

Last week, I attended my first Internet Engineering Task Force (IETF 101) meeting in person. Although I’ve been active in several IETF Working Groups (WGs) for nearly 20 years, I had never bothered to show up in person. I now realize this was a very big mistake – I thoroughly enjoyed meeting an extremely high concentration of capable and committed people. While RIPE, various NOGs/NOFs and DNS-OARC are great venues as well, nothing is quite the circus of activity that an IETF meeting is. Much recommended!
Soon, only 20 people will completely understand the massive complexity of the dns. @PowerDNS_Bert at #ietf101 pic.twitter.com/M87isbr5S0
— ISC (@ISCdotORG) March 20, 2018
Before the meeting, I read up on recent DNS standardization activity, and I noted a tonne of stuff was going on. In our development work, I had also been noticing that many of the new DNS features interact in unexpected ways. In fact, there appears to be somewhat of a combinatorial explosion going on in terms of complexity.
As an example, DNAME and DNSSEC are separate features, but it turns out DNAME can only work with DNSSEC with special handling. And every time a new outgoing feature is introduced, for example, DNS cookies, new probing is required to detect authoritative servers that get confused by such newfangled stuff.
This led me to propose a last-minute talk to the DNSOP Working Group, which I tentatively called ‘The DNS Camel, or, how many features can we add to this protocol before it breaks’. This ended up on the agenda as ‘The DNS Camel’ (with no further explanation), which intrigued everyone greatly. I want to thank DNSOP chairs Suzanne and Tim for accommodating my talk, which was submitted at the last moment!
Note: My ‘DNS is too big’ story is far from original! Earlier work includes ‘DNS Complexity’ by Paul Vixie in the ACM Queue and RFC8324 ‘DNS Privacy, Authorization, Special Uses, Encoding, Characters, Matching, and Root Structure: Time for Another Look’ by John Klensin. Randy Bush presented on this subject in 2000 and even has a slide describing DNS as a camel!
Based on a wonderful chart compiled by ISC, I found that the DNS is now described by at least 185 RFCs. Some shell-scripting and HTML scraping later, I found that this adds up to 2,781 printed pages, comfortably more than two copies of ‘The C++ Programming Language (4th edition)’. This book is not known for its brevity.
 Figure 1: Artist impression of DNS complexity over time
Figure 1: Artist impression of DNS complexity over time
In graph form, I summarized the rise of DNS complexity as above. My claim is that this rise is not innocent. As DNS becomes more complex, the number of people that ‘get it’ also goes down. Notably, the advent of DNSSEC caused a number of implementations to drop out (MaraDNS, MyDNS, for example).
Also, with the rise in complexity and the decrease in the number of capable contributors, the inevitable result is a drop in quality:
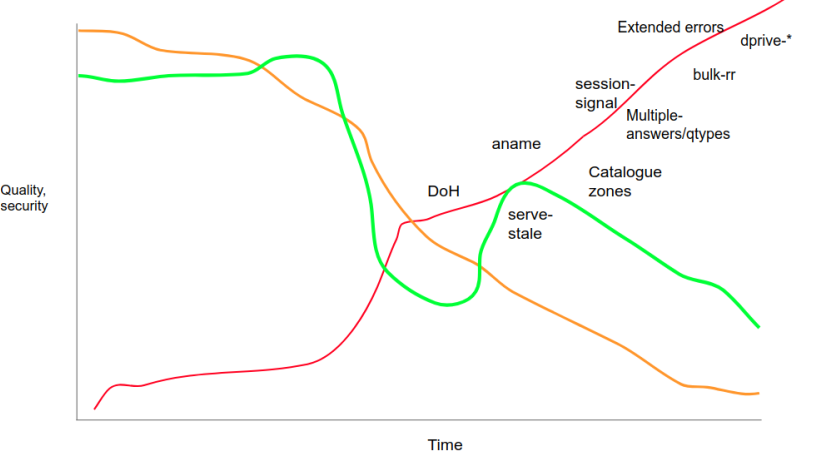 Figure 2: Graph showing the number of people that ‘get it’ (orange), the perceived implementation quality (green) and a list of work in the pipeline.
Figure 2: Graph showing the number of people that ‘get it’ (orange), the perceived implementation quality (green) and a list of work in the pipeline.
And in fact, with the advent of DNSSEC, this is what we found. For several years, security and stability bugs in popular nameserver implementations were absolutely dominated by DNSSEC and cryptography-related issues.
We are heading for that territory again
So how did this happen? We all love the DNS and we don’t want to see it harmed in any way. Traditionally, protocol or product evolution is guided by forces pulling and pushing on it.
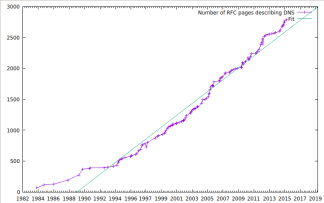
The actual number of RFC pages over time – this number grows at around two pages/week. Note that Shutdown of DNSEXT is barely visible.
Requirements from operators ‘pull’ the DNS in the direction of greater complexity. Implementors meanwhile usually push back on such changes because they fear future bugs, and because they usually have enough to do already. Operators, additionally, are wary of complexity: they are the ones on call 24/7 to fix problems. They don’t want their 3am remedial work to be any harder than it has to be.
Finally, the standardization community may also find things that need fixing. Standardizers work hard to make the Internet better (the new IETF motto I think), and they find lots of things that could be improved – either practically or theoretically.
In the DNS world, we have the unique situation that operator (resolver) feedback is largely absent. Only a few operators manifest themselves in the standardization community (Cloudflare, Comcast, Google, and Salesforce being notably present). Specifically, almost no resolver operator (access provider) ever speaks at WG meetings or writes on mailing lists. In reality, large-scale resolver operators are exceptionally wary of new DNS features and turn off whatever features they can to preserve their night-time rest.
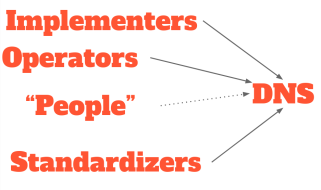
On the developer front, the DNS world is truly blessed with some of the most gifted programmers in the world. The current crop of resolvers and authoritative servers is truly excellent. The DNS may well be the best-served protocol in existence today.
This high level of skill also has a downside. DNS developers frequently see immense complexity not as a problem but as a welcome challenge to be overcome. We say ‘yes’ to things we should say ‘no’ to. Less gifted developer communities would have to say no automatically since they simply would not be able to implement all that new stuff. We do not have this problem. We’re also too proud to say we find something (too) hard.
Finally, the standardization community has its own issues. A ‘show of hands’ made it clear that almost no one in the WG session was actually on call for DNS issues. Standardizers enjoy complexity but do not personally bear the costs of that complexity. Standardizers are not on 24/7 call as there rarely is a need for an emergency 3am standardization session!
Notably, a few years ago I was informed by RFC authors that ‘NSEC3’ was easy. We in the implementation community, meanwhile, were pondering that the ‘3’ in NSEC3 probably stood for the number of people that understood this RRTYPE! I can also report that as of 2018, major DNSSEC validator implementations still encounter NSEC3 corner cases where it is not clear what the intended behaviour is.
Note that our standardizers, like our developers, are extremely smart people. This, however, is again a mixed blessing — this talent creates, at the very least, an acceptance of complexity and a desire to conquer really hard problems, possibly in very clever ways.
The net result of the various forces on the DNS not being checked is obvious — more and more complex features.
Orthogonality of features
As noted above, adding a lot of features can lead to a combinatorial explosion. DNSSEC has to know about DNAME. CZNic contributed the following gem they discovered during the implementation of ‘aggressive NSEC for NXDOMAIN detection’: it collides with Trust Anchor (TA) signalling. The TA signalling happens in the form of a query to the root that leads to an NXDOMAIN, with associated NSEC records. These NSEC records then shut up further TA signalling, as no TA related names apparently exist! And here two unrelated features now need to know about each other: aggressive NSEC needs to be disabled for TA signalling.
If even a limited number of features overlap (that is, they are not fully orthogonal), soon the whole codebase consists of features interacting with each other.
We’re well on our way there, and this will lead to a reduction in quality, likely followed by a period of stasis where no innovation is allowed anymore. And this would be bad. The DNS is still not private and there is a lot of work to do.
Suggestions
I rounded off my talk with a few simple suggestions:

Quickly, a 20-person long queue formed at the microphone. It turns out that while I may have correctly diagnosed a problem, and that there is wide agreement that we are digging a hole for ourselves, I had not given sufficient thought about any solutions.
IETF GROW WG Chair, Job Snijders, noted that the BGP-related WGs have implemented different constituencies (vendors, operators) that all have to agree. In addition, interoperable implementations are a requirement before a draft can progress to standard. This alone would cut back significantly on the flow of new standards.
Other speakers with experience in hardware and commercial software noted that in their world the commercial vendors provided ample feedback to not make life too difficult, or that such complexity would at least come at a huge monetary cost. Since open source features are free, we do not ‘benefit’ from that feedback.
There was enthusiasm for the idea of going through the ‘200 DNS RFCs’ and deprecating stuff we no longer thought was a good idea. This enthusiasm was more in theory than in practice, though as it is known to be soul-crushing work.
The concept, however, of reducing at least the growth in DNS complexity was very well received. And, in fact, in subsequent days, there was frequent discussion about the ‘DNS Camel’.

Further, a draft has even been written that simplifies the DNS by specifying DNS implementations no longer needed to probe for EDNS0 support. The name of the draft? — draft-spacek-edns-camel-diet-00!
I’m somewhat frightened of the amount of attention my presentation got, but happy to conclude it apparently struck a nerve that needed to be struck.
Next steps
So what are the next steps? There is a lot to ponder.
I’ve been urged by several very-persuasive people to not only rant about the problem but to also contribute to the solution, and I’ve decided these people are right. So please watch this space!
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
IMO, there are many camels — BGP, DNS, HTTP, NAT, etc.