
Imagine you are developing a new protocol like TCP BBR, or a networked application like uTorrent. You could even be adding features to an existing application such as Skype. Your latest modification might sound great in theory, but how would you go about testing whether it would work well in the ‘real world’?
That’s the key question this blog post will explore.
Testing with small groups
A common approach taken today is to run A/B test flights. In an A/B test, you flight your modifications on a small set of real-world users to test whether your new application is better than the existing alternative.
A/B test flights are quite realistic since you’re running the change on real users who use their own systems to run your application, but there are still a few major problems. The risk of regression (introduced by the modification) means that flighting is typically done on a small fraction of users, and consequently, it takes time to accumulate a statistically significant volume of data.
Therefore, even if the treatment were to do better, you’d have to wait weeks or even months to draw any conclusions from the test.
How about simulation?
We have plenty of simulation models for systems — ranging from models of wired-up Ethernet networks to satellite networks. And more importantly, simulation offers the prospect of quick results without any risk of user impact.
But the simulation world is a make-believe world, and the results are only as realistic as the simulator is. Even with a faithful recreation of network mechanisms (like queuing) in modern simulators such as ns-2/3, we are unlikely to obtain realistic results unless the simulated network has been configured appropriately in terms of link bandwidth, buffer depth, cross-traffic, and so on. Without appropriate configuration, the simulation would be a far cry from a real-world network, and this lack of realism would lead to misleading, often overly optimistic, conclusions.
To draw an analogy, how confident would you be of your driving skills, having only learned to drive through a driving simulator?
Can we achieve the best of both worlds?
For a moment, imagine if the driving (network) simulator was so realistic in its depiction of real-world roads (Internet) and traffic (network load) that driving instructors (developers) could train their students (applications) entirely in simulation and be sure that the performance would translate over to the real world? Such a simulator would enable fast, inexpensive training and reduce performance regressions when moving from simulation to the real world.
Introducing iBox
This is where the iBox (Internet in a Box) project comes in. iBox tries to bring in enough realism to network simulation so that key metrics (like throughput and delay) can be predicted in simulation. iBox tries to piece together the Internet by answering several questions — how do we create realistic models of Internet paths? What amount of competing traffic is realistic? Naturally, these are tough questions to answer as iBox has no knowledge of the network or other sources of traffic on it. Still, in this post we shall explore how iBox can infer this information using data from real-world applications to reconstruct the network.
Plenty of data in the form of traffic traces is available through large-scale real-world deployments of applications like Skype or TCP Cubic. Using such data, we focus on inferring and recreating real-world, end-to-end network path behaviour. iBox’s goal is to capture the ‘background’ behaviour of a real-world network so that the performance of a ‘foreground’ protocol can be evaluated realistically in this setting.
Two distinct approaches
We start by considering two extremes for iBox. One centres on a network model (iBoxNet), similar to an ns-2/3 model, but with the network topology, configuration and quite crucially, the competing cross-traffic all learned through data. The other extreme focuses on using Machine Learning (iBoxML) to learn a state-space model, which encodes the state of the network using a deep Long Short-Term Memory (LSTM) neural network.
The network-model approach (iBoxNet)
In the iBoxNet approach, we seek to create a parameterized model to mimic a target network path. For a given real-world network trace, we try to recreate the network path by inferring specific parameters of this path to reconstruct the exact scenario in which this trace originated. iBoxNet infers not only (mostly) static parameters like bottleneck bandwidth, buffer depth, and propagation delay but also highly dynamic parameters like the amount of competing traffic on this network path.
For the purposes of this blog post, we’ll not be delving into how iBox estimates the static parameters. Instead, we’ll focus on the more challenging problem of estimating the amount of competition (what we call ‘cross-traffic’). Continuing on our driving analogy, modelling cross-traffic would be akin to modelling how other drivers behave on roads. They might change lanes suddenly without indication, which might demand quick reflexes from you, analogous to how a competing application might suddenly send a burst of traffic on the same network path your application is on. Modelling such interactions between applications is quite critical for faithful simulation.
To understand how we detect and measure cross-traffic, think of the bottleneck in the network as a queue with three forces acting on it, as shown in Figure 1. Packets sent from our application (self-traffic) queue up at the bottleneck (1), packets sent from all other applications (cross-traffic) also queue up at the bottleneck (2), and packets get dequeued from the bottleneck at its supported link capacity (3). Since we know term 1 (from our packet traces) and term 3 (estimated in a previous step), we can estimate term 3: the cross-traffic sending rate. The cross-traffic estimated in this way is non-adaptive, meaning it does not react to any changes from its competition during the recreation and would only replay the sending rates it operated on in the real world.

Using this cross-traffic estimate and the static parameters such as bottleneck bandwidth and buffer depth, we wire up our simulation network, which is now tuned to match reality. All that remains is to run our modified application in iBoxNet and see how well it would perform in the ‘real world’.
Figure 2 shows how well iBoxNet can predict performance for two protocols — TCP Cubic (existing variant) and TCP Vegas (experimental variant). The plot shows a close match between the protocol’s performance observed in the real world (ground truth: yellow and red dots) and its corresponding performance in the iBoxNet simulator (inference: green and blue dots) in terms of the application sending rate and incurred packet delay. The key point to note is that iBoxNet uses only data from TCP Cubic to configure itself and predict the performance for both protocols. These results show the promise of using iBoxNet to predict an untested application’s performance without ever releasing it in the wild.

The Machine Learning approach (iBoxML)
In iBoxNet’s network-model approach, many assumptions are made about the inner workings of the target network. For example, we assume that there’s only a single bottleneck link that we need to model. But what if there are two bottlenecks? And what if the bottleneck bandwidth is a highly dynamic value? To sidestep these assumptions, we introduce a Machine Learning-based approach called iBoxML, which takes a clean slate approach to use network data to find an LSTM configuration that can best explain this data.
As Figure 3 shows, at a high level, iBoxML estimates the next network state conditioned on the past states, past and present inputs (application sending rate), and then predicts the output (packet loss/delay). During the training phase, we take an application packet trace from our dataset and feed the sending rates as input to iBoxML. iBoxML would then try to learn suitable LSTM weights to be able to predict the correct network outputs.
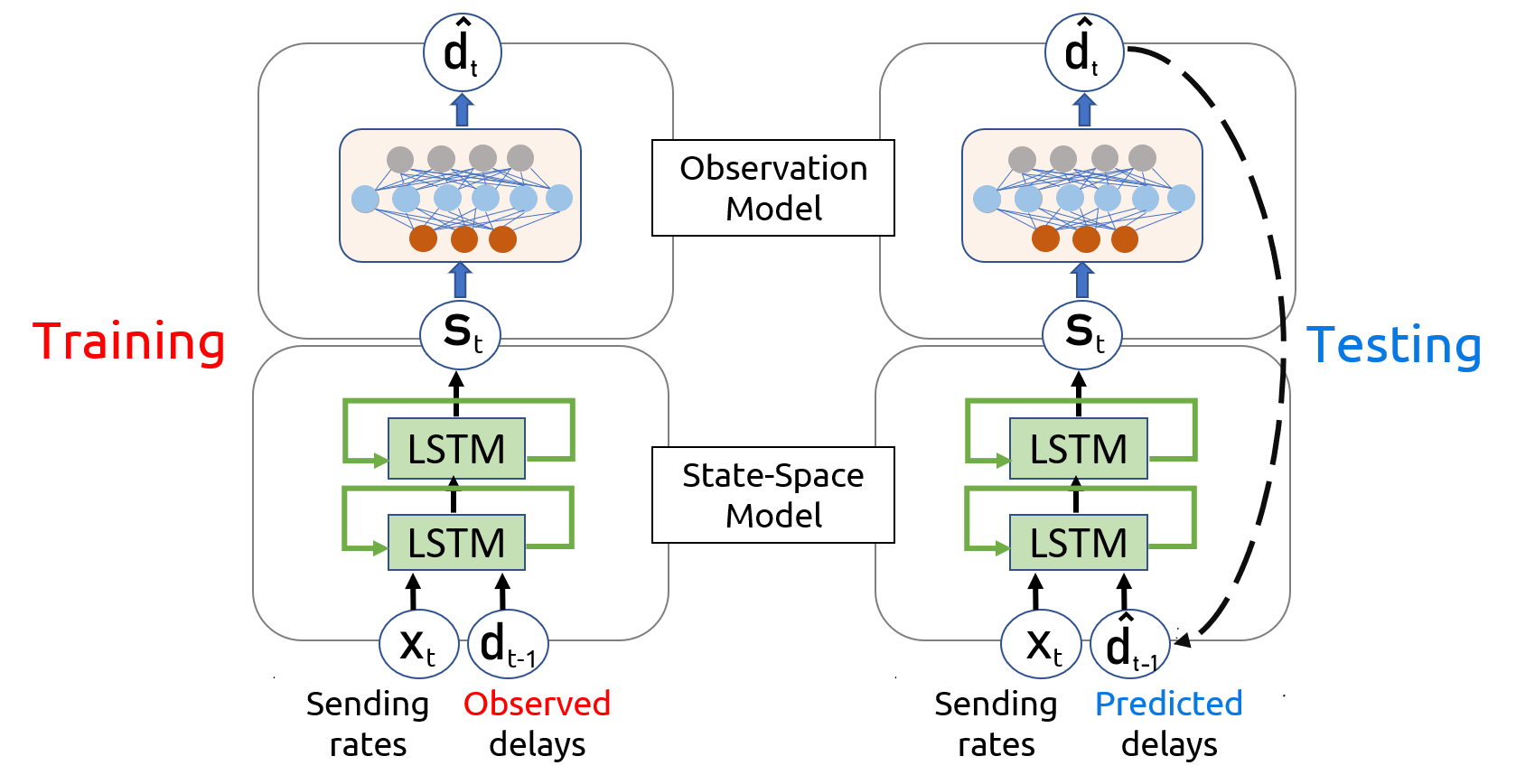
During the test phase, the modified application is run against this LSTM network, which has now learned to mimic the real Internet. We send in packets into the network at some rate as decided by our new application, and the LSTM network would dictate how much to delay a packet or indeed whether to drop it!
iBoxNet or iBoxML?
Both iBoxNet and iBoxML have their unique strengths and limitations.
While iBoxML doesn’t make any assumptions about the network and is more general in scope then iBoxNet, it is limited by the training data. When iBoxML is exposed to inputs outside the realm of its training data, it does not degrade well. For example, if an application acts maliciously and dumps packets into the network at a high rate, iBoxML may not give out an appropriate network response as it has never seen such behaviour from real-world application data. On the other hand, iBoxNet would increasingly delay packets until it needs to drop them when queues fill up, which is as expected from a real network.
Ultimately, it is left to the developer to decide which approach might work better for them in their testing scenario.
Related work
iBox isn’t the first project to ask these questions about simulation realism. Notable projects like Mahimahi and Pantheon have tried to achieve similar goals. But neither of them explicitly tries to model cross-traffic and its significant impact on the application’s performance. Similarly, approaches like trace-driven replay, which replay a raw delay/packet loss trace as the output, fail to capture the impact of a modified application on the network. The modified application could react in ways that could lead to different delay or loss outputs which a simple trace replay cannot model.
The future of data-informed network simulation
While many challenges lie ahead in this line of work, data-informed network simulation is quite certainly an exciting research direction. Many challenges remain, but one of the main parts of the puzzle is how to best meld networking domain knowledge with Machine Learning. iBox has only just begun to scratch the surface of it.
To learn more about iBox, please check out the research paper and HotNets’20 talk.
If you’d like to use the iBoxNet network models for your own research, they are available for public download at GitHub. Please visit the project website for more details.
iBox is being developed by Sachin Ashok, Sai Surya Duvvuri, Nagarajan Natarajan, Venkata N. Padmanabhan, Sundararajan Sellamanickam, and Johannes Gehrke from Microsoft Research.
Sachin Ashok is a Computer Science PhD student at the University of Illinois Urbana-Champaign (UIUC) and was previously a Research Fellow at Microsoft Research India.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Hi, Sachin:
1) Your preamble seems to be contradicting to the keyword of the title (Simulating) as well as the message of the main body (simulation). I am not sure why did you want to go through such a gyration. It did not introduce any merits to your work. Granted, a simulation system (either software modeling or hardware emulation) can not replace the real environment. The basic fact is that the more realistic information is included, the better the simulation will be. Obviously, if something critical is missing, the simulation can not deliver what was expected from it. The best example is the recent Boeing 737-Max disaster. By “regarding” a change as trivial, thus not incorporated such in the flight simulator, the loss of lives were inexcusable. Are you suggesting that your iBox proposal inherently will somehow incorporate more real life system setup, traffic data, etc. than existing ones? Why?
2) The only way to make a simulator more realistic is to start with as much realistic elements of the real system as possible. In this respect, there is a potential physical network facility that can significantly simplify your efforts in building up a simulator. It is a generic network test bed that I proposed in response to a call to facilitate getting end-user more involved with the Internet development. You may want to have a look at the second comment to the following blog:
https://blog.apnic.net/2020/08/31/rfc-8890-the-internet-is-for-end-users/
The last sentence of Pt. 3) of that comment presented such a possibility.
I look forward to your thoughts,
Abe (2021-06-01 23:28 EDT)