

SIDN Labs’ research is aimed at improving the security, stability, and resilience of the Internet infrastructure. In that context, Machine Learning plays an increasingly important role. It has, for example, helped us to automatically detect thousands of fake webshops, establish partnerships for fighting domain name abuse, and help abuse analysts identify malicious .nl sites, for example, on the basis of logo abuse. In this blogpost, we at SIDN Labs consider the future and discuss the research we’re planning with a view to further increasing Internet security, with the aid of Machine Learning.
Machine Learning is taking off
Machine Learning (ML) involves the use of computer algorithms that automatically extract rules and patterns from large volumes of data and use them as a basis for making decisions or predictions. Numerous major advances in ML have been made in recent years, leading to increasing use of ML algorithms for high-stake decisions. Examples include new image recognition algorithms based on deep learning, enabling cars to function on an increasingly autonomous basis and systems that support doctors in the analysis of medical scans.
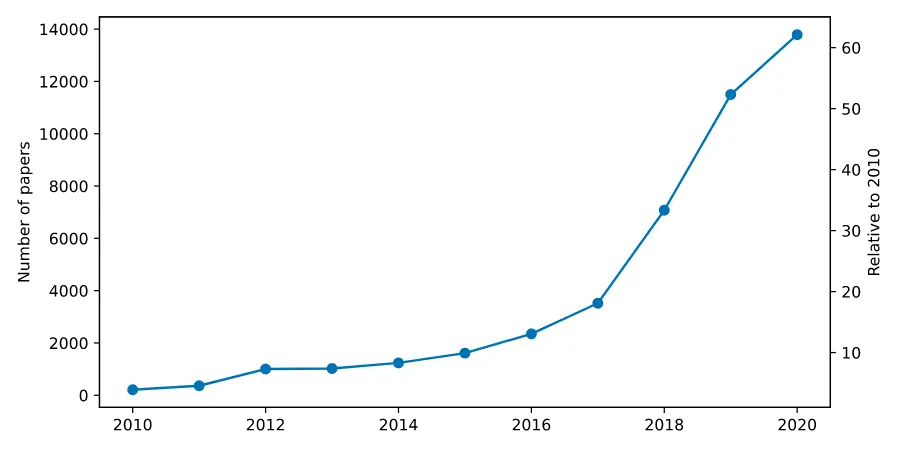
ML has become so important that Apple has recently started making processors for its computers that are specially optimized for ML algorithms. The rate of advance is also reflected in the number of academic articles devoted to ML. In 2020, 13,788 articles on the subject were added to arXiv.org, an open library of academic papers. That is more than sixty times as many as in 2010, as shown in Figure 1.
Using ML to increase Internet and DNS security
At SIDN Labs, we’re involved in researching ML algorithms for a ‘niche’ application — to increase the security of the Internet and the Domain Name System (DNS). Our aim is to add and evaluate ML algorithms, so that DNS actors — registries (including SIDN itself), registrars and DNS operators — can apply them to their datasets. Our ML work is relevant, because many large datasets relating to Internet and DNS security topics are available, but their size limits both their usefulness for manual pattern recognition and the scope for keeping them updated.
In relation to .nl, for example, we generate DMAP crawler data (6.2 million new measurements a month) that we use for fake webshop identification, and we have an historical DNS database called ENTRADA (which sees more than two billion new data points a day) that can be used for botnet pattern detection. At SIDN Labs, we’ve chosen to place the emphasis on innovation with ML. In other words, we monitor the academic literature in this field and seek to make innovative use of promising methods that can support our aims. We generally leave the innovation of ML to large research teams at universities and corporations like Google and Microsoft.
Responsible ML
SIDN Labs give explicit consideration to the way we use ML, in recognition of the social and ethical impact of algorithms. We therefore follow the philosophy of responsible ML, which we interpret as follows:
- We apply the ‘human-in-the-loop’ principle. In other words, our systems don’t make any automated decisions about changes to domain name registrations (such as the removal of a name from the zone, or the delinking of nameservers). We also use feedback from users to keep improving our models.
- We believe that we should be able to understand and explain the outcomes associated with our systems. We therefore have a strong preference for algorithms that are intrinsically explainable or can be made explainable.
- We seek to collaborate with other parties and we publish our findings. The rationale being that broad input enhances the quality of our work and reduces the risk of bias, while publication gives registrars, other registries and partners the ability to learn from our successes and mistakes. Operating in this way therefore helps others to contribute to Internet security.
- We continuously monitor the performance of our models by reference to multiple indicators. That enables us to detect various types of error and more accurately assess how well our systems are working.
Issues addressed by this research agenda
The research agenda is structured around three research questions:
- RQ1: How can we get even better at proactive abuse detection?
- RQ2: How can we train shared abuse models without exchanging data?
- RQ3: How can we maximize the effectiveness and speed of our anycast infrastructure monitoring and management?
We are focusing on those three research questions because the answers can contribute to Internet security and because the questions lend themselves to investigation with ML. The reason for the latter being that numerous relevant data points are available, but rules cannot be derived manually.
RQ1: How can we get even better at proactive abuse detection?
We’ve been investigating the proactive detection of suspect websites using ML since 2018, because detection capability helps registries like SIDN to take down malicious content sooner, thus minimizing the number of victims.
In relation to RQ1, our primary aim is to continue refining the systems we have already developed:
- Fake webshop Detector (FaDe): FaDe has already enabled us to detect thousands of fake webshops. In the period ahead, we plan to use FaDe to monitor the strategies used by fraudsters. It’s important to do that, because the detection of fake webshops is a cat-and-mouse game, in which the fraudsters are always changing tactics to escape detection.
- LogoMotive: Helps abuse analysts (such as those working for the government) identify phishing sites based on logo abuse. We will be investigating how we can use LogoMotive output more widely, like identifying suspect webshops. Our focus on visual website content is innovative, and we expect it to make a positive contribution to the detection of malicious sites.
Another way we intend to address RQ1 is by using ML in the detection of compromised domain names. In that context, we distinguish two types of attack:
- Domain name hacks: These are commonplace and usually involve the exploitation of vulnerable web technologies, like outdated WordPress plugins. We want to investigate the possibility of proactively detecting domain names of this type from changes in the DNS traffic. However, we recognize that it will be challenging, because such changes may have a variety of causes. Moreover, as a TLD operator, we are not well placed to follow up on any suspicions we may have, because we have little information about the websites in question. With those considerations in mind, we have started a pilot with the registrar, Realtime Register, to explore the possibility of jointly investigating suspect domain names.
- DNS hijacks: These are attacks in which criminals attempt to seize control of a domain name. Such attacks rarely come to public attention, but when they do occur their impact can be serious. The reason being that a hacker who has administrator-access to a domain name’s nameservers can modify its individual DNS records. So, Internet users can be directed to a different server hosting, say, malicious content or a data harvesting operation. Unfortunately, DNSSEC cannot protect against attacks of this kind. We therefore plan to investigate the possibility of using ML algorithms in the detection of DNS hijacks. In the context of that investigation, the shortage of ground truth data represents a challenge. We may therefore start with a cluster analysis or an anomaly detection exercise. That would involve looking for and then investigating unusual data points, on the grounds that they could be associated with suspect modifications.
RQ2: How can we train shared abuse models without exchanging data?
Registries often have access to a lot of data (such as registration and DNS data) but have a limited view of the Internet environment. At SIDN, for example, we have no access to the information that registrars and hosters hold about .nl domain names.
Collaboration with the registries for other top-level domains (TLDs) can also help us to improve our ML models and reduce the risk of bias in our work. Therefore, we want to investigate how we might use technologies such as federated learning to train models in collaboration with partners (like other ccTLD registries or .nl registrars). We would like to do that because the exchange of privacy-sensitive data can be challenging, due to the need for harmonization and legal alignment.
In federated learning, each individual partner independently trains a temporary ML model. The temporary models are abstractions and contain no sensitive information but are inaccurate. The various temporary models are then combined to create a sound model that all the partners can use. One possible route is to work with a group of ccTLDs (such as under the CENTR umbrella) to train a model for the detection of suspect domain registrations. After all, the problem of cybercrime is not specific to any one TLD or registrar. By ‘looking over the fence’, we may discern other patterns, for example, the bulk registration of domain names under multiple TLDs with a view to using them for fake webshops.
RQ3: How can we maximize the effectiveness and speed of our anycast infrastructure monitoring and management?
SIDN has been using anycast for some years. Since last year, SIDN Labs has had its own BGP anycast testbed, which we use for our NTP service time.nl, for example. Anycast boosts the resilience and performance of our DNS infrastructure, but also increases the number of systems and configurations that need to be managed and monitored. We therefore want to explore the scope for using ML algorithms to help network operators monitor and manage their anycast infrastructures.
For example, we are considering developing a system that generates warnings in the event of notable network traffic shifts, such as a sudden surge in the volume of traffic to a particular anycast node. Flagging traffic shifts would hopefully facilitate rapid response by network operators. That might involve, say, deploying additional nodes or making certain routes more or less attractive and thus rebalancing the traffic distribution.
Another question we want to examine is whether we could help operators interpret traffic shifts. Why is it, for instance, that a sudden surge occurs in the volume of traffic to a particular node? The approach we have in mind is to correlate data on network traffic shifts with data from other sources, such as RIPEstat, which records BGP routing changes.
Collaboration on ML applications
As you’ll have gathered, there are many ways ML can increase the security of the Internet and the DNS. Over the next two years, we intend to explore some of those possibilities by addressing the research questions set out above. Got any suggestions or feedback? Have you spotted an opportunity for collaboration? If so, please drop a line to thymen.wabeke@sidn.nl.
Thymen Wabeke is a Research Engineer at SIDN Labs.
This post is co-authored by Thijs van den Hout and Cristian Hesselman, and was originally published on SIDN Labs.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.