

These days it seems that whenever we start talking about the DNS, the conversation immediately swings around to the subject of DNS over HTTPS (DoH) and the various implications of this technology in terms of changes in the way the DNS is used.
It’s true that DoH is a rich topic space and while much has been said and written already, there is still more to say (and write). But that’s not my intention here. I’d like to look at a different, but still very familiar and somewhat related, topic relating to the DNS, namely how IPv6 is being used as a transport protocol for DNS queries.
Before I set out the questions that I want to consider here, it’s useful to remember why we are deploying IPv6 in the first place.
IPv6 is not intended to sit alongside IPv4 in a dual-stack situation as the end objective of this transition process. A fully deployed dual-stack world is not the goal here. We need to push this transition process one step further, and the objective is to get to the point where IPv4 is not only no longer necessary, but no longer used at all. In other words, we are attempting to get to the point where IPv6-only services are not only a viable way of using the Internet but are the only way of using the Internet.
One of the key elements in the overall transition is how we manage a dual-stack networked environment. The basic approach is to bias the choice of IP protocol towards IPv6 when both protocols are viable for a connection. In the context of browser behaviour, we call this preference to use IPv6 ‘Happy Eyeballs’, where the client and the server are both operating in a dual-stack mode, they should prefer to communicate using IPv6.
Read: Happy Eyeballs – promoting a healthy IPv4 and IPv6 coexistence
The theory is that the combination of this preference and the increasing adoption of dual-stacked environments is that the use of IPv4 automatically diminishes as the dual-stacked world becomes more pervasive. We won’t need to ‘turn off’ IPv4 at any particular point as this preferential process will cause the use of IPv4 to disappear quite naturally. But while this preferential protocol behaviour is used in several browsers, it’s not necessarily used in other applications and infrastructure services.
The larger question of IPv6 transition is more than browsers, and we should look more broadly at the use of IPv6. This includes an examination of the DNS and its use of IPv6 as the transport protocol for UDP and TCP.
To answer the question of how well IPv6 is supported in the DNS today, three aspects need to be examined:
- How does the DNS handle dual-stacked authoritative servers? Is there a Happy Eyeballs version of DNS server selection? Or is there a reverse bias to use IPv4?
- If you placed authoritative servers on an IPv6-only service how many users would be able to reach you?
- And what about DNSSEC? How well does IPv6 support large UDP packets?
Challenges in measuring the DNS
Before looking at the measurements that can answer these questions it might be useful to remember that the DNS is very challenging to measure.
When we say that ‘some proportion of the DNS exhibits some particular behaviour’, are we talking about DNS resolvers? Or maybe we are referring to a proportion of observed queries? Or perhaps to an inferred set of end systems, or even end-users? Each of these presents some issues in definition and interpretation.
Resolvers?
We really don’t understand what a resolver is in the context of a measurement.
A DNS resolver might be a single instance of resolver software running on a single host platform. But it also might be a single front-end client-facing system that accepts DNS queries and uses a query distributor to pass the query onto one (or more) ‘back-end’ resolvers that perform the actual DNS resolution function. Each of these DNS resolver engines could operate autonomously, or they could be loosely coupled with a shared cache. The system might also use a collection of these ‘server farms’ all configured behind a single anycast front end service address.
There are various types of resolvers, including stub resolvers, that are typically part of end-host systems. There are forwarding resolvers that pass queries on to other resolvers, as well as recursive resolvers that attempt to perform a full resolution of a DNS name.
A resolver might have a single user as a client, or at the other end of the range it may have millions or even billions of end-users as clients, and of course, there are many resolvers in between these two extremes.
Claims such as ‘30% of resolvers show some particular behaviour’ are essentially meaningless statements given that there is no clear concept of which resolvers are being referred to, and how many users are impacted by whatever behaviour is being referenced.
When we talk about resolvers in the context of measurement it is unclear what we might be referring to!
Queries?
Again, it might sound odd, but we really don’t know what a query is.
An end-client might generate a single DNS query and pass it to a resolver. But that query may cause the resolver to generate further queries to establish where the zone cuts exist corresponding to delegations and the addresses of the authoritative name servers for the DNS zone, and possibly further queries if the resolver performs DNSSEC validation.
Before QNAME minimisation, a resolver would pass the full query name to each resolver when performing this top-down zone cut discovery, and there is no essential difference between these discovery queries and the ultimate query. The essential characteristic of the DNS is that a single DNS query may generate a cascade of queries to amass sufficient information to generate a response to the original query. Viewed from the ‘inside’ of the DNS it is impossible to distinguish between what could be called ‘discovery’ queries and the ‘original’ query, whatever that might be.
Resolvers all use their own timers, and if they do not receive a response within the local timer period the resolver may generate further queries, both to the same resolver and other resolvers. There is also a DNS error code that may cause a re-query, namely the SERVFAIL response.
DNS queries have a no hop count attribute nor any resolution path attribute, so queries have no context that will provide the reason why a resolver has generated a DNS query, nor provide any indication of what the root cause original query may have been.
It appears that queries have a life of their own, and while there is some relation to user and application activity it is by no means an exclusive relationship, and DNS queries are often made without any such triggering event.
Statements such as ‘30% of queries have some particular property’ are again somewhat meaningless as a measurement statement given that there are many forms of queries and many potential causes for such queries to be generated.
Once more, it appears to be the case that when we talk about queries in the context of measurement it is unclear what we actually mean.
APNIC Labs measurements
At APNIC, we use a measurement system that is based on measuring end-user behaviours rather than infrastructure behaviours. To do this, it uses online advertisements to distribute a client-side measurement script. The platform is capable of ‘seeding’ the DNS with queries that use unique labels, and we observe the queries that are placed with the measurement platform’s authoritative servers in response. We can then correlate end-user activities and authoritative server query activity and measure the DNS in terms of users and behaviours (Figure 1).
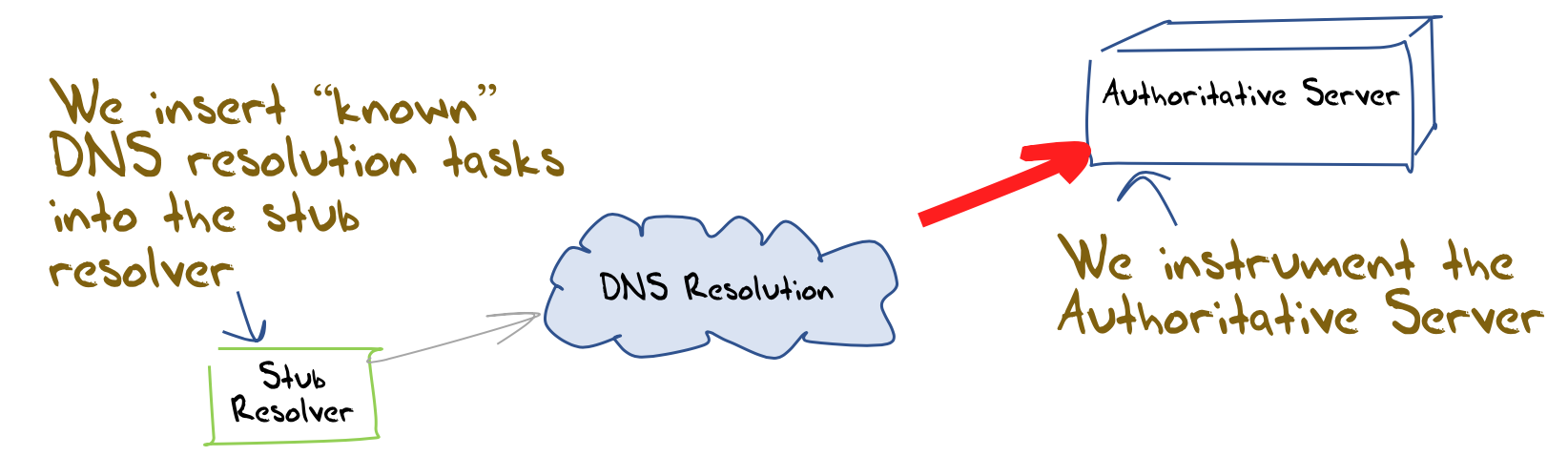
This measurement system intends to measure a particular behaviour or property by measuring its visibility to users. We want to understand to what extent users are impacted by a particular behaviour or property of the network infrastructure.
In this exercise of measuring IPv6 in the DNS, we will be looking at the DNS and measuring the population of users that generate DNS activity over IPv6.
DNS Happy Eyeballs?
So, how does the DNS handle a dual-stack environment? Do we observe a Happy Eyeballs preference to use IPv6? Or is there a reverse bias to prefer to use IPv4?
In this case, we are looking at the interaction between the user’s recursive resolvers and authoritative servers. In this measurement experiment, the authoritative server was configured to respond to DNS queries over both IPv4 and IPv6 and the address records for the delegated authoritative server had both IPv4 and IPv6.
For each execution of the measurement script on an end-user client device, we examined the collection of DNS queries and looked at the protocol used to perform the query. Some experiments generated a single query, while others generated multiple queries. We sorted the experiments into three categories:
- Experiments where all the queries between the visible recursive resolver and the authoritative server were made using IPv6.
- Experiments where all the queries were made using IPv4.
- Experiments where we observed queries for the DNS name made over both protocols.
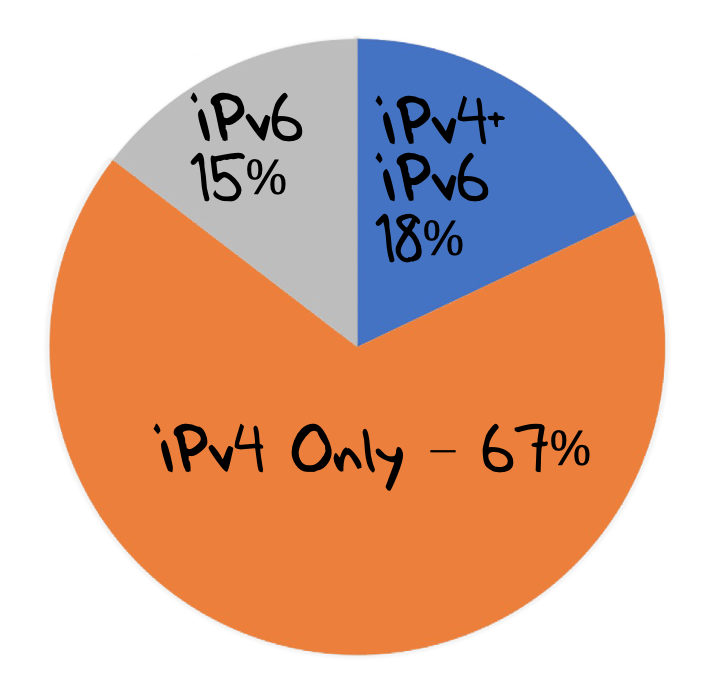
The data collected over the last week in April 2020 (Figure 2) shows that 15% of tested end-users used recursive resolvers that only used IPv6 to query the experiment’s authoritative servers. A further 18% used multiple queries that used both IPv4 and IPv6 to make these queries. The remaining 67% used only IPv4 in their queries as seen at the authoritative server.
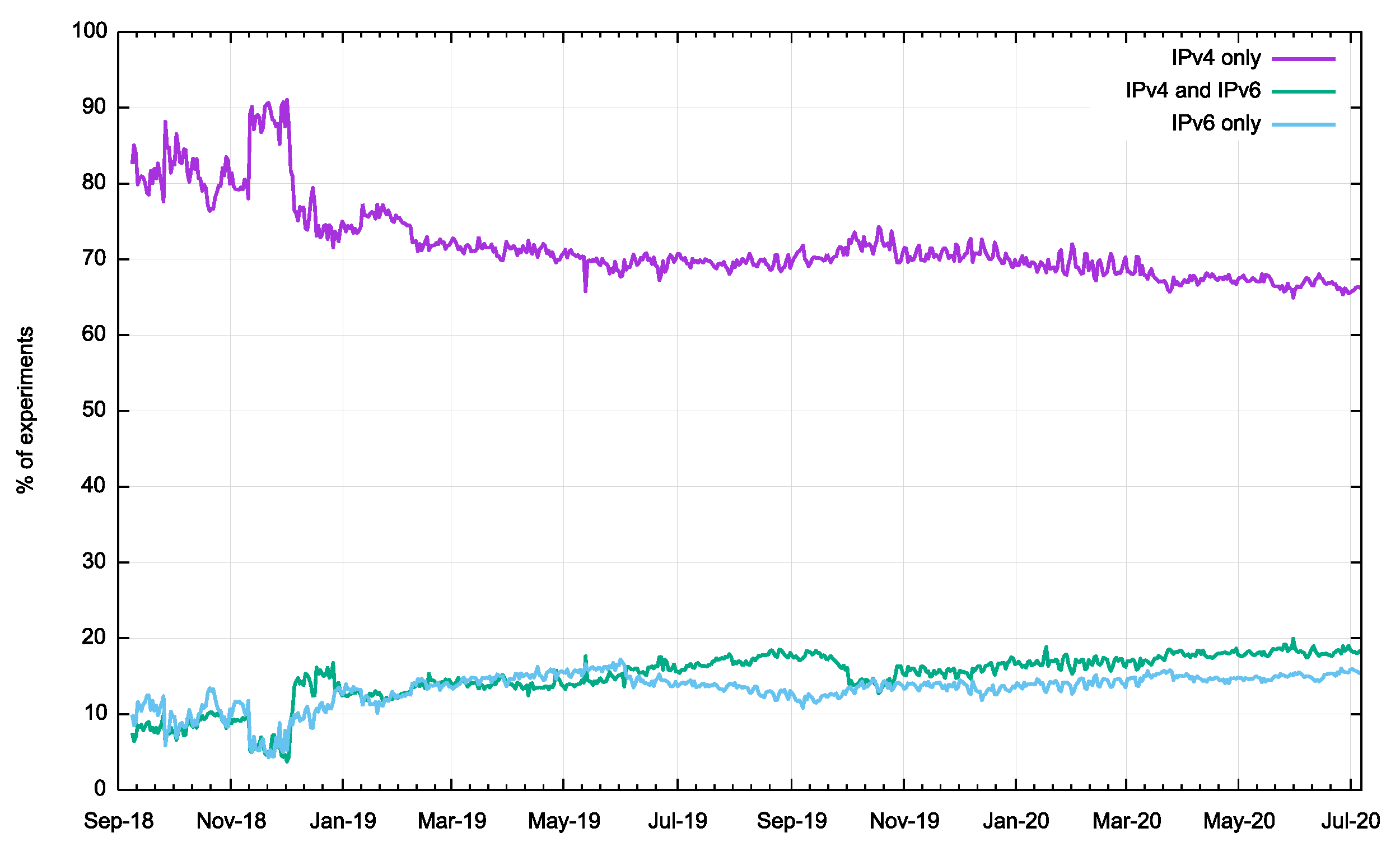
We can look at this data over time, looking the same data for the past 22 months on a day-by-day basis (Figure 3).
Over this period, the proportion of users behind resolvers using only IPv4 has fallen from 80% to 67%. At the same time, the proportion of IPv6-only activity rose from 10% to 15%.
Where we see both IPv4 and IPv6 queries in the same experiment we’ve split them to show which protocol was used for the first query (Figure 4).

What this shows is that where we see cases of both IPv4 and IPv6 queries, there is a constant but relatively small bias to use IPv4 for the initial query.
We can now provide an answer to the first of our questions: the DNS does not prefer to use IPv6 in dual-stack situations. There is no Happy Eyeballs for the DNS. But there is small but visible reverse-bias where IPv4 is favoured over IPv6 in a small number of cases where both protocols are observed in queries.
IPv6-only DNS servers
The data in Figure 3 indicates that 67% of users sit behind DNS resolvers that send queries to authoritative servers using IPv4-only. That might lead to an inference that if we were to set up a server on an IPv6-only platform then only some 43% of users would be able to resolve DNS names that are served from this server.
However, when we set up an IPv6-only experiment in parallel to the dual-stack experiment the results are somewhat different. Using the same measurement framework and the same set of end-users for the measurement, we can also direct users to a URL where the only way to access the server of the DNS label is using IPv6. Of all the end clients who are presented with such a URL — in this case, some 45M clients over a 5-day period at the start of July 2020 — around 55% of these users are using DNS resolvers that can make a DNS query using IPv6 (Figure 5).
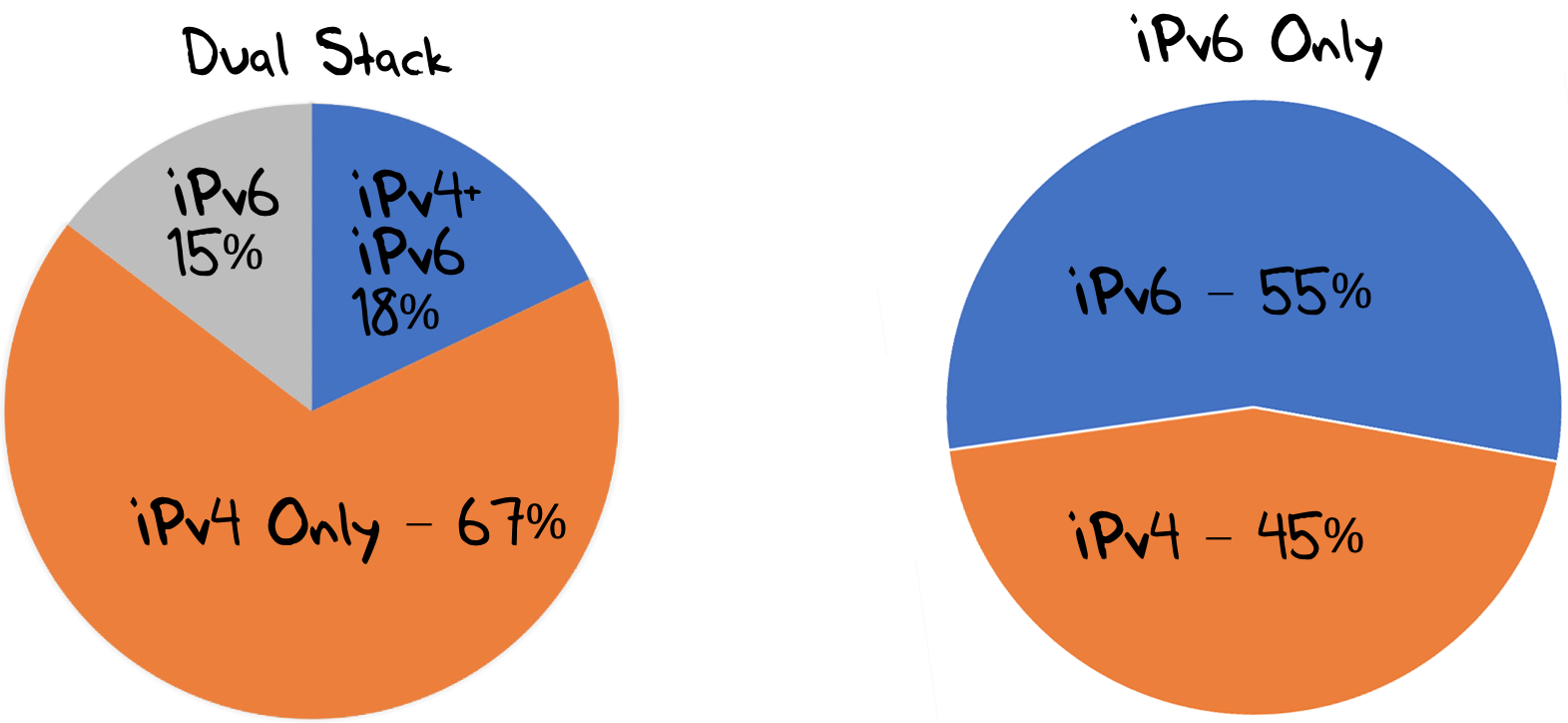
Given that the level of IPv6 capability in the end-user population as a whole in July 2020 is some 25%, the DNS IPv6 measurement of 55% is certainly an encouraging level of progress in the adoption of IPv6 capability in DNS infrastructure.
Therefore, the current answer to our second question — If you placed authoritative servers on an IPv6-only service how many users would be able to reach you? — is 55% of users.
Large DNS packets and IPv6
The final question concerns large packets in the DNS. This is relevant when considering the use of DNSSEC, where a DNS response may contain the digital signature of the DNS data as well as the data itself, and this can have an impact on DNS responses sizes.
By default, the DNS is a UDP-based protocol. The transactional nature of the DNS protocol seemed to be a perfect fit for UDP. However, there are limitations in datagram-based services, particularly as they relate to larger payloads. Fragmentation is an unreliable measure.
The lack of transport protocol headers in trailing fragments creates a quandary for firewalls. Admitting trailing fragments admits the possibility of several attack vectors, while discarding them may disrupt a service.
The DNS adopted a very conservative position in UDP. A DNS response over UDP is no longer than 512 octets. If the response is larger than this size, the DNS response packet is truncated such that it is no larger than 512 octets, and the truncation bit is set in the response to flag the fact that the response has been truncated. A DNS resolver should treat this truncation bit as a signal to re-query the server using TCP so that the larger response can be handled by TCP.
If we had stuck to this original approach to handing DNS over UDP then large UDP packets wouldn’t present a problem for the DNS. But the extended time needed to discover that TCP is necessary and then setting up a TCP session to re-query the server imposes a time penalty on the client and a load penalty on the server. If the major motivation for supporting large DNS responses was concentrated in the need to support DNSSEC, then it’s likely that DNSSEC would never have been deployed under such conditions.
What we did instead was to include an extension option in the DNS query to allow the client to inform the server that a large UDP response can be handled by the client. The Extension Mechanism for DNS (EDNS(0), RFC 6891) includes a UDP buffer size option that informs the server of the size of the client’s maximum UDP receiver buffer. This option allows the server to send UDP responses up to this size without truncation.
Of course, the problem is that neither the client nor the server necessarily knows the characteristics of the path from the server to the client. In IPv4 it is possible for the packet to the fragmented while in flight so this issue of path MTU mismatch is not a forbidding concern. But IPv6 does not have fragmentation on the fly. The router that cannot forward the large IPv6 packet is supposed to send an ICMPv6 PacketTooBig message back to the packet’s source address. But this is UDP, so the source has no retained record of the packet and cannot resend the packet in smaller fragments. The transport layer of the host can do nothing to salvage the situation. It’s largely left to the application to try and climb out of this hole though application timeouts. It’s an unsatisfying solution.
But the IPv6 problems with packet fragmentation don’t stop there. The IPv6 protocol design uses the concept of variable extension headers that are placed between the IP header and the UDP header. This means that the UDP transport header is pushed back deeper into the packet.
Now the theory says that this is irrelevant to the routers in the network as the network devices should not be looking at the transport header in any case. The practice says something entirely different.
Many paths through the Internet today use load distribution techniques where traffic is spread across multiple carriage paths. To preserve the order of packets within each UDP or TCP flow the load distributor typically looks at the transport header to keep packets from the same flow in the same path. Extension headers and packet fragmentation make this a far more challenging task to perform at speed as the transport header is no longer at a fixed offset from the start of the header, but at a variable location based on unravelling the extension header chain. Some network devices push such packets away from the ASIC-based fast path and queue them up for CPU processing. Other devices simply discard IPv6 packets with extension headers.
It appears that UDP packet fragmentation and IPv6 don’t go well together. So perhaps we should just avoid large fragmented DNS packets altogether. However, it’s easy to find large DNS responses in UDP.
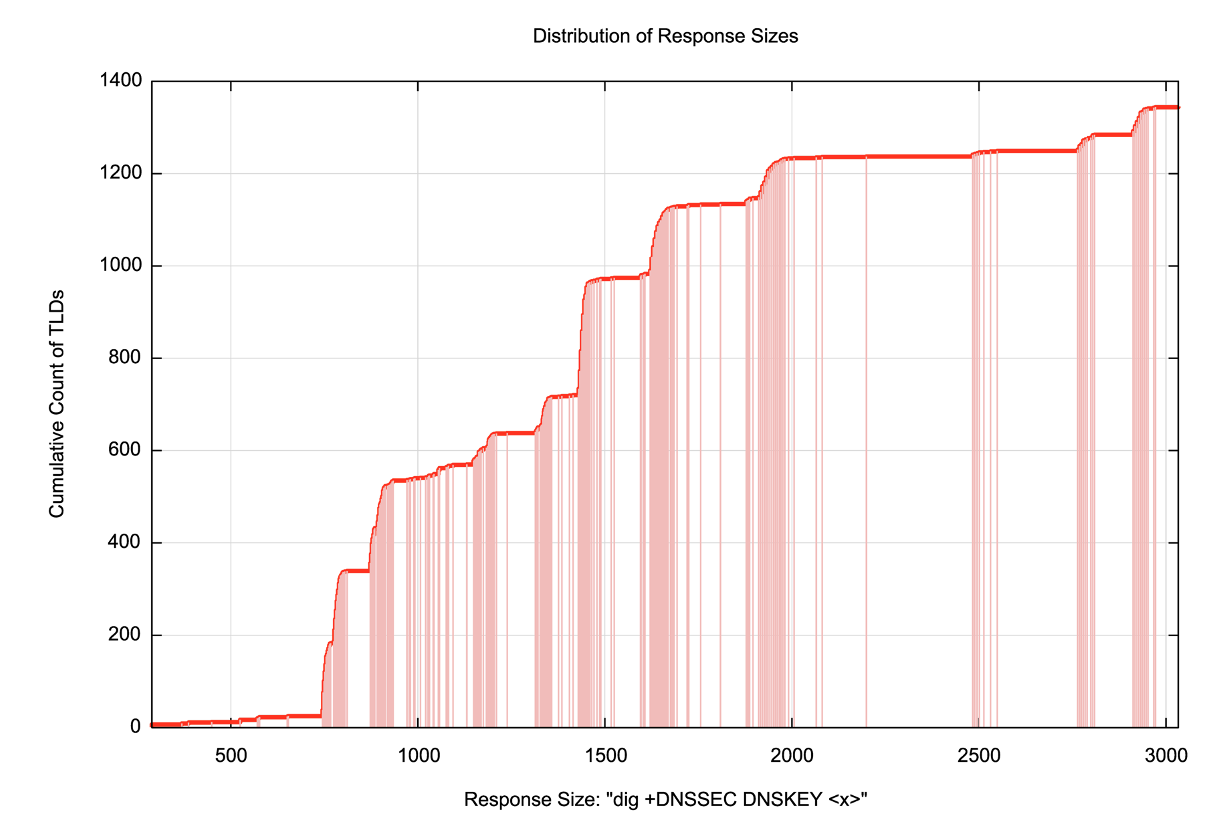
In the past, I always liked to use the .org domain as the classic illustration of a fragmented UDP packet. Whenever you queried the .org servers for the DNSKEY record of the domain, with the DNSSEC OK flag turned on, the signed response was 1,625 octets:

However, that was back in 2017, and these days a similar query generates a response of just 1,058 octets. With my favourite example now ‘fixed’ I’ve had to look further afield for large DNS responses that force UDP fragmentation to happen. Thankfully, the DNS root zone is still full of such domains. Here’s the largest of the DNSSEC-signed responses to a query for the DNSSEC field of entries in the root zone:
| .booking | 2,932 |
| .winners | 2,932 |
| .watches | 2,932 |
| .ferrero | 2,932 |
| .lincoln | 2,932 |
| .chintai | 2,932 |
| .citadel | 2,932 |
| .oldnavy | 2,932 |
| .banamex | 2,932 |
| .farmers | 2,932 |
| .athleta | 2,932 |
| .jpmorgan | 2,937 |
| .discover | 2,937 |
| .homegoods | 2,942 |
| .marshalls | 2,942 |
| .analytics | 2,942 |
| .homesense | 2,942 |
| .statefarm | 2,942 |
| .swiftcover | 2,947 |
| .xn—kpu716f | 2,952 |
| .weatherchannel | 2,967 |
| .bananarepublic | 2,967 |
| .americanexpress | 2,972 |
| .gdn | 3,033 |
Some 1,420 labels in the root zone (which has a little under 1,350 DNSSEC-signed entries) generate UDP responses larger than 1,500 octets, which inevitably will be fragmented (Figure 6).
_
It is evident that large DNS responses, UDP and IPv6 may encounter problems when used together. Can we quantify these problems? If an authoritative name server is only accessible using IPv6 and the server’s responses are all larger than 1,500 octets, so they will all be fragmented, then what proportion of users will be impacted?
How can we tell whether a DNS response was received or not?
There are many ways to do this if you have full control of the end systems, but, in our context, we have a very limited repertoire of instructions. We can request that the end client fetches a URL and we can get the client to report on the success or otherwise of this operation. And that’s about it! We can get the client to use one of ‘our’ domain names, and if the name is unique then we will see the query at our authoritative name server, but we can’t tell directly if the client received the response.
The way we perform this measurement is to create a short sequence of DNS queries, where within the sequence the next query is made only if it received a response from the previous query. The DNS behaviour we leverage for this is the DNS discovery process.
This process starts with a query to the root servers, and the response lists the servers for the relevant top-level domain and their IP addresses. It then asks one of these servers and the response will indicate the servers for the next level down, and so on. (Thankfully, caching means that a resolver will not perform most of these queries most of the time.)
If the IP addresses are not included in the responses to these discovery queries, then the resolver will have to pause the original discovery process and commence a new discovery process to discover the IP address of one of these servers. If this task completes then the resolver will recommence the original discovery task.
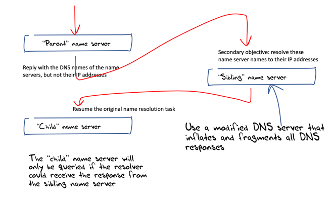
This allows us to determine if a particular DNS response is received or not (Figure 7).
In a measurement performed at the end of April 2020, we performed this experiment some 27M times and observed that in 11M cases the client’s DNS systems did not receive a response. That’s a failure rate of 41%.
And that’s the answer to our third question — How well does IPv6 support large DNS responses? — not well at all, with a failure rate of 41% of user experiments.
What to do?
If we accept the prospect of an IPv6-only Internet, we are going to have to take DNS over IPv6 far more seriously than we are doing now.
Today the dual-stack Internet comes to the rescue and what does not or cannot happen in IPv6 is seamlessly fixed using IPv4, but that’s not a course of action that will be sustainable forever. We really need to address this appalling packet drop rate for fragmented IPv6 packets in the DNS, and on all end-to-end IPv6 paths in the Internet. Our choices are to either try and fix this problem in the switches in the network or alter end systems and applications to simply work around the problem.
As ever, it’s always amusing to consult the RFC document series to see what advice others are offering. In March 2017, the IETF published RFC 8085, with the grandiose title of “UDP Usage Guidelines”:
“Applications that do not follow the recommendations to do PMTU/PLPMTUD discovery SHOULD still avoid sending UDP datagrams that would result in IP packets that exceed the path MTU. Because the actual path MTU is unknown, such applications SHOULD fall back to sending messages that are shorted that the default effective MTU for sending (EMTU_S in RFC 1122). EMTU-S is the smaller of 576 bytes and the first-hop MTU [RFC 1122]. For IPv6 EMTU-S is 1280 bytes [RFC 2460].”
RFC 8085 “UDP Usage Guidelines”
Well, that seems to be clear — for the DNS over UDP, this RFC is suggesting that the DNS should not use EDNS(0) UDP buffer size, and DNS implementation should keep all UDP DNS packets below 512 octets if it wants to operate consistently over both IPv4 and IPv6.
But there is still some residual uncertainty here. Is this about the IPv6 manner of IP packet fragmentation, or about the more general matter of the use of extension headers in IPv6? The lingering suspicion is that while packet fragmentation has issues, IPv6 extension headers are their own problem, and we might want to avoid IPv6 extension headers completely!
What can we do about this?
It seems to be too late to change the protocol specification of IPv6 and re-think the way extension headers are handled in the protocol header of IPv6 packets.
It seems too challenging to change the hardware design process and process packets with extension headers at high speed inside dedicated ASICs in network equipment. Variable-length fields in packet headers ask too much of the deployed packet processing equipment. If the trade-off here is between high capacity and high speed on the one hand and support of IPv6 extension headers on the other, then extension headers have to go the same way as the IPv4 header options. They’re gone.
Unfortunately, by writing off IPv6 extension headers as unsupportable we’ve also written off IP level packet fragmentation in IPv6. The pragmatic observation is that the maximal packet size that can be reliably passed in IPv6 is 1,280 octets or a UDP payload of 1,232 octets. The implication for the DNS is that if we can’t stuff arbitrarily large payloads into UDP DNS packets in IPv6, and we don’t want to pay the time penalty of sending the query over UDP (and waiting for a truncated UDP response to trigger a subsequent query over TCP) then what other options are open to us?
We could drop DNS over UDP completely and shift DNS to use TCP only. When this option has been aired in networking circles reactions have been mixed. Some observe the current profile of small TCP transactions in the web and pose the question of why the DNS folk should think that what the web folk are already doing is so hard! Others look at the additional time and load overheads of maintaining TCP state in resolvers and confidently predict the collapse of the DNS if we shifted the entirety of the DNS to TCP.
Variants of this approach include DNS over TLS over TCP (DoT), or DNS over HTTPS (DoH) (which itself is TLS over TCP). Even DNS over QUIC (which is in effect DNS over HTTPS over TLS over TCP over payload encrypted UDP) and the issues with all of these approaches are largely the same as with DNS over TCP. Some folk believe that the shifting patterns of web usage point to the viability of this as an option for the DNS while others equally confidently predict the demise of the DNS if we head down this path.
Is there a middle ground here? Could we add path MTU discovery to UDP? It’s certainly possible, but at that point, the time penalties for the client are potentially worse than just using TCP, so there seems to be little value in that approach.
I always liked Additional Truncated Response (ATR) as a hybrid response. The idea is simple: when a server sends a fragmented response over UDP, it sends an additional UDP packet following the response, namely a response with an empty response section and the truncation bit set. If the fragmented response is lost the unfragmented truncated answer will follow.
Read: How well does ATR actually work?
We measured the effectiveness of this approach in 2018. The conclusion was that in 15% of cases the ‘fast’ signal to use TCP would improve the client experience.
However, ATR has not gained popular acceptance in the DNS implementors’ world so far, and at the same time as ATR was floated the ‘DNS Camel’ conversation had taken hold in the DNS community. That conversation asserts that the DNS is now so heavily ornamented with hacks, exceptions, special cases and features that the result is all but unsustainable. Invoking the DNS Camel is the same as saying that we should avoid adding further bells and whistles to the DNS.
Read: The DNS Camel…
The problem is that we can’t have it all. If the underlying IP and transport protocol cannot manage packetization effectively (and packet fragmentation falls into this category) then it’s left to the application to patch up the problem for itself. The DNS can’t just throw the problem of substandard support for large packets back to the network and transport layers and just simply wish it away. IPv6 is not going to get any better in this respect, so the DNS itself has to adapt to this reality, camels or not.
Where now?
It seems that we now have a pretty decent idea of the problem space with DNS over IPv6 and we know what we would like to solve. How to solve these issues is now the question.
Poor experiences with orchestrated changes and ‘flag days’ lead to a strong preference for a plan that allows every service operator to work independently in an uncoordinated manner.
We are pretty sure that it’s not feasible to clear out the various ICMPv6 packet filters, the IPv6 extension header packet droppers and the aggressive fragmentation filters in today’s network. It’s also out of the question to contemplate changes to the IPv6 protocol and the format of the packet header.
All that’s left for us, if we want to make DNS work effectively and efficiently over IPv6, is to change the way the DNS behaves.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Why do some top-level domains have large dnssec-signed responses while others don’t? Are such large responses actually necessary, or do those domains gain something from it? Is there no way to keep dns udp packets within 1280 octets all the time while using dnssec?
If the answer to the last question is no, then maybe it really is time for a whole new DNS protocol. If it’s well engineered and if you give it a catchy name like DNS2 or DNSv6 and market it as DNS for the 21st century, it might actually succeed.
The larger responses have lined up a number of DNSKEY RVs in their zone. The largest, .gdn uses two ZSKs and 2 KSKs, and signs the DNSKEY RR with 3 signatures.
It’s hard to guess what’s going on, but the most likely explanation would be a poorly configured signing service, hardware or software that has lined up too many keys. More keys and more sigs does not make a zone more secure!
There is a way to limit the size of DNSSEC responses, and the Elliptical Curve algorithm is a good candidate, I tested ECDSA P-256 some years ago and found that is was pretty much universally accepted across the Internet. ECDSA is a “denser” crypto algorithm and it is a lot easier to generate small responses as long as you a) sign the zone with a single ZSK and b) roll the ZSK and KSKs at different times.
The ECDSA report can be found at: https://www.potaroo.net/ispcol/2018-08/ecdsafin.pdf