

IETF 110 was held virtually in March 2020. Here are some notes on current research activities in transport protocol flow control, I took at the meeting of the Internet Congestion Control Research Group (ICCRG), during IETF 110.
HPCC+: High Precision Congestion Control
In the early days of congestion control signalling, we originally came up with the rather crude ‘Source Quench’ control message, an ICMP control message sent from an interior gateway to a packet source that directed the source to reduce its packet sending rate.
Source Quench was unrelated to the transport protocol that the end host might be using, and intentionally operated at the level of the IP layer within the context of the protocol stack. It was a decent first effort at a rather complex problem, but it was always going to be replaced by successive refinements as we gained experience in this area.
The IETF got around to formally deprecating the Source Quench mechanism in 2012 in RFC 6633, though it had lapsed into disuse around two decades earlier.
Then there was Explicit Congestion Notification (ECN) for TCP (RFC 3168), where a gateway marked one or more packets in a TCP data flow when it was experiencing congestion and the ECN signal was echoed in the reverse TCP ACK packets so that the signal was passed back to the sender. It’s an improvement without doubt, as it allows the sender to respond to the onset of congestion prior to the more disruptive signal of packet drop. At the same time, it’s a single bit signal so the signal can signal the presence of a congestion condition or not, but not much more.
It is always fascinating how we continue to refine silicon in ways previously considered impossible or completely impractical. New commodity ASICs have in-band telemetry ability. This can be used to formulate precise feedback for congestion control. The idea is to replace the coarse single-bit feedback in ECN with more information, including queue length, link capacity, timestamp and similar.
Read: TCP path brokenness and transport layer evolution
Packets in the data forwarding path have switch telemetry attached to the packet by every switch, and this telemetry is copied to the corresponding ACK packet being passed in the reverse direction, as shown in Figure 1. The objective here is to eliminate the extended process of searching for a stable flow profile with a process of rapid adjustment to a desired profile, while at the same time making minimal queue demands as a latency reduction mechanism.
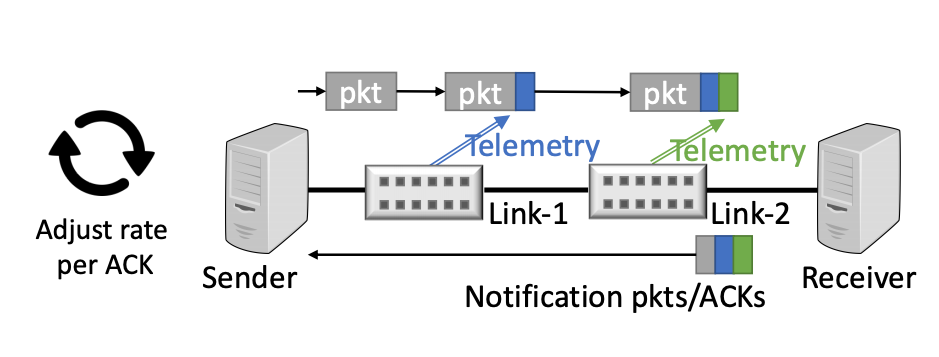
The environment assumed in this work is a data centre where the switching elements in the data centre are all operated by the same party and the packet markings can be trusted, and the end-to-end hop count is limited.
In a more heterogeneous environment, such as the public Internet, this approach has many potential issues, but in a uniform environment where all switching elements can mark packets with current switch characteristics and where the end systems can trust this meta-data, then it is certainly possible for systems to quickly and accurately adjust their sending profile in accordance with their knowledge of the path characteristics.
Qlog
There are many tools for analysis of TCP performance. These tools typically rely on the observation that the TCP flow control parameters (stream sequence number values, window parameters and such) are placed into the TCP packet header in the clear, and an on-path observer can use this information to derive TCP performance.

QUIC is almost entirely encrypted, as shown in Figure 2, and the only way you can perform a similar analysis of transport control performance is to gather the data from the end points and infer flow control state from the data on the endpoints. This would then allow network congestion events to be inferred from this data, and the response from the protocol can be analysed.
This is the intent of the Qlog tool. The tool gathers parameters from the Qlog endpoint logging facility in QUIC stacks and assembles the data to create a state inspection capability that is comparable to the TCP packet capture analysis tools that have been used in ‘open’ TCP for decades, as seen in Figure 3.

I suspect that there is a deeper observation behind this presentation, namely that as we lift functionality in networking away from the common platform, and load up applications with this function, then the only way to obtain visibility on what these applications are doing is to have the ability to interrogate them directly.
MultiPath transport and congestion control
Multipath has been a fascinating area of study. For example, mobile devices often operate with functioning Wi-Fi and cellular radio connections, and the promise of having the transport protocol make use of the paths across both transmission systems has attracted interest from time to time. Sometimes it’s seen as a fast-failover approach, where the data flow uses a single path at any time, but other paths are held in a ready state to be used in the event of a failure of the primary path. In other cases, they are seen as a load balancing approach, where the data flow is spread across both paths.
In TCP, this load balancing and implicit congestion control comes from the independent TCP congestion control algorithms being used on the paths. However, UDP flows are more challenging. The IETF standardized the Datagram Congestion Control Protocol (DCCP) with RFC 4340, allowing a congestion control algorithm to control the UDP packet flow rate for one of more UDP packet flows between the same two endpoints. This work reports on efforts to extend this DCCP approach into the realm of multiple paths.
Read: A new way of measuring QoE using TCP connection establishment delay
DCCP was intended to allow a collection of UDP flows between the same endpoints to behave ‘fairly’ with respect to other simultaneous flows. At its crudest this would impose a rate limit of UDP flows when the network is experiencing congestion, and the rate management would be largely the same as a TCP-controlled flow of a similar flow volume. At the same time, the flow should not be penalized unfairly.
Multipath introduces a further consideration, namely that when a path experiences congestion the multipath control should be able to use alternate paths to maintain the flow where possible. This study suggests that there is a complex set of interaction across a number of factors, including the scheduling and reordering mechanism that is used, the choice of the control congestion protocol used, the placement of functionality of the control proxy, and of course the path characteristics. So far, they have observed that BBR is a better congestion control proxy for MP-DCCP than loss-based control systems such as Reno.
BBR
Work on refinement of BBR continues. BBR is a flow control algorithm that is based on variations in end-to-end delay, as compared to the more ‘traditional’ drop-based flow control algorithms. The initial release of BBR showed the promise of this approach. BBR flow control was able to achieve high throughput with minimal demands on network buffers.
However, it did not play well with others, and it was possible for a BBR flow to starve concurrent loss-based flows of any capacity, or to be locked out by these flows. Subsequent effort has been directed to tune BBR to be a little more sensitive in its adjustment to other flows.
BBRv2 has been deployed within Google for all internal TCP traffic. BBRv2 uses the parameter of the estimated path bandwidth and minimum RTT to determine the point of the onset of queuing, and now incorporates ECN and packet loss as further control signals. They have seen latency reductions at the tail for RPC traffic. As well as for internal traffic, Google are looking at deploying this for YouTube and google.com externally directed traffic, with further measurement and tests underway.
There is an ‘alpha’ release of BBRv2 Linux platforms available at GitHub, rebased to a more recent version of Linux, with a few bug fixes.
The Google group is working on BBR.Swift that leverages the Swift control protocol. Swift uses the network round trip time as the primary congestion signal, which makes the protocol react quickly to the formation of large queues within the network, while being more tolerant of short queues.
As part of this work there is a proposal to include extensible timestamp options for TCP. It’s not yet HPCC++, but the use of timestamps with microsecond granularity, and the inclusion of the delayed ACK processing delay and packet echoing delay would allow a flow controller to make a more accurate measurement of network delay as compared to protocol and host processing delay. Like HPCC++, the underlying notion is that more information about the end-to-end behaviours and the interaction between packets and networks result in more efficient flow control procedures.
QUIC 0-RTT Transport Parameters
There has been much work in so-called 0-RTT TLS connections, where the security association of previous sessions can be used by the same pair of endpoints for a new session. This avoids the repeated set of handshakes for each new secure session.
The concept of storing flow behaviours between a sequential set of flows is nothing new for platforms. Many platform’s implementations of TCP were able to cache the flow control parameters, and when a new session was started then the platform would kick in with the flow parameters from the previous session. The talk at this session of the CCRG proposed to use a similar mechanism for QUIC sessions. I’m not sure there is much that is novel in this work.
This is not the entirety of the IETF work in congestion control, and the TCP Maintenance Working Group (TCPM) session had a number of presentations that are also of interest to congestion control.
Enhancements to ECN
ECN is a marvellously simple — yet elegant — way for the network to signal to the endpoints that the flow is passing through a congestion point (or points). The mechanism, RFC 3168, uses 2 bits of the IP header, where one bit is used to signal ECN capability and the other used to indicate congestion. These bits are echoed back in the TCP ACK packets using two further bits of the TCP header.
Of course, there is a difference between elegant simplicity and crude inadequacy. ECN as, described in RFC 3168, is certainly simple, but is it enough? It can only perform one signal each round-trip time and can only signal the presence of a congestion point, without being able to indicate the number of such points that may exist on a path.
A proposal to augment the ECN mechanism, ‘Accurate ECN’ has been slowly progressing through the TCPM Working Group for the past six years and the working document is now in its 14th revision. The proposal uses a new TCP option to count the number of congestion events in a path and the byte count of traffic that have been impacted.
There is a massive inertia in TCP these days, and proposals to alter TCP by adding new options or changing the interpretation of existing signals will always encounter resistance. It is unsurprising that BBR stayed away from changing the TCP headers and why QUIC pulled the end-to-end transport protocol into the application. Both approaches avoided dealing with this inertial stasis of TCP in today’s Internet.
It may be a depressing observation, but it’s entirely possible that the proposal to change ECN in TCP may take a further five or more years, and a further 14 or more revisions before the IETF is ready to publish this specification as a Standards Track RFC.
As to when this will get widely deployed in the public Internet, well that’s anyone’s guess!
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.