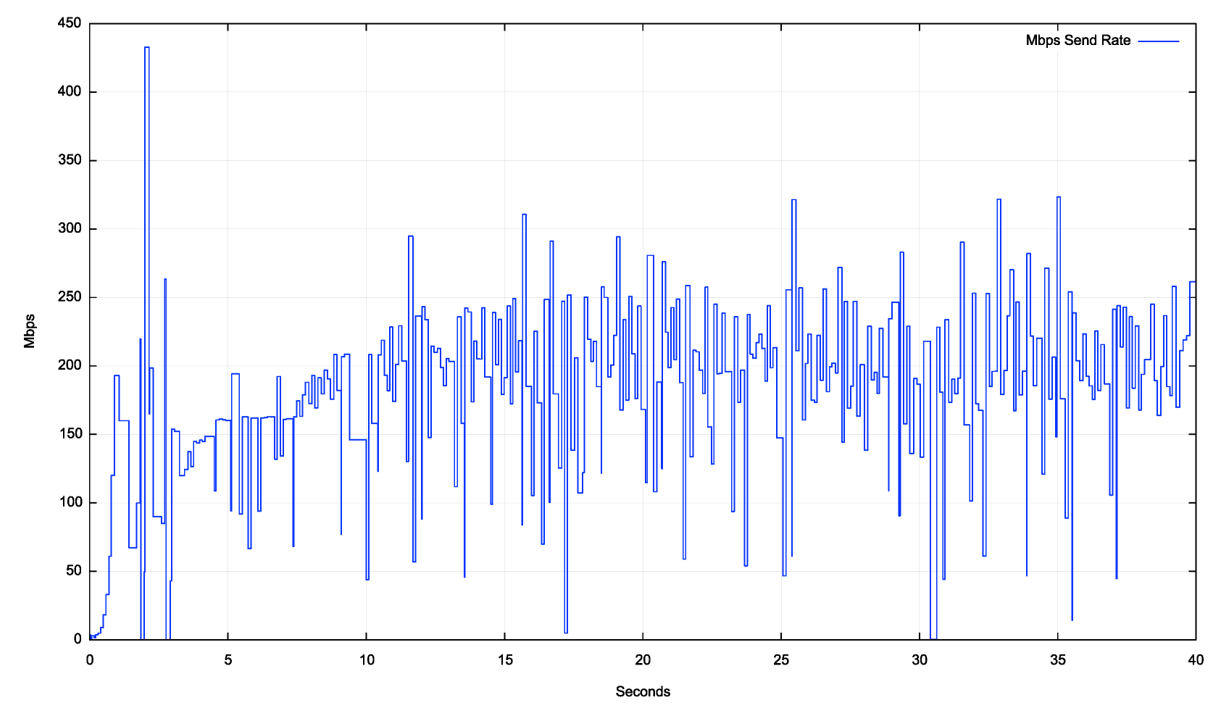
The difference between the achievable throughput between peak and off-peak is quite significant, with the off-peak performance reaching a throughput level some three to four times greater than the peak load performance. The slow-start phase increases the throughput to some 200Mbps within the first second. The flow then oscillated for a second, then started a more stable congestion avoidance behaviour by second 4. The CUBIC window inflation behaviour is visible up to second 12 and then the flow oscillates around 200Mbps of throughput for the remainder of the session.
Is the difference between these two profiles in Figures 6 and 7 a result of active flow management by Starlink equipment, or the result of how CUBIC reaches a flow equilibrium with other concurrent flows?
We can attempt to answer this question by using a different TCP control protocol, which has a completely different response to contention with other concurrent flows.
The Bottleneck Bandwidth and Round-trip propagation time (BBR) protocol is a TCP congestion control algorithm developed at Google a decade or so ago. BBR attempts to position the TCP flow at the onset of network queue formation, rather than oscillating between full and empty queue states (as is the case in most loss-based TCP congestion control algorithms).
Briefly, BBR makes an initial estimate of the delay-bandwidth product of the network path and then drives the sender to send at this rate for six successive RTT intervals. It performs repair for dropped packets without adjusting its sending rate. The seventh RTT interval sees the sending rate increase by 25% and the end-to-end delay is carefully measured in this interval.
The final RTT interval in the cycle sees the sending rate drop by 25% from the original rate, intended to drain any network queues that may have formed in the previous RTT interval. If the end-to-end delay increases in the sending rate inflated interval the original sending rate is maintained. If the increased sending window did not impact the end-to-end delay, then this indicates that the network path has further capacity, and the delay-bandwidth estimate is increased for the next eight-RTT cycle. (There have been a couple of subsequent revisions to the BBR protocol, but in this case, I’m using the original (v1) version of BBR.)
The results of a Starlink performance test using BBR is shown in Figure 8.
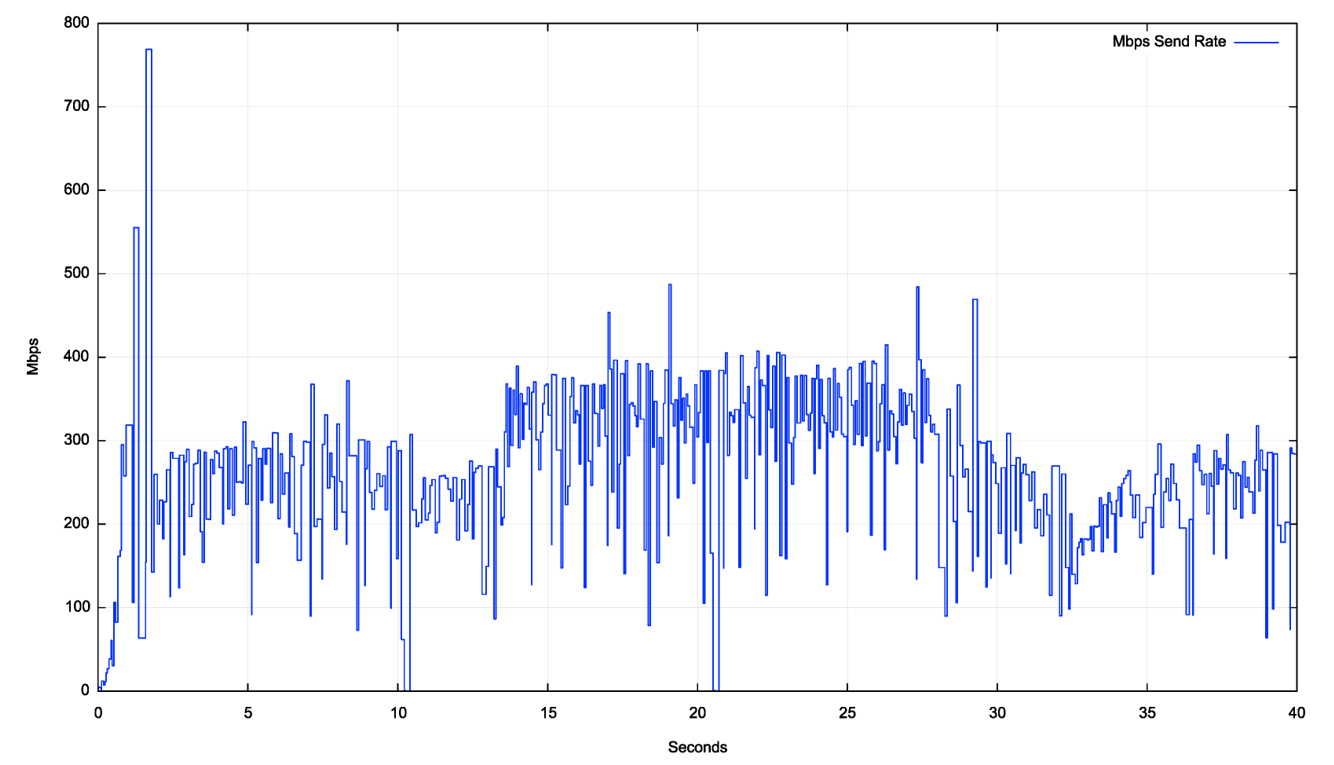
In this case, BBR has made an initial estimate of some 250Mbps for the path bandwidth. This estimate appears to have been revised at second 14 to some 350Mbps, and then dropped to some 200Mbps some 15 seconds later for the final 10 seconds of this test. These changes are likely the result of BBR responding to satellite handover in Starlink, and the variance in latency was interpreted by BBR as a sign of queue formation, or the absence of queue formation, which was used to alter BBR’s bandwidth delay estimate for the link.
The same BBR test was performed in an off-peak time, with a very similar outcome (Figure 9).
If BBR is sensitive to changes in latency, and latency is so variable in Starlink, then why does BBR perform so well compared to CUBIC?
I suspect that here BBR is not taking a single latency measurement, but measuring the RTT for all packets that are sent in this 7th RTT interval once the sender has increased its sending rate to the burst rate and uses the minimum RTT value as the ‘loaded’ RTT value to determine whether to perform a send rate adjustment. As long as the minimum RTT levels remain consistent (as illustrated in Figure 3, which shows these values are stable across each 15-second scheduling interval), BBR will assume its sending rate is not causing network queue formation and will maintain its sending rate.
Protocol tuning for Starlink
Starlink provides a somewhat unique data link service. It has a very high jitter rate, a packet drop rate of around 1% to 2% that is unrelated to network congestion, and a latency profile that jumps regularly every 15 seconds. From the perspective of the TCP protocol, Starlink represents an unusually hostile link environment, and older variants of TCP, such as Reno TCP, that react quickly to packet loss and recover slowly, can perform very poorly when used across Starlink connections.
Could you tune a variant of TCP to optimize its performance over a path that includes a Starlink component?
A promising approach would appear to start with a variant of BBR. The reason for the choice of BBR is its ability to maintain its sending rate in the face of individual packet loss events. If one were to optimize BBR for Starlink then it can be noted that Starlink performs a satellite handover at regular 15-second intervals, and if the regular sending rate inflation in BBR occurs at the same time as the scheduled satellite handover, the BBR sender could defer its rate inflation, maintaining its current sending rate across the scheduled handover time.
The issue with BBR is that, for version 1 of this protocol, it is quite aggressive in claiming network resources, which can starve other non-BBR TCP concurrent sessions of capacity. One possible response is to use the same 15-second satellite handover timer with version 3 of the BBR protocol, which is intended to be less aggressive when working with concurrent data flows.
In theory, it would be possible to adjust CUBIC in a similar manner, performing a lost packet repair using Selective Acknowledgement (SACK) (RFC 2883) if the packet loss occurred at the time of a scheduled satellite handover. While CUBIC is a fairer protocol for sharing the path capacity with other concurrent TCP sessions, it tends to react conservatively when faced with high-jitter paths (as is the case when the end-to-end path includes a Starlink component). Even with some sensitivity to scheduled satellite handovers CUBIC is still prone to reduced efficiency in the use of network resources.
A somewhat different approach could use Explicit Congestion Notification (ECN) (RFC 3168). The advantage of such an approach is that it allows the TCP session to differentiate the case where a high sending rate causes the formation of network queues (congestion), while a transient event, such as satellite handover, causes packet loss without network queue formation. ECN can permit a flow control behaviour that is very much like BBR.
Conclusions
While earlier TCP control protocols, such as Reno, have been observed to perform poorly on Starlink connections, more recent TCP counterparts, such as CUBIC, perform more efficiently. The major TCP feature that makes these protocols viable in Starlink contexts is the use of Selective Acknowledgement, which allows the TCP control algorithm to distinguish between isolated packet loss and loss-inducing levels of network congestion.
TCP control protocols that attempt to detect the onset of network queue formation can do so using end-to-end techniques by detecting changes in end-to-end latency during intermittent periods of burst, such as BBR. These protocols need to operate with careful implementation of their sensitivity to latency, as the highly unstable short-term latency seen on Starlink connections, coupled with the 15-second coarse-level latency shifts have the potential to confuse the queue onset detection algorithm.
It would be interesting to observe the behaviour of an ECN-aware TCP protocol if ECN was enabled on Starlink routing devices. ECN has the potential to provide a clear signal to the endpoints about the onset of network-level queue formation, as distinct from latency variation.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Fabulous article thank you.
I think there’s a typo here:
“This orbital velocity at the surface of the Earth is some 40,320km/sec.”, which is about 15% the speed of light!
Should it rather read 11.2km/sec, or 40,320km/hour?
Also have you considered the congestion response when you use SQM for bufferbloat avoidance?
And what about when using UDP transport (QUIC)?
heh – yes – its 40,320km/hour!
Regarding Smart Queue Management (SQM) my primary aim in this measuremnt exercise was to measure how protocol perform over the existing equipment, not to look at the potential impact on various SQM measures on Starlink performance. In environments such as Starlink which have a high jitter component its challenging to get a decent indicator of the onset of queue formation. It seems to me that the ECN approach would be a better approach.
Finally, bout QUIC, then remember that in transport performance terms QUIC is just TCP. Many QUIC implementations use CUBIC and over Starlink they behave like any other CUBIC session. The few that use BBR behave loke BBR.
Yes there is a trend in the developer community to move control into the application later and think the problem is solved. They do this also with libp2p.
I was just wondering if the bufferbloat solution which works very well when routers are using long Q’s, would have any impact for it against with Starlink. It would be easy to set up a trial using OpenWrt.
It would be interesting to see not just RTT times but one-way delays measured by irtt tool.
it would be interesting – I’ll give it a shot!~ thanks for the suggestion
TCP protocols like CUBIC show improved performance on Starlink connections compared to earlier ones like Reno, thanks to features like Selective Acknowledgement.
SACK is a big reason why modern TCP protocols perform well over radio (mobile and satellite) services. SACK allows isolated packet loss events to be repaired by the protocol without stopping the flow and reverting to slow start.
There are still a set of residual issues with long delay systems and “sender bursting”, whicvh can induce tail drop in the network queue which is disruptive to TCP’s ACK pacing. Using paced sending (https://fasterdata.es.net/host-tuning/linux/packet-pacing/) you can mitigate this, and the combination of SACK and paced packet sending.
Is there anything that a user can currently do (in a Windows, Mac, or Linux environment) to mitigate this and improve overall connection performance over Starlink?
In Lionux you may want to look at installing BBR as the default TCP congestion control algorithm. I am unaware of any user level actions you can take on Windows or Mac hosts.
Geoff,
changing the congestion control algo on your computer will only affect the congestion control in the upstream (user to internet) direction. Fo the Downstream direction, is the congestion control algo used by the “server” on the internet that will control that. Am i right?
normally yes – but in this case I am using iperf3 (https://github.com/esnet/iperf) between my servers on either side of the starlink connection, so I have contgrol of the congestion control algorithm in both directions for this measurement exercise.
VPN provides solution for both senders to have BBR.
Does Starlink allow you to use a custom router? If so flash OpenWrt onto the router of your choice. It’s Linux.
Yes you can by their router in bypass mode and use your own router behind it.
Thanks for the interesting article!
This is a complete nuance: but it turns out that the 15-second min RTT changes are not always due to a user being assigned a different satellite.
We did some of our own analysis, and confirmed with Starlink folks, and found that a user could still be connected to the same satellite, but the routing path of the satellite could have changed at the 15 second interval.
(shameless self plug): If curious, you can find more in our Sigmetrics’24 paper (https://arxiv.org/pdf/2306.07469) — Fig 5 and Section 7 are the most relevant here.
thanks indeed for the pointer to your paper!
‘Geoff
Fantastic article, thank you for writing this.
Just to clarify on packet loss, is the 1-2% average packet loss reflective of a burst of packet loss every 15s, followed by low/zero loss between handovers? How long does the actual handover take?
Regards,
Ron
Hi Ron,
Yes, as shown in Figure 5, a typical handover _MAY_ involve packet loss at the point of handover, and if there is loss it is normally limited to a single packet.
The handover also invol,ves a higher delay, so the handover appears to take some 35ms to 50ms, which is surprisingly fast!
Great article, as expected from Geoff. Any insights on how Starlink behaves for traffic between two moving vehicles, each with their own dish to connect?
Thanks for the Interesting question,
As far as I can tell Starlink operates in a single mode – dishy to/from earth station (with maybe a laser link between spacecraft for isolatged dishy systems). That would imply that your scneario from moving vehicle to moving vehicle is the same as two Starlink services in series. From the perspective of a starlink satellite a moving vehicle is little different to a stationary dishy, so I suspect that this is much the same as any other dishy-to-dishy service.
Both services would be recheduled to a different spacecraft every 15 seconds using the same UTC clock so I suspect that the switching component (elevated delay and higher packet loss) would be doubled in such a scenario. As for jitter, The two systems would presumably not be in phase doe the jitter would not be doubled – more likely to be increased by 30% or 40 (perhaps by the quare root of 2??)
Thanks for the Interesting question,
As far as I can tell Starlink operates in a single mode – dishy to/from earth station (with maybe a laser link between spacecraft for isolatged dishy systems). That would imply that your scneario from moving vehicle to moving vehicle is the same as two Starlink services in series. From the perspective of a starlink satellite a moving vehicle is little different to a stationary dishy, so I suspect that this is much the same as any other dishy-to-dishy service.
Both services would be recheduled to a different spacecraft every 15 seconds using the same UTC clock so I suspect that the switching component (elevated delay and higher packet loss) would be doubled in such a scenario. As for jitter, The two systems would presumably not be in phase doe the jitter would not be doubled – more likely to be increased by 30% or 40 (perhaps by the square root of 2??)