

Distributed Denial-of-Service (DDoS) attacks continue to pose a significant challenge for online services today. In those attacks, offenders attempt to overwhelm a service by flooding it with traffic from multiple sources, making it inaccessible to legitimate clients.
Operators who cannot outsource this problem (for example, should policies prohibit the use of a scrubbing service) must find ways to deal with it. The size of the attack, volume, and characteristics will determine the possible mechanisms that can protect services from such attacks. Filtering non-attack traffic can help mitigate small attacks, but attacks that would overwhelm one site require the use of IP anycast to spread traffic over the large network capacity of multiple sites.
Anycast is a network addressing and routing technique where servers at multiple sites provide the same service by sharing the same IP address. When a client sends a request to a service using IP anycast, the network routes the traffic to the nearest server, based on the BGP (Border Gateway Protocol) routing preferences. The result is that traffic is distributed across multiple sites, reducing the load on each site and improving service availability. Anycast is commonly used in large-scale providers such as Content Delivery Networks (CDNs), Domain Name System (DNS) servers, and cloud computing platforms.
During a DDoS attack, network operators use anycast routing choices (traffic engineering, or TE) to shift load from the overloaded sites to other sites with excess capacity. The goal of the network operators is to use TE to balance traffic across anycast sites during a DDoS attack.
Mitigation plans
An anycast operator should follow two steps to defend against DDoS. First, an operator should know the true estimation of the offered load of the DDoS to understand if spreading traffic will be effective (the best defence for attacks that exceed the capacity of all sites is to concentrate attack traffic on a few sites with filtering).
Learning the true load is challenging because the loss in the upstream providers means it cannot be directly measured by the operator. Second, an operator must predict the impacts of a routing change to understand how much traffic will shift to other sites.
Predicting the effects of a routing change is hard because BGP policies are affected by all ISPs, not just the operator, so how much traffic shifts can vary. Changing a route without properly knowing its impact may overwhelm other anycast sites.
True estimation of the ingress load
Our goal is to estimate the offered load. The first step is to measure the observed traffic rate, which an operator can observe after the loss. Then one should measure the access fraction — the fraction of traffic that is not dropped.
We observe that known good traffic has the same loss on incoming links as other good traffic and attack traffic. So, we compare the known good traffic (for example, the number of RIPE probes) during the normal and attack period. The observed load (from the first step) is the fraction of traffic that could get access from the total offered load. We can write: Total offered load * Access fraction = Observed load. Then we can estimate the total load by knowing the access fraction and the observed load.
Playbook to learn the impacts of routing changes
An operator should create a playbook before an attack so that the defender can select a routing change to redistribute traffic during an attack. The playbook will help to learn how much traffic an anycast site will get after a routing change. Then, during an attack, based on the estimation of the offered load and the potential impacts of a routing change, an operator can select a routing approach to redistribute the traffic.
How to build the BGP playbook?
First, an operator should know the routing options that they can use, possibly path prepending, community strings for controlling announcements, and path poisoning. Then an operator needs a test prefix to play it with different routing policies. Routing changes would vary the traffic distribution. An operator should build the playbook with these routing changes and corresponding traffic distributions. We suggest the operators use Verfploeter to map the clients to anycast locations.
A sample playbook
We show a sample playbook in the following table with a three-site anycast network using a testbed. The left column shows our possible routing options, and the three right columns show the corresponding traffic distribution in three anycast sites. This table shows different levels of traffic distribution. For example, the AMS site can serve 5% to 85% of the total load.
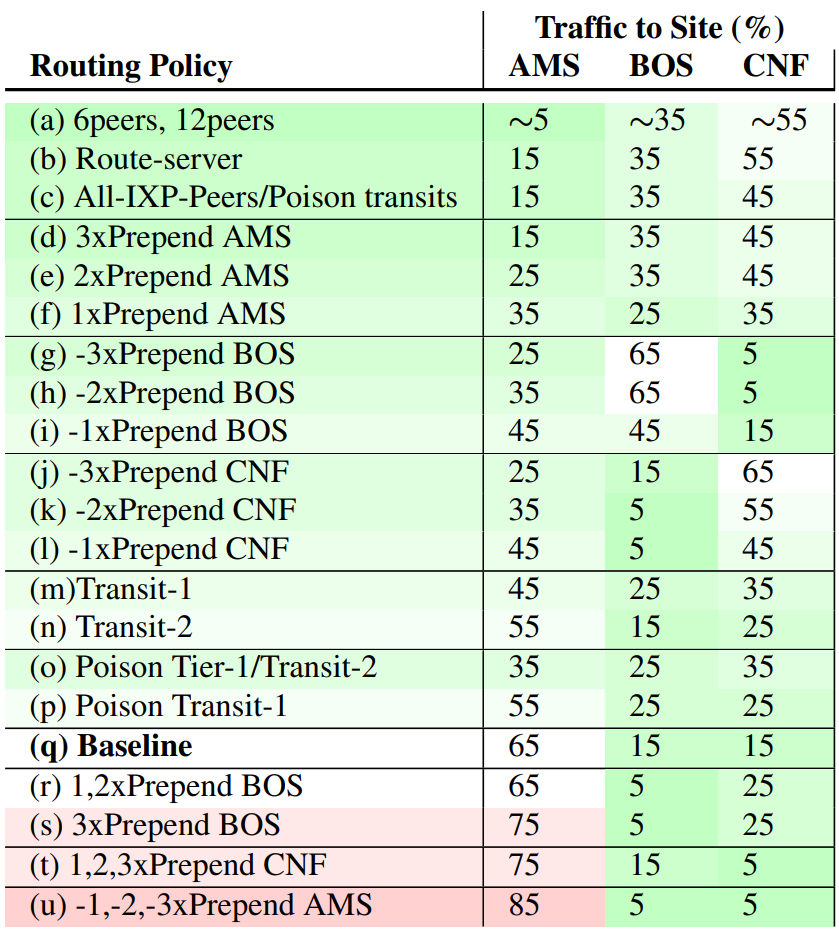
sorted by a rough fraction of traffic to AMS, and colours showing
the traffic compared to the baseline distribution.
Mitigating real-world attacks
Next, we use a real-world attack from B-root to show that we can successfully mitigate an attack using our playbook. We evaluate these events by simulating traffic rates against a three-site anycast network. We use an event from 2017 (our paper has other events).
This event was a volumetric polymorphic attack. We assume 60k packets/s (30 Mb/s) capacity at each anycast site. The following figure shows that the AMS site receives 100k packets/s traffic, more than the capacity (shown as the maroon-stripped area). Our system estimates the AMS overload by computing the offered load using the observed load and access fraction.
Using the playbook, our system/operator can then select a response. Figure 2 shows the impact of the selected routing approach — announcing only to Transit-1 using community string. After 300 seconds, we can see no striped area, which indicates the attack is mitigated.
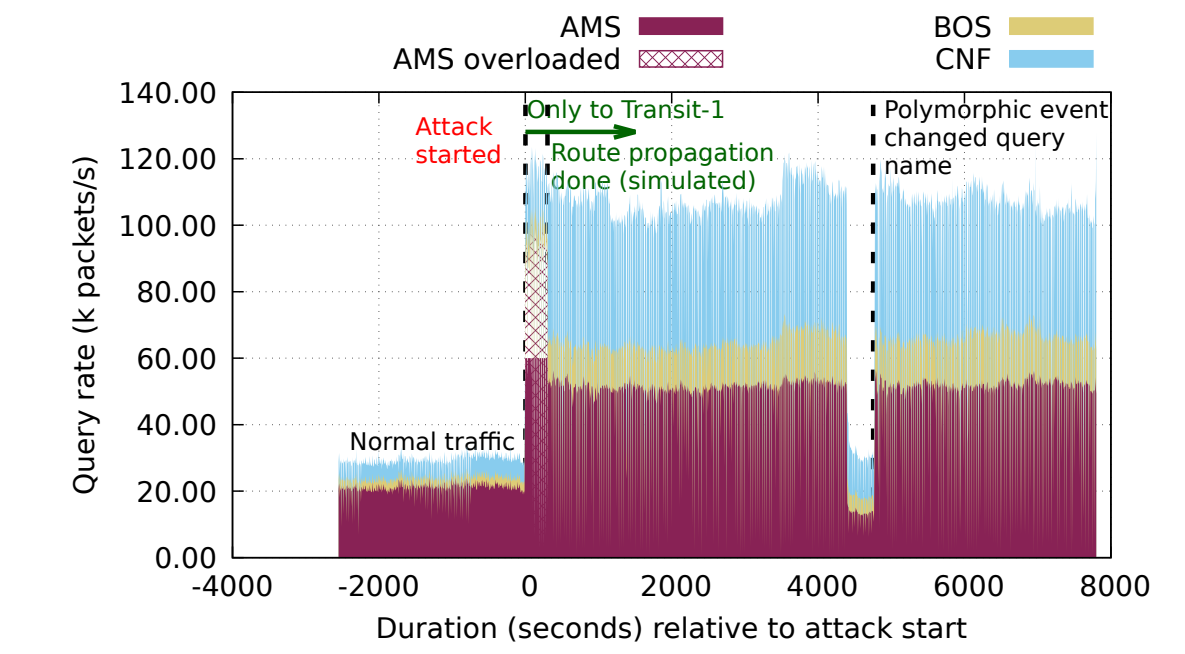
with community strings.
This post was written in collaboration with other authors of the paper: Leandro Bertholdo (PhD candidate, University of Twente), Joao Ceron (Researcher at Botlog.org), and John Heidemann (Research Professor at the University of Southern California and Principal Scientist, USC/ISI). Read the paper at Usenix.
ASM Rizvi is a PhD candidate at the University of Southern California. His research interests include networking, security, and Internet measurement.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.