

The question ‘Can machines think?’ was first proposed by Alan Turing 70 years ago. A self-confessed contentious proposition, it nevertheless laid an important foundation for the development of what we know as Machine Learning (ML) and Artificial Intelligence (AI).
It’s incredible to think that both ML and AI are still only in their infancy given the amount of time since their theoretical conception. This, in itself, points to their complexity; a fact that becomes increasingly more apparent once you start to implement them yourself.
In May last year, I contributed a post to this blog providing an overview of a ML project we were starting at Link3 Technologies Limited to find anomalies in DNS traffic. At the time, Link3 served more than 820 million queries a day, from five caching DNS servers, all running IP anycast. This equates to more than 420GB of data a day, and nearly 150TB over the course of a year. These figures have increased by a factor of four since then!
In this post, I want to share an update on the project and discuss why most ML projects don’t see the light of day.
Why do most ML projects fail?
A main reason why it’s taken so long for ML to become feasible is due to a lack of computational power and practical experience in using it.
The tweet below shows an infographic produced by Racounter showing a portion of the incredible sums of data produced each day by a small fraction of web applications and Internet-connected devices.
This incredible amount of data is rather crude in that it requires refining for it to be analysed and understood. This currently requires the help of a team of specialists (people) with a broad range of expertise. For our project, members from our network, security and system teams are working alongside data scientists and specialized ML and software engineers.
Overseeing such a diverse team is no easy task and is one area where I feel there is a shortage of expertise; it’s difficult for one person to have expertise across all fields. In our case, do we hire a great ML engineer or a data scientist to lead the project even though they don’t know how the DNS infrastructure works, what network traffic is or what cyber attacks look like? Or vice versa?
This is an important question to ask yourself before you invest in an ML-based project.
Understanding the ML pipeline
The DNS is a core component of the Internet’s infrastructure, which makes it a prime target for malicious actors. According to Cisco’s Annual Security Report, 92% of malware uses DNS in one of three ways: to gain command and control, to ex-filtrate data, or redirect traffic.
As I mentioned in my last post on the project, we’re exploring how to use ML to more effectively scan the huge amounts of DNS data (NetFow traffic) that we collect.
There are three branches in ML: supervised learning, unsupervised learning, and reinforcement learning.
We’re concentrating on supervised learning because it is about classifying the data, based on the labelled data frame. Below is a simple flow diagram showing the process of our ML pipeline:
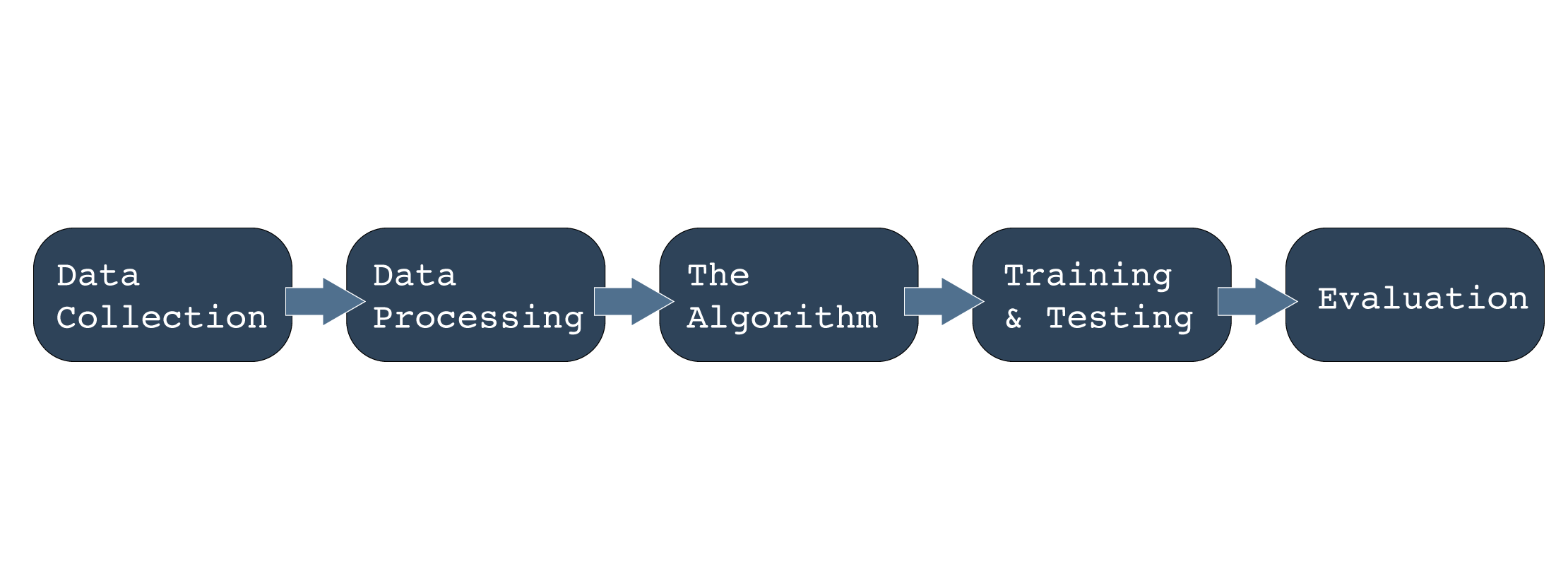
We first collect the data from the NetFlow collector.
This is followed by processing, which involves removing the noise, like open DNS resolver data, and normalizing and labelling the data. Out of 15 features in the NetFlow data, we select only seven of them to focus the ML model’s dominance. Further to this, we use string-based labelling to define the data set’s class, based on the features and attack vector.
As for the algorithm, we are using the K-Nearest Neighbors (kNN), which is defined as “if you are similar to your neighbours, then you are one of them.” In our case, we are looking for anomalous data that is not similar to our labelled (neighbour) one. This involves using a collection of tools: Jupiter-notebook, which has the standardized steps predefined; Pandas and NumPy for working on the data frame and preprocessing the data with standard-scaler; and Scikit-Learn for mining and analytics.
As part of training and testing we use the confusion-matrix to evaluate the performance of the existing datasets. Based on the outcome, we perform the test on new data and fine-tune the model based on the evaluation process, redefining the data frame accordingly and repeating the same steps for all the original datasets. We are mostly using kNN and SVM for these tasks.
At the evaluation stage, it’s important to note that accuracy is not what you should be focusing on; rather the F1-score is more important. ML engineers use accuracy when the true-positives and true-negatives are important, and the F1-score for false-negatives and false-positives. In most use-cases, class distribution is not evenly managed in a given data frame, and the F1-score works fine when the class distribution is imbalanced.
Finding anomalies from NetFlow data is no easy task
Analysing the terabytes of runtime, requires immense computational power, and the infrastructure has to be designed to host that big data.
We started the project last year in offline mode with supervised learning and are now evaluating this task on reinforcement learning. This has involved designing a Hadoop-based cluster, which has been another challenge and story for another time. Until then feel free to ask any questions in the comment section below. Please share your experience with anomaly detection and check out my tutorial ‘Can Artificial Intelligence secure your infrastructure‘, which I presented at APRICOT 2020.
In summarizing the process, I hope you get a greater understanding of what’s required with implementing ML to assist with detecting anomalies in DNS traffic.
A S M Shamim Reza is Deputy Manager of the NOC team at Link3 Technologies Limited.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
yes it’s really good to know new concept of Machine Learning. Plz keep it up
Great bro…..Hopefully we will get another thriller post !
Very informative concept about Machine learning.
Great Writing. Informative and effective
Prodigious thinking and also very upright writing. Hope you will be able to get more particulars from your research.
Thanks a lot. Will try to give more insights on another day.