

Recursive resolvers are often overlooked when it comes to their role and importance in the Domain Name System (DNS).
Also known as DNS recursors, they act as a middleman between a client and a DNS nameserver — asking around the Internet in search of the answers to client queries. Their caching properties are particularly useful to speed up these searches.
Resolvers can serve different client bases, ranging from end users who want to visit their favourite video streaming website to scripts that crawl the Internet for marketing reasons. Knowing which resolvers are directly relevant for serving the most important clients would allow operators to understand how they should set up their server infrastructure to serve those resolvers best. Combining this classifier with other signals, such as RFC 8145, could also help with identifying which resolvers don’t have the correct DNSSEC trust anchors configured — a problem that we faced before the last Root Zone KSK rollover.
Like our colleagues from .nz, we at SIDN Labs are working on a project to classify recursive resolvers to assist with this understanding. The main difference between our projects is that we are trying to go beyond differentiating ‘real’ recursive resolvers from resolvers — that is to say only those used by monitoring tools — and trying to label different kinds of resolvers such as cloud providers, ISPs and so on.
We are halfway through our research but wanted to share some early results and collect feedback from the community with this blog post.
Dataset and feature selection
We want to classify recursive resolvers based on query data collected at the .nl name servers, but in principle, data collected at any larger authoritative name server should be adequate. We’re collecting queries and responses from two of our four name servers and storing them in our Hadoop-based warehouse.
Feature selection is highly important — not every resolver leaves the same pattern when querying .nl domain names. For example, where 20% of resolvers send 82% of their queries for an IPv4 (A) or IPv6 (AAAA) address, some resolvers query almost exclusively for NS records.
We use these differences to select 22 features that we think are beneficial for analysis. Some features, such as the share of A-record queries are straightforward, others need some more preprocessing.
One of our assumptions is that resolvers of ISPs are well maintained and adopt new standards faster. For instance, we are also trying to detect whether resolvers support the privacy-enhancing standard QNAME minimization.
We are collecting 22 distinctive features of nearly 1.4 million unique resolvers for one single day. We have also created ground truth data, consisting of Autonomous System Numbers (ASNs) from known ISPs, hosting companies, cloud providers and so on. Creating this ground truth allows us to measure the accuracy of the clustering algorithms.
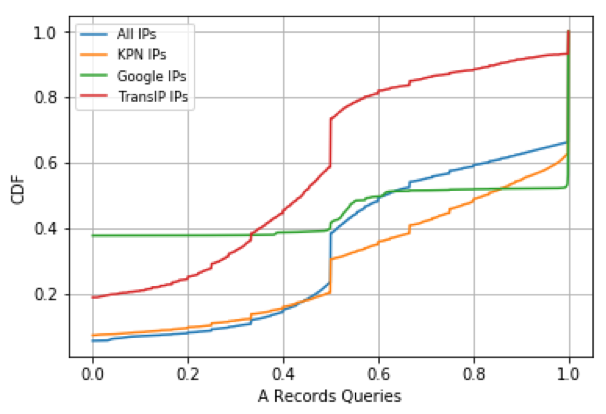
Figure 1 — Share of queries asking for the A-records of a domain name.
Figure 1 shows that resolvers have distinctive query features. We can see that IP addresses of TransIP, which is in the set of hosting companies in our ground truth, show the most unique behaviour, not only on query type A but also for many other feature types in the dataset. This distinct behaviour of hosting companies has led to great accuracy in the clustering phase.
We ran different clustering algorithms and a considerable amount of hosting companies were successfully identified by our algorithm. Other resolvers, however, could not be distinguished clearly. We think that some of these clusters might be affected from noise in the dataset; for example, not every IP in the AS of an ISP is necessarily a recursive resolver used for end-users.
Evaluating more features
There is no exact method defined for classifying recursive resolvers, however, based on our observations during this research to date, we can conclude with some confidence that classifying recursive resolvers is possible.
Our next steps are to evaluate more features to improve the classifier — we welcome any feedback and/or ideas.
Contributors: Moritz Müller, SIDN.
Metin Açıkalın is a masters student in computer science at University of Twente and an intern at SIDN Labs, the research department of the registry of .nl.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
thank you!!!
You may wish to understand more clearly the differences between origin ASN and receipt ASN on certain public resolvers. Please contact me for details on Quad9, an example system which may not comply with your expectations.
Hello John,
I’m interested to hear more, I will contact you from your LinkedIn account.
Have a great day.