

Managing and operating modern data centre networks is becoming increasingly complicated. To service emerging workloads (for example, cloud computing, the Internet of Things, and augmented/virtual reality), network operators employ intricately complex ‘solutions’ full of hand-tuned parameters to adapt to the changing environment.
Today, the most intensive (and intelligent) operations are hosted in the slower control plane, while solutions run in the faster data plane. This dynamic hampers network operators from creating smarter data-plane solutions and faster control-plane alternatives, making it challenging to keep up with the changing network conditions.
This raises the question: Should network operators be trying to keep up?
The job of a network operator is continuous — clever workarounds that suffice today will be obsolete tomorrow. What if the network had a mechanism to learn and adapt to the current environment? What is the exact adaptive mechanism that could run at data-plane speeds, breaking the ‘fast but simple’ or ‘intelligent but slow’ paradigms in favour of ‘fast and intelligent’ operations?
These adaptive mechanisms can be implemented by the same set of algorithms currently taking the world by storm: Machine Learning (ML). Training on data from the network will customize functionality to the peculiarities of the environment. All that remains is to run them at data-plane speeds.
Per-packet inference in the data plane
Taurus is a new data-plane architecture for switches and Network Interface Controllers (NICs) that runs ML models at line rate and uses their output for forwarding decisions.
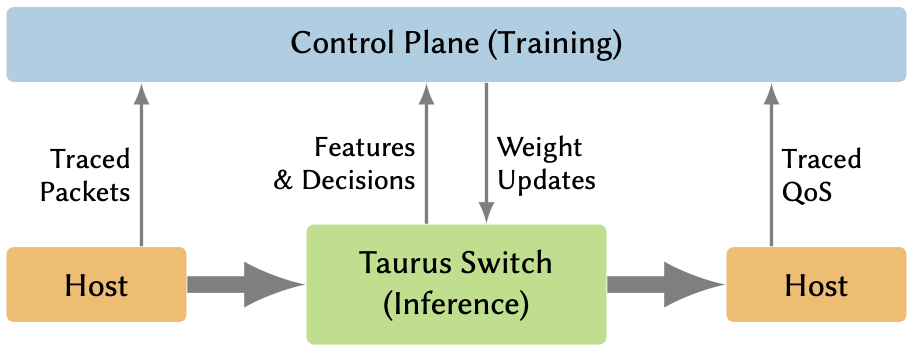
In a Taurus-enabled data centre, the control plane gathers a global view of the network and trains ML models to optimize security and performance metrics. Meanwhile, the data plane uses these models to make per-packet, data-driven decisions. Unlike traditional Software Defined Networking (SDN) based data centres, the control plane now installs both model weights and flow rules into switches.
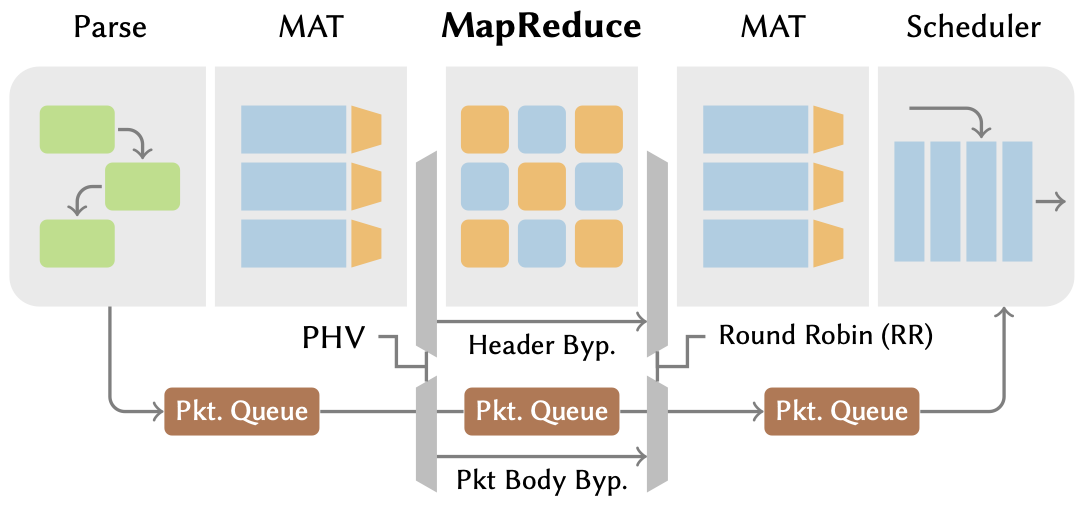
As packets enter a Taurus switch (Figure 2), they are first parsed into a fixed-layout and structured format. The switch then uses match-action tables (MATs) to look up and perform preprocessing actions on designated header fields, preparing them to be consumed by an ML model. Taurus then uses a programmable Single Instruction, Multiple Data (SIMD) block (the MapReduce unit) to execute ML inference on extracted packet features. Finally, post-processing MATs transform the model’s output into decisions to aid, for example, packet scheduling and forwarding.
For each packet, inference combines cleaned features and model weights to direct the forwarding behaviour. Traditional ML algorithms, like Support Vector Machines (SVMs) and neural networks, use matrix-vector linear-algebra operations and element-wise non-linear operations. Similarly, neural networks use matrix multiplication and non-linear activations to execute prediction functions.
The linear operations involve large-scale multiplication and addition of features and weights, while activations let models learn non-linear semantics for the theoretical expression of any function. Unlike header processing, these computations are very regular and happen at a scale ill-suited for MATs but ideal for SIMD-based hardware.
We use MapReduce SIMD parallelism in Taurus to provide superior computation throughput with minimal, high-utilization hardware. Map operations are element-wise vector functions, such as addition, multiplication, or non-linear arithmetic. Reduce operations combine vector elements to singular values using associative functions, such as addition and multiplication. By supporting these standard primitives, Taurus supports a broad set of applications, including ML, while maintaining a simple and high-performance programming model.
How well does the Taurus architecture work in practice?
My colleagues and I at Stanford University and Purdue University evaluated Taurus to explore the full implications of its architecture and abstraction.
First, we designed and ran the ASIC synthesis with a 15nm technology process for the proposed MapReduce block. We designed our ASIC to support a suite of real-world ML-based networking models.
We found that the MapReduce block only incurs up to 4% area and 3% power overhead relative to state-of-the-art switches while running popular ML algorithms (like SVMs, K-means, and DNN) at line rate (1 gigapackets per second) — realizing our vision of a data-plane pipeline that executes per-packet inference with minimal overhead.
How can I get involved?
While many of our evaluations are based on an ASIC design, we do not want prospective users to wait for a commercial chip before diving into the exciting work of per-packet data-plane ML. To this end, we have provided two different testbed artefacts along with various microbenchmarks and real-world applications.
The first artefact uses industry-standard hardware, software, and an FPGA to emulate the Taurus MapReduce block. The second functions as a behavioural model implemented entirely in software (no need to buy hardware!). Both artefacts are available via our GitLab.
See our GitLab home page for related papers, presentations, and tutorials on Taurus.
Tushar Swamy is a PhD candidate in the Electrical Engineering Department at Stanford University, where he is advised by Kunle Olukotun.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.