

With information security such a complex and fast-moving field, how can companies gather enough information to make informed decisions about what is right for their networks? What criteria should you look for, how do you evaluate systems, and how can you determine which methods will scale most effectively?
This is the second in a series of blog posts (Part 1) on security by diversity. We will focus on some of the key issues in the business of security today, especially the problems of quality uncertainty and the scaling of different forms of security.
The market logic of diversity as a service
It is common in the field of information security economics to refer to a text by Akerlof from the 1970s (The Market for “Lemons”: Quality Uncertainty and the Market Mechanism), which discusses the market mechanisms related to what Akerlof terms ‘quality uncertainty’.
Quality uncertainty refers to a point of information asymmetry when a prospective buyer cannot properly judge the quality of a product on the market which, therefore, prevents the possibility of evaluating whether a fair price is offered. Akerlof gives the example of the used car market — a buyer is not willing to pay a higher price for a used car than what the buyer believes the car is worth based on the quality that they can verify. In the context of information security, quality uncertainty means that a provider of secure services cannot charge more for these services than their customers have the ability to assess.
So how should prospective customers assess a security service?
Evaluate the security of a system
One approach is to evaluate the number of nodes involved in the functions provisioning the service or, more specifically, the number of potential single points of failure. For example, if you are buying an eIDAS-compliant identity provisioning service, it is preferable to buy the service from a provider with a higher number of independent nodes than a provider with few independent nodes even if the latter has better nodes.
Another approach is to look for certifications; however, certifications are often best practices for a limited time. In the dynamism of cybersecurity, what was secure yesterday won’t necessarily be secure tomorrow. It is important to remember that certifications are tools to reach a goal, in this case, security. In more detail, certification implies comparing something at a specific point in time with a specification. If the document compared is of low quality or the comparison is out-of-date, the tool will not provide the desired result.
Another approach is to look at service provider track records; an actor with a good track record is likely to provide secure services today and tomorrow. The drawback is that, for obvious reasons, newer actors that possibly have better and more modern routines do not have track records. Another problem with track records is that, in the security sector, they tend to consist of failures rather than successes, which further problematizes the issue of assessing quality for the prospective buyer.
This blog post argues that a good method in an information security setting is to evaluate the number of independent nodes involved. It is specifically better than looking at certification or track records because certifications quickly become irrelevant and track records tend to focus on failures rather than successes. The best course of action is to look at all three (number of independent nodes, certifications and track records).
For the purpose of this blog, a system consists of nodes, and a system delivers one function.
The cost of building secure systems
Table 1 illustrates three main approaches to securing a system — hardening nodes, increasing the capacity of nodes, and increasing the number of nodes. In environments with physical nodes, these costs are fairly similar. There is a cost for designing the nodes themselves, hardening them, improving their capacity and building more. In environments with digital nodes, the case is very different for producing more nodes. In this case, producing more nodes is significantly cheaper than improving or developing nodes.
As an example, the current DevOps trend towards continuous integration and deployment further accentuates the relation between the cost of the first node and the cost of additional nodes. In many orchestration environments (such as Kubernetes and OpenShift), it is possible to add more nodes by modifying a single line in a config file, lowering the marginal cost of node production to virtually zero. This means that the most resource-efficient approach to availability is redundancy and diversity. This is likely to remain the case as the cost of additional nodes decreases in relation to the cost of the first node.
The next section provides an example based on the assumption of the work necessary, or the cost involved, to improve a default system by the methods discussed above.
Scaling security
The previous blog post in this series discussed different forms of security for systems consisting of several parts or nodes — hardening (better uptime or lower downtime of nodes), increasing capacity (of nodes) or diversifying (more nodes). The graph below builds on the mathematical assumptions of the first blog post.
| Per node | At system-level | ||||
| MTTR | MTBF | Probability up | m / n | MTTR + MTBF | Probability up² |
| 336hrs | 8,760hrs | 96.31% | 20 / 25 | 156 years | 99.98% |
| 48hrs | 8,760hrs | 99.46% | 20 / 25 | 1.29 * 10⁶ years | 99.99…% |
| 336hrs | 87,600hrs | 99.62% | 20 / 25 | 7.40 * 10⁷ years | 99.99…% |
| 336hrs | 8,760hrs | 96.31% | 10 / 25 | 2.15 * 10¹⁵ years | 99.99…% |
| 336hrs | 8,760hrs | 96.31% | 20 / 50 | 6.45 * 10²⁹ years | 99.99…% |
Table 1 — Comparison of systems providing availability through capacity scaling, hardened nodes, and increased availability of nodes. ‘m’ nodes are required for service, ‘n the amount of nodes in total. *With the exception of the first row, none of these systems deviate from nines (9) until the 7th decimal.
In Table 1, row 3 corresponds to hardening nodes; row 4 corresponds to increasing the capacity; and row 5 to increasing diversity. The expected uptime of increasing diversity is magnitudes higher than the expected uptime of increasing the capacity of nodes which, in turn, is magnitudes higher than hardening the nodes. But how do the different methods scale if we also take into account the work necessary to make such improvements?
The graph below shows how the methods scale per extra work input.
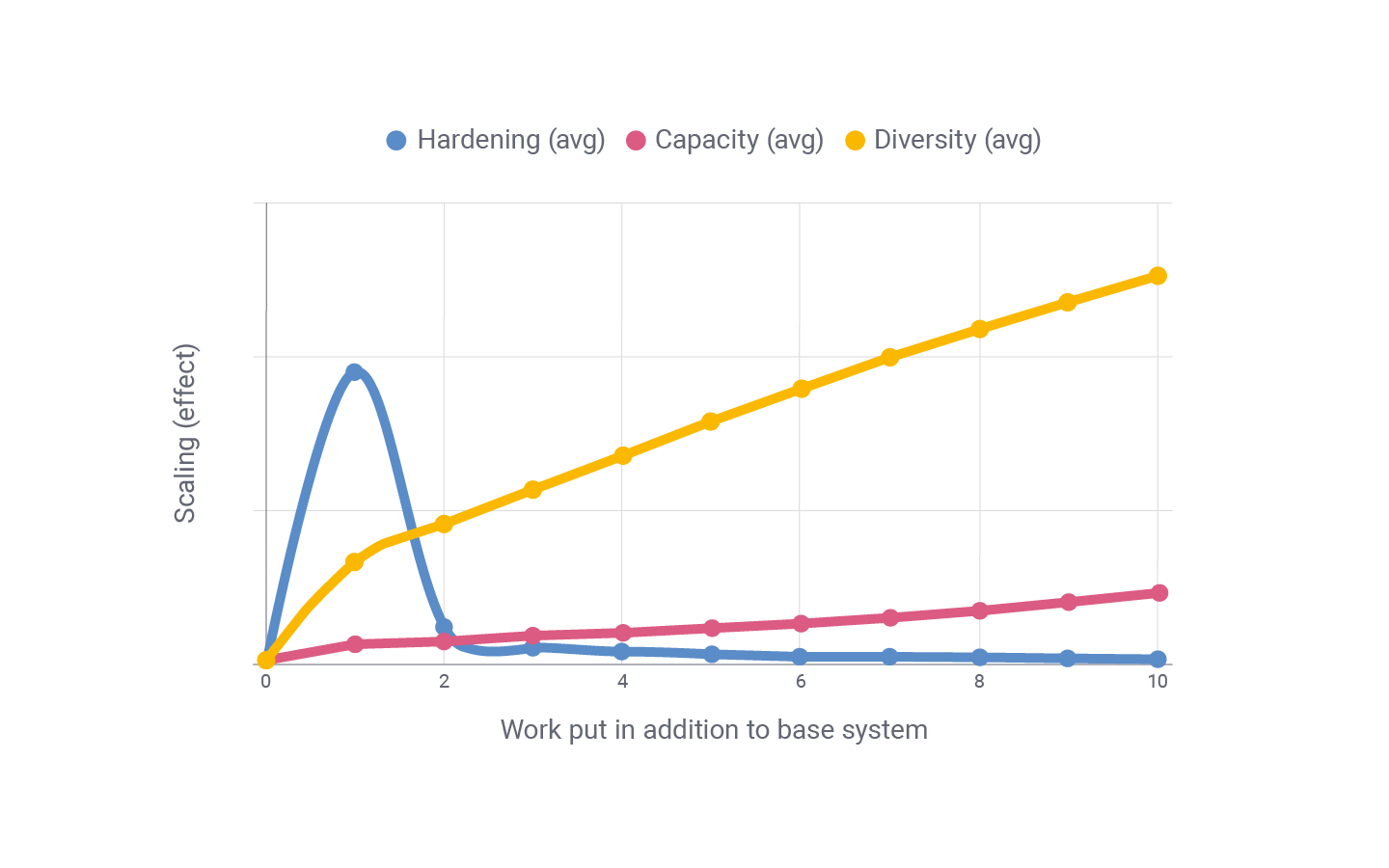
In Figure 1, I show the scaling of work effort on Mean Time Between Failures (MTBF) for hardening, capacity increases and diversity. ‘Work put in’ of 0 represents the base system in Table 1 (row 1); the blue, red, and yellow curves show the effects of putting further work into each of the three methods (hardening, increasing capacity and increasing diversity). The base system represents a work effort of 10, and the individual curves represent the scaling effect per additional work put in.
The graph represents averages, where the averages are based on assumptions of the cost of different improvements to the system.
Hardening scales well with low work input but declines quickly. In contrast, capacity increases (decreasing nodes needed) and diversity (number of nodes) scale exponentially; that is, the more work you put in the more they scale.
Hardening, the blue line, represents a system where the MTBF of individual nodes is improved in a linear fashion. This results in a high return on work investment for the initial work, but the more work you put in the less effect it has on the security of the system. To put it simply, hardening is essentially a waste of resources as soon as the individual nodes have meaningful uptimes.
Capacity increases, the red line, represents a system where the capacity of the individual nodes is increased; that is, the system needs fewer nodes to maintain function. The assumption is that the additional work needed for the system to require one less node to maintain function increases exponentially. We see that additional work on increasing the capacity of nodes leads to a higher effect per additional unit of work.
Increased diversity and redundancy, the yellow line, represents a system where work is put into increasing the number of nodes of the system. The line represents an average of systems where ten additional work units represent a doubling of nodes and that the growth of the number of nodes is linear to the additional work put in. This leads to a scaling effect where the more work you put in, the more effect each additional work unit will have on the security of the system.
Scaling security: An example
Let’s take an example based on the assumptions and graph above.
You are budgeted with 15 work units. Your task is to build the most secure system possible with these resources. What should you do?
The base system is 10 work units. That leaves you with five work units to further improve the system.
According to the graph, hardening (blue line) has the best effect for the first work unit, but the effect of putting an additional unit into hardening (that is, two work units in total) is smaller than putting a work unit into diversity. This can be seen by comparing the line for hardening for work unit 2 with the line for work unit 1 of diversity (yellow).
By picking the most effect per work unit, you end up with 10 work units in the base system, one work unit put into hardening the nodes, and four work units into increasing the amount of nodes.
To recap, the base system from the previous blog post in this series can be improved in at least three distinct ways:
- Improving the time between failures for nodes (hardening, blue).
- Improving the capacity of individual nodes so that fewer nodes are required to maintain function (red).
- Increasing the number of nodes in the system (diversity, yellow).
In a real-world scenario, you are likely to mix improvements, but if you were to focus on one method, increasing the diversity of the system has a significantly larger effect per work unit than hardening or capacity increases of nodes.
In other words, when it comes to larger amounts of work, diversity scales better than both hardening and capacity increases. If increasing the amount of nodes is not possible due to real-world constraints, capacity increase always scales better than the hardening of nodes. Individual nodes will fail, so having more nodes provides better security than a comparable capacity increase or hardening of nodes.
The key takeaway here is that it is possible to compose a secure system out of inherently insecure components given sufficient understanding of the components and their interdependencies. It is possible to compose secure services yourself, but this requires a high level of in-house competence especially when it comes to domain-specific expertise and cybersecurity; it is also possible to acquire secure services using consultants or providers.
Summary
Security is complex, digital security particularly so due to frequent changes and adaptations of the tools and components involved. In terms of technology and coordination, it is possible to achieve availability through diversity and redundancy. That is, a service can be built securely even if each of the components of the service is insecure on its own, such as nodes with high failure rates.
The most cost-effective way to scale a system consisting of nodes is to focus on increasing the diversity and number of nodes involved in the system. If that is not possible due to real-world constraints, increasing the capacity of nodes, that is lowering the amount of nodes needed to provide service, is the second best option.
The business case of information security is more complex; it is costly to acquire the competence to build secure systems yourself, and acquiring secure products and services on a market is not without problems. In general, the best business decision is to acquire services from a provider with a good track record who can supply secure services with diversity.
Fredrik Lindeberg is a Security Expert in Netnod’s Security Engineering team.
This post is adapted from the original at Netnod blog
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.