

At the end of March 2019, I did a talk at the INEX’s (Ireland’s biggest Internet Exchange Point) Annual General Meeting about my research into BGP network propagation. I was supposed to record it, however, in a brief panic due to HDMI not working on my laptop, I forgot to start the recording. Since people found it interesting, I figured I’d turn it into a blog post instead.
First, let’s talk anycast
So a long time ago… in a job far… well a year back. We were dealing with the lovely routing design of anycast.
For those who need a quick primer, it’s a routing design that allows you to do more natural, regional-based load balancing, allowing you to put server clusters in different regions and serve traffic local to those regions without having to play tricks with the DNS.
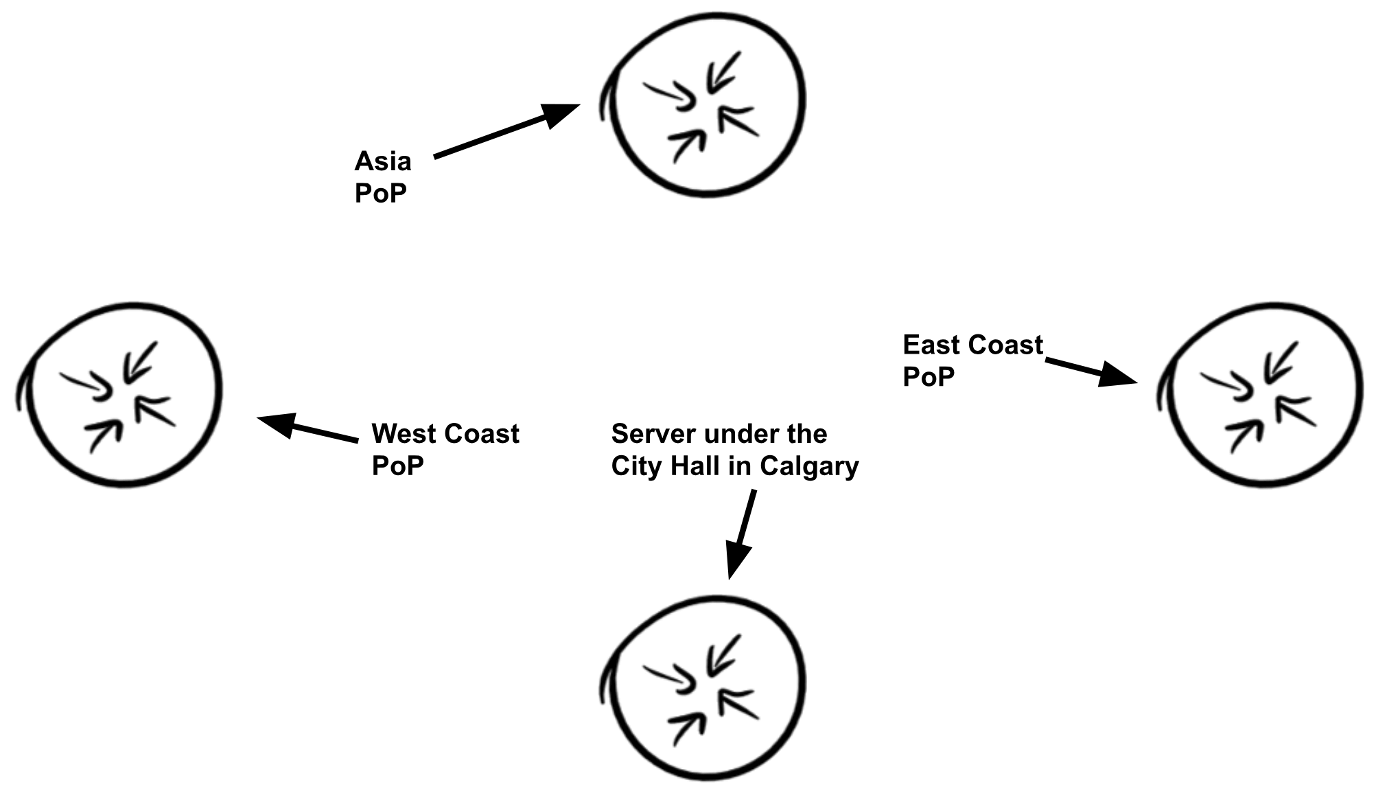
This works by having all participating nodes announce the same IP prefixes globally, and with some careful routing tuning (mainly careful selection of upstream transit/peering providers) you can get good load balancing and latency results due to traffic being served more locally to the visitor’s region.
Sadly, a lot of networks struggle to get consistent network announcements to work right, often resulting in totally backwards-from-logic routing.

However, even those networks that do get most regions right struggle with regions such as Asia, which are much harder to get to route correctly. This is partly due to local ISPs either dealing with overloaded links or their links not always following logical geographic points.

The crux of the problem is ensuring your routing announcements are consistent over all regions and over almost all major interconnection ISPs (Tier 1s).

In simple setups, this really just means you need to keep your AS_PATHs as close to the same in all the regions and carriers you want to have routing control over.
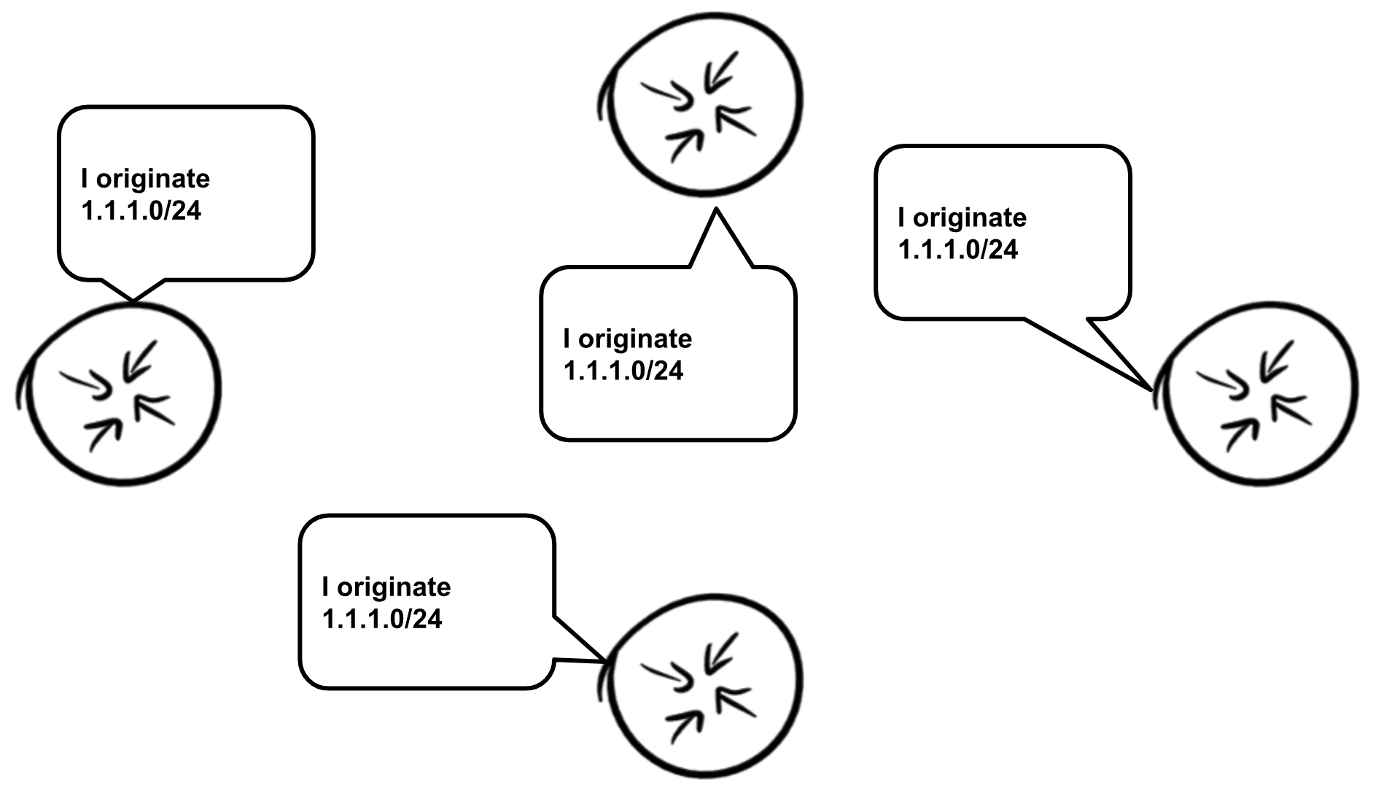
This basically means you should be attempting to use the same providers and traffic engineering parameters in all regions, AS_PATH prepending being one of the more basic ones.
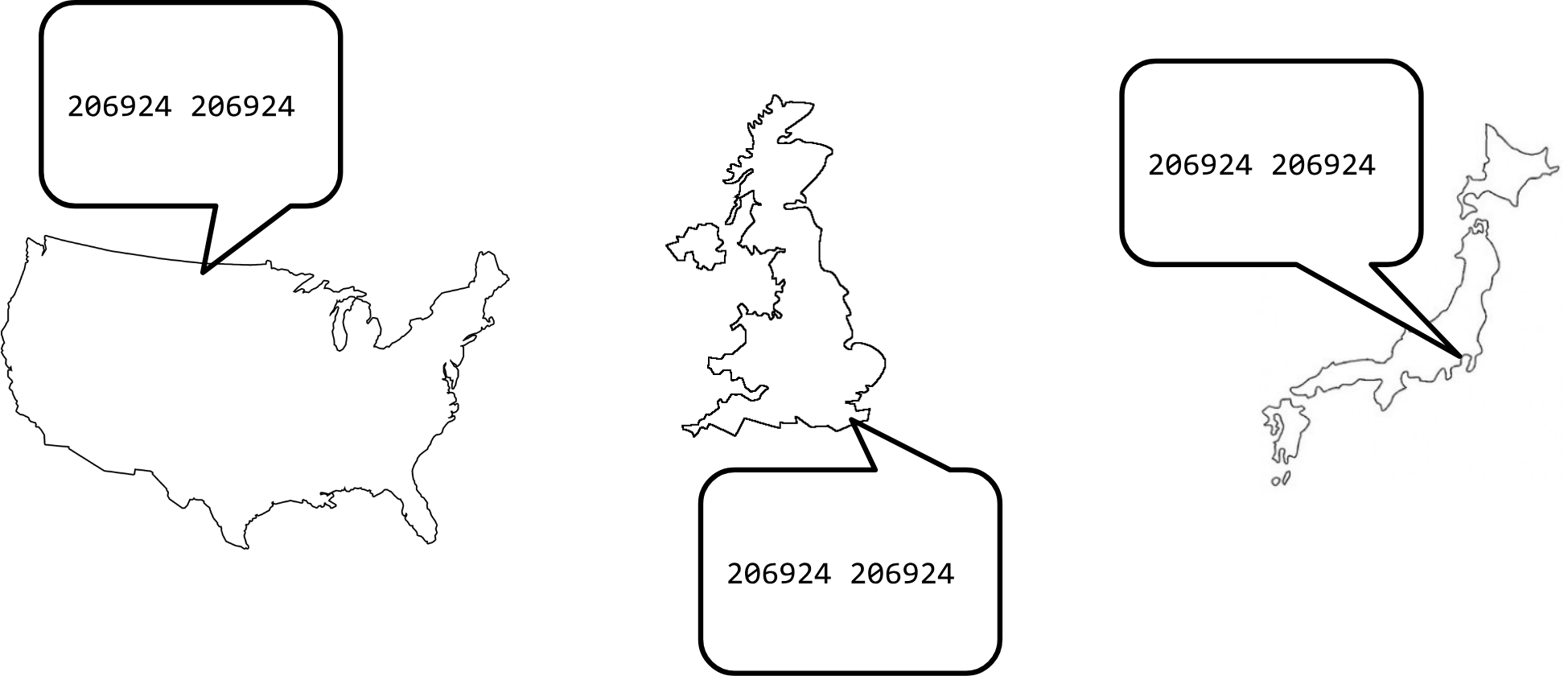
However, as systems get larger and more complex, eventually a mistake is going to be made. In the case of the job I was involved in, a configuration misunderstanding during maintenance of a router caused it to drop a traffic engineering prepend. This caused a huge traffic shift globally towards this router, almost instantly overloading the site.
This was a regrettable incident, and it became clear that while the traffic engineering prepend was useful in the past, at that point in the network it was more of a liability. So it was time to remove it.
But what if we were to make the same mistake again? This time we are changing a lot more router configurations at once.
It’s worth thinking about failure modes here. There are two ways the change could fail.
The first one being that the change applies to a large percentage of the routers over the network, but some of them fail. This would cause traffic to mostly shift away from those locations and head to other nearby sites. As long as not too many sites have this issue, this is the best way it can fail.
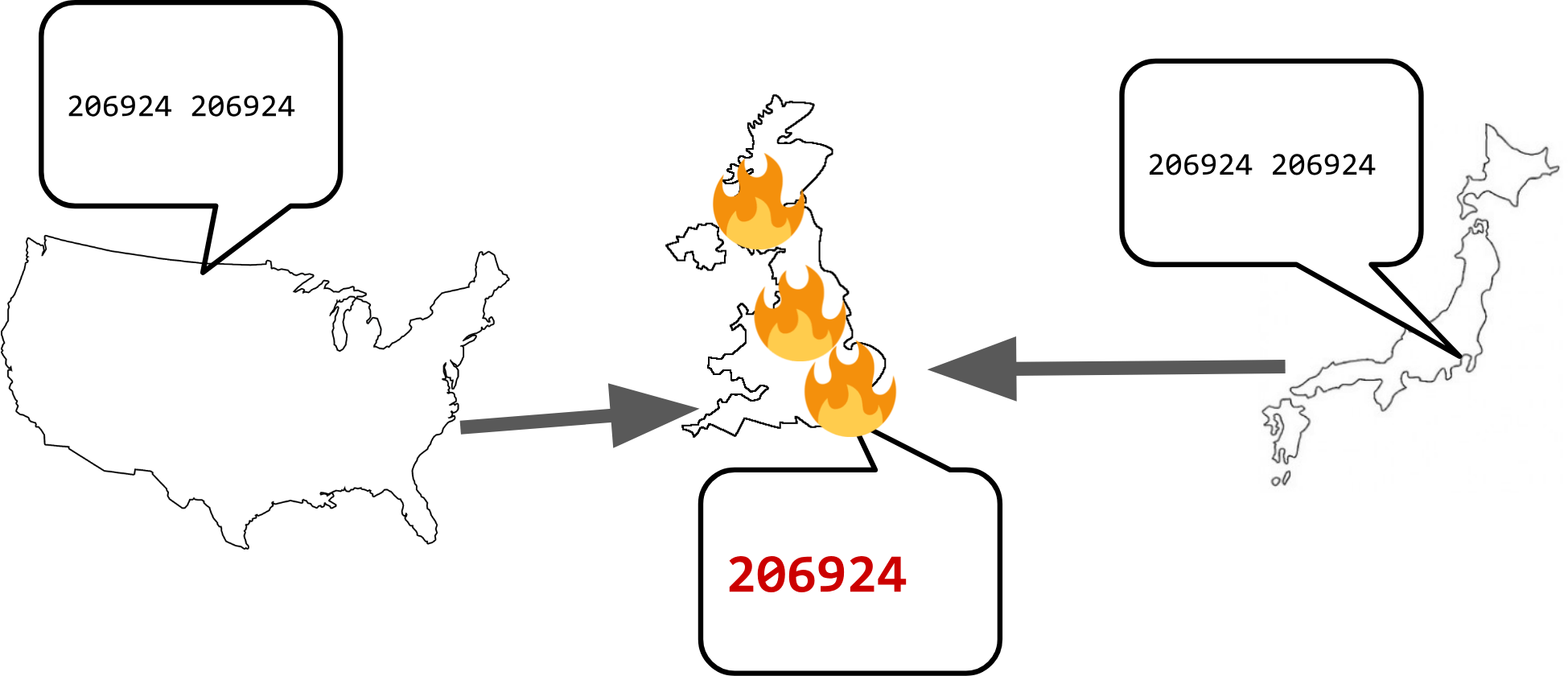
The nastier way it can fail is that most routers don’t end up being changed but a small percentage of them do.
This will be a repeat of the first incident, however, more routers will be involved, and we would be dealing with a lot more routers that would need a rescue configuration rollback or hotfix.
The story of them changing this in a sane way is not mine to tell, however, someone at the front of this change did a talk at RIPE NCC’s biannual event about how it was done — watch the video.
The good news is, the change went through fine, and no router got left behind! A small amount of traffic churn happened while routers globally had to update their routing tables and inform the other internal routers they were connected to about that.
Understanding the challenge of time to implement changes
During this time, it was observed that not all of the providers accepted this change at the same time. Some providers seemed to re-converge almost instantly but others were noticeably slow.

This begs the question, how long does this sort of thing generally take? And are some providers better than others? If so, who is the fastest and who is the slowest?
To answer such questions we need to define what it means for a route to be propagated. There are two valid ways (in my eyes) this could be.
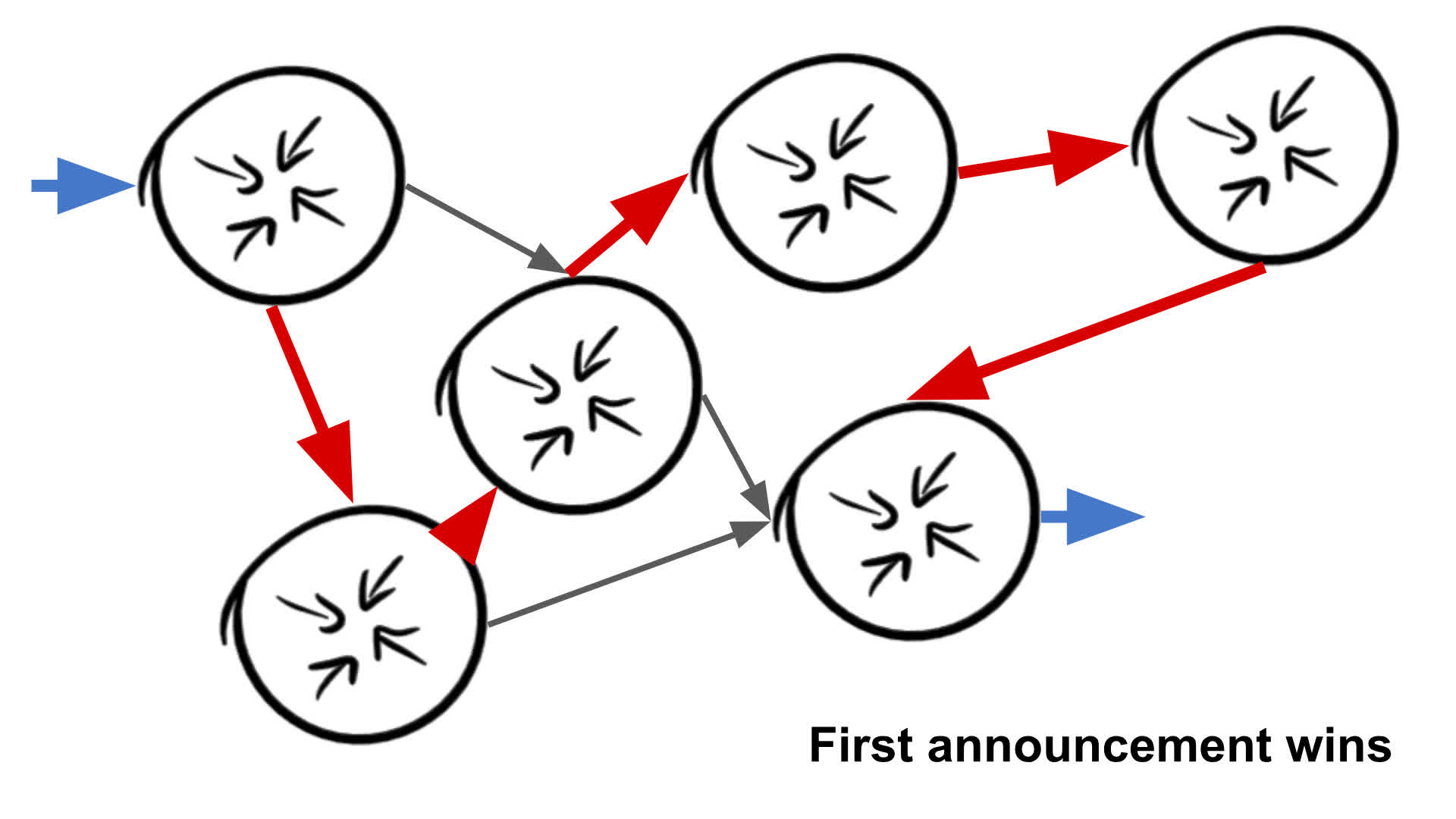
The ‘First announcement wins’ method is quite literally what it says on the tin. When we see a BGP update message for our prefix, that provider+location combo wins (or if they are late, loses).
This could be slightly flawed since some networks might have hard-to-observe mechanisms for quickly sending routing information inside their network, but those initial route updates internally may not be sensible network paths.
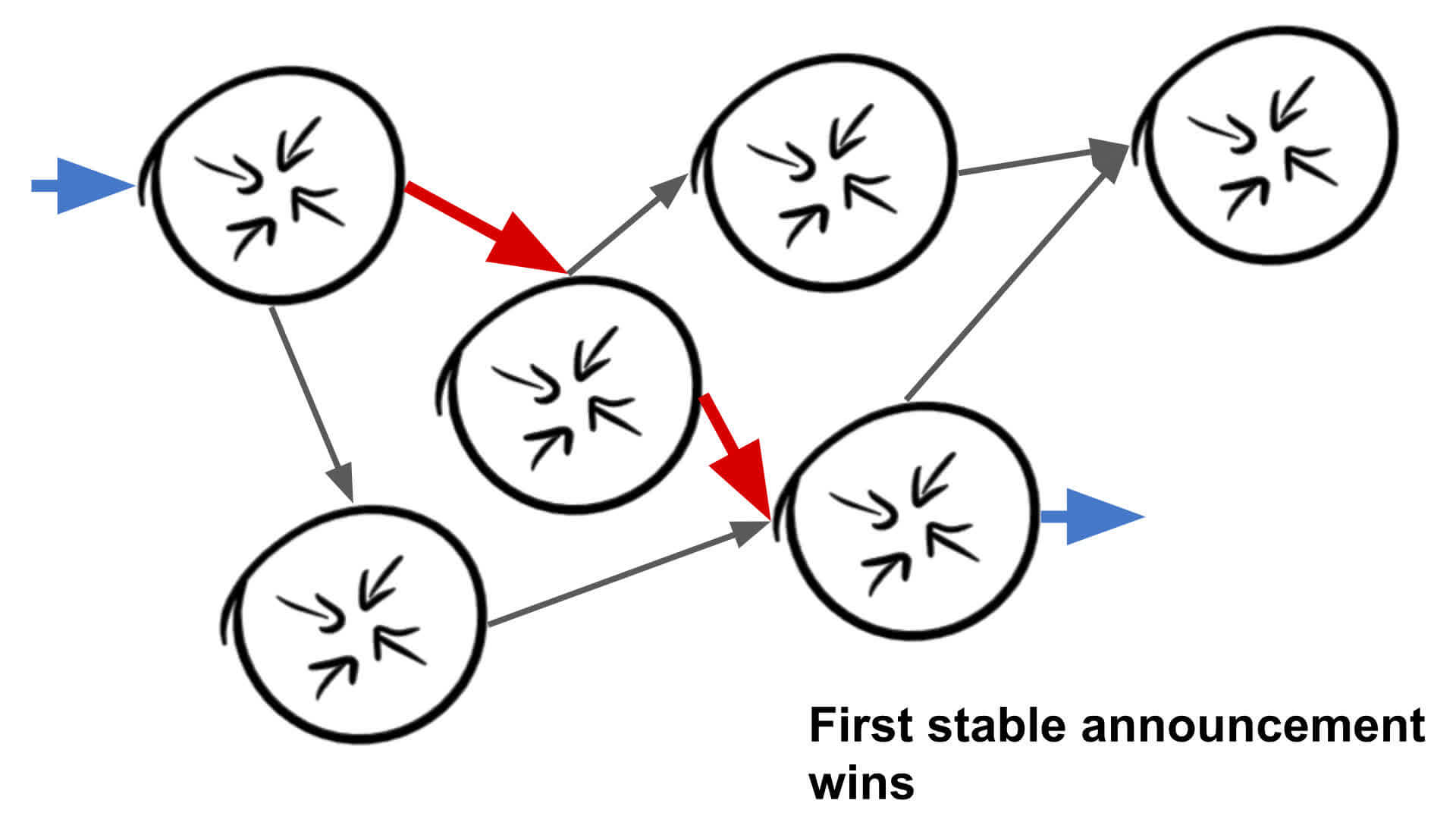
For ‘First stable announcement wins’, testing is done to ensure that routes that become ‘stable’ (stops changing its internal routing in the provider backbone) are declared the winners. In my eyes this is what most network engineers are looking for, however, it also has a large issue attached to it.
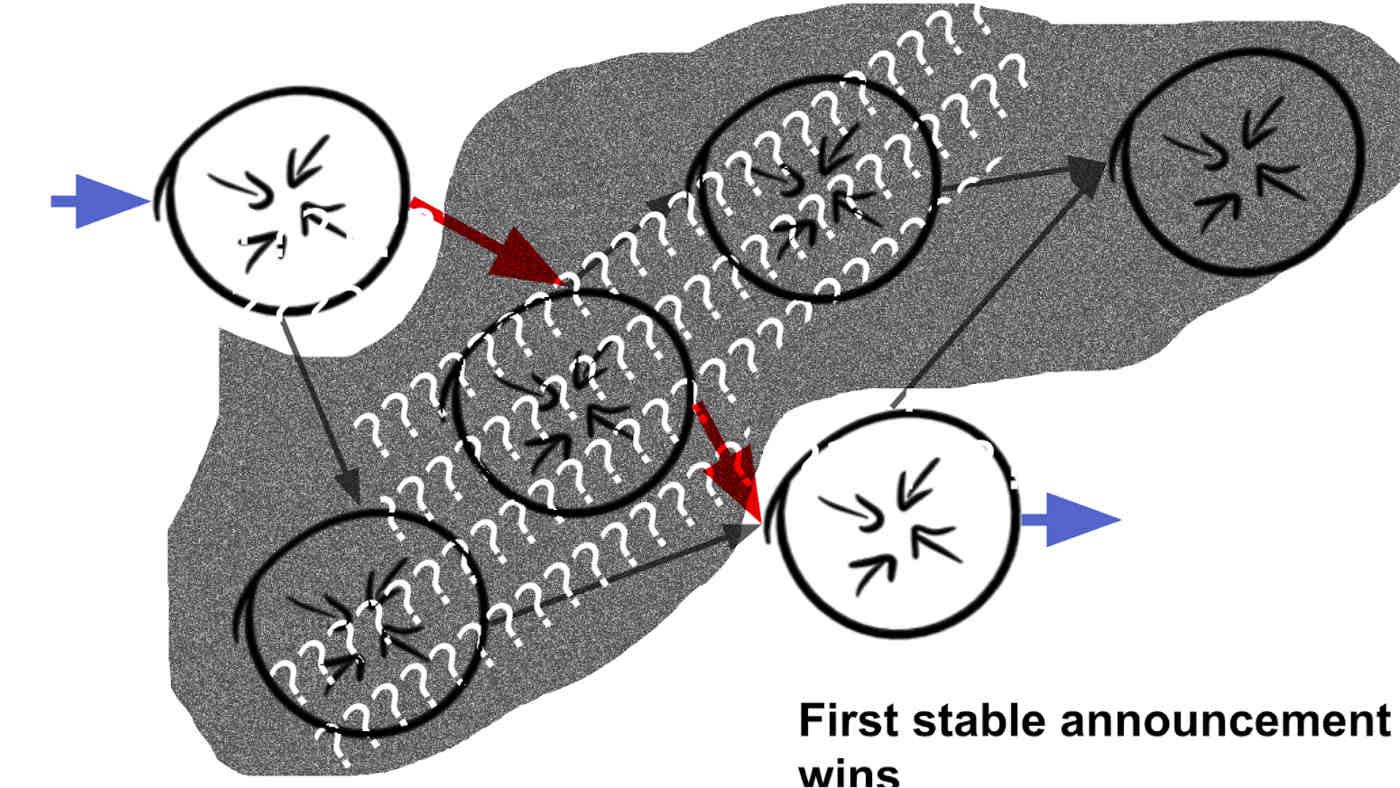
Figuring out what is a stable route is a non-trivial job — no matter what way I do it, I think it is unmeasurable to the 10s of milliseconds. For this reason, the experiment we are doing is using ‘First announcement wins’.
The propagation race works like so:

The high precision timestamps are important here; a detail that actually ended up being slightly devastating for the first few runs due to the inaccuracy of system clocks.
You see, I now have a stronger respect (in that I now actually believe they have worth) for the pulse per second (PPS) and 10Mhz clock inputs on a lot of high-end carrier routers. This is because time syncing is actually incredibly hard when you go above more than two systems.
Locking all systems to a stable clock source is immensely nice, and before you ask, NTP does not really get that close in real-life situations with a wide range of geographically separated targets.
After a lot of time syncing and timestamp offset correction, I ended up with a linear list of announcements by server location (airport codes to signify where they are, since that’s generally what the networking industry seems to use).
Not all providers are propagating at the same speed
For AS6453 (Tata Communications) times looked decent to start with. Given that none of the BGP route update collector nodes had Tata as a direct provider, this is basically tracing how fast Tata’s peers can send routes around.
It’s interesting that it seems to have a 500ms ‘ish’ minimum, but after that routes start to move around the globe very fast, with the exception of EWR (New York area), likely an outlier.
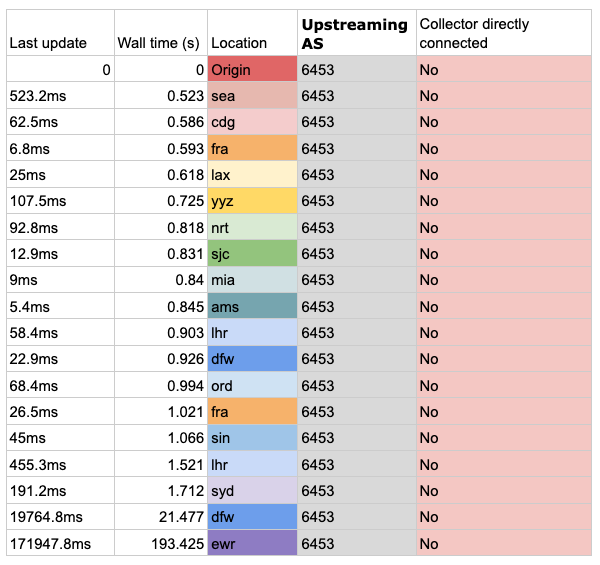
Table 1 — First announcement win propagation result times for AS6453 (Tata Communications).
For AS174 (Cogent Communications) it seems that propagation takes a little longer, due to policy on the upstream ISP used for route collection. Cogent only was imported from other carriers, so there is a similar effect as we saw with Tata here. However, it is odd that Toronto (YYZ) sees the route first after announcement since the announcement is done in London (LHR). This is likely the impact of a route reflector or something inside the network.
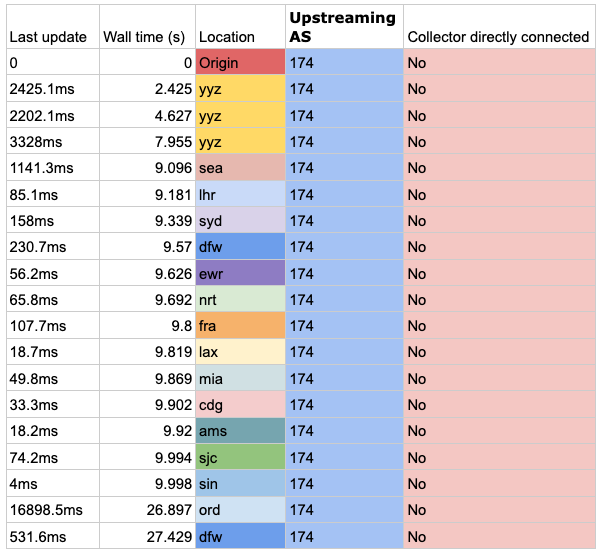
Table 2 — First announcement win propagation result times for AS174 (Cogent Communications).
For AS3257 (GTT), we are finally seeing some timing data that is based on providers we are locally connected to. GTT does seem to send things around the world reasonably fast, at a shiny 1.9 seconds (apart from EWR, thus supporting that this is more of a data point error rather than anything else).
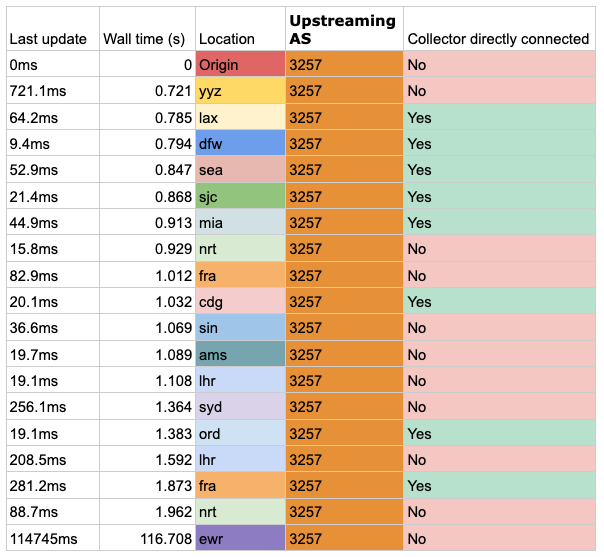
Table 3 — First announcement win propagation result times for AS3257 (GTT).
AS1299 (Telia) has a more logical timing — 0.6 seconds after we announce in London it appears in Paris and Frankfurt directly and it is fully propagated to all nodes less than 2 seconds after that. However, other carriers beat Telia to their own route! If you look at ORD (Chicago) and MIA (Miami) you can see other carriers pick up the route from Telia at another location, and hand it over to our provider 20 seconds before it arrives as a direct route.
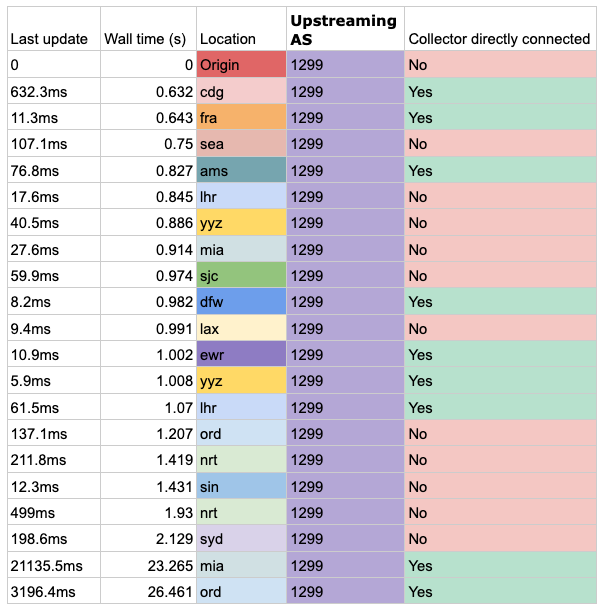
Table 4 — First announcement win propagation result times for AS1299 (Telia).
Level 3 (AS3356) does the worst in this test, taking 18 seconds from announcing the test prefix to it until it appears anywhere on the Internet. It appears in SEA (Seattle) of all places, and then from there, other carriers pick up that route and propagate it faster than Level 3. Some 30 seconds later Level 3 has caught up and the route is now seen in all places with Level 3 peering.
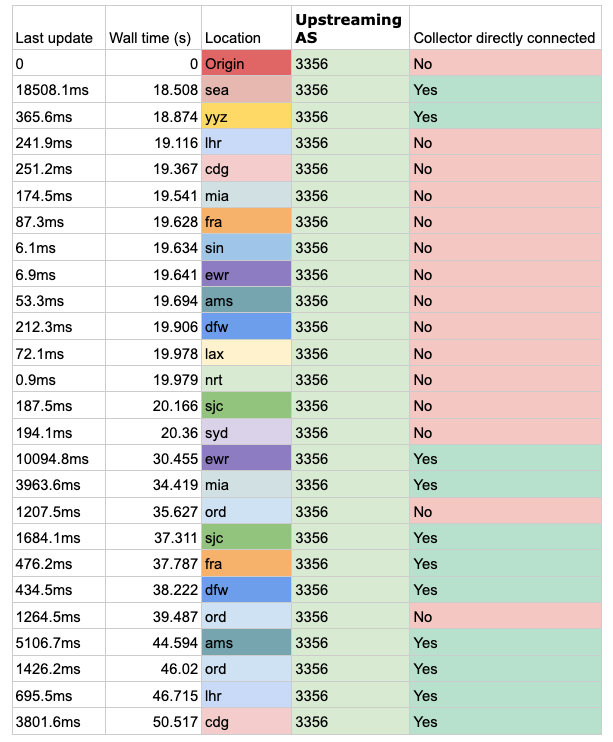
Table 5 — First announcement win propagation result times for AS3356 (Level 3).
Last but not least is AS2914 (NTT Communications). Although they are not the fastest at sending routes globally, they did appear to be the most smooth and consistent.
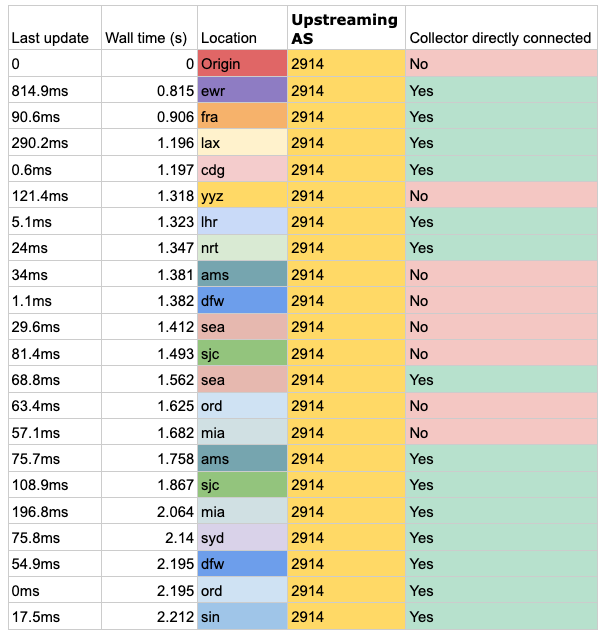
Table 6 — First announcement win propagation result times for AS2914 (NTT Communications).
Now that we have done all the carriers you may think that is it, however, there is a different kind of propagation we can observe:
The dying breaths
Given that we can trace the network in sending out BGP routes, we can also trace them withdrawing them!
This is a test that is harder to see on the routing table itself, so it’s easier (and much more fun) to observe it by simply doing a traceroute to a prefix and then withdrawing it from all providers.
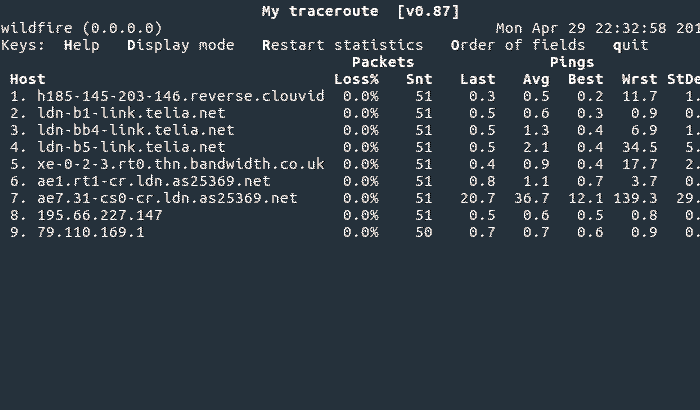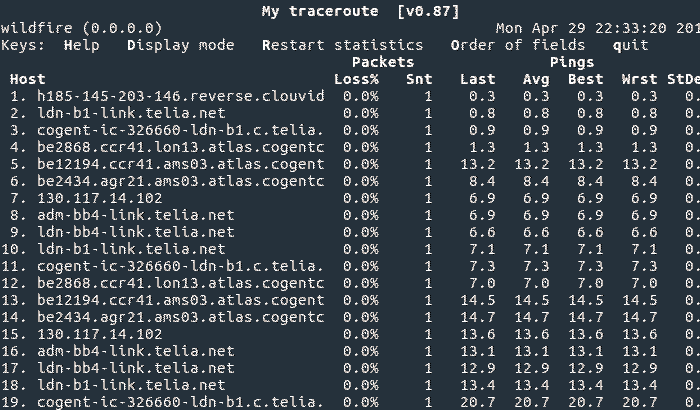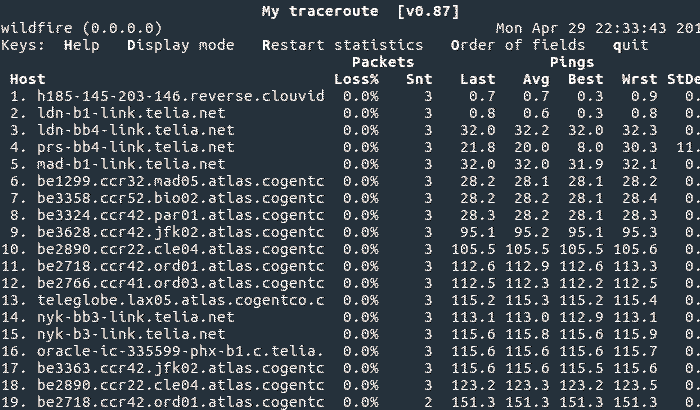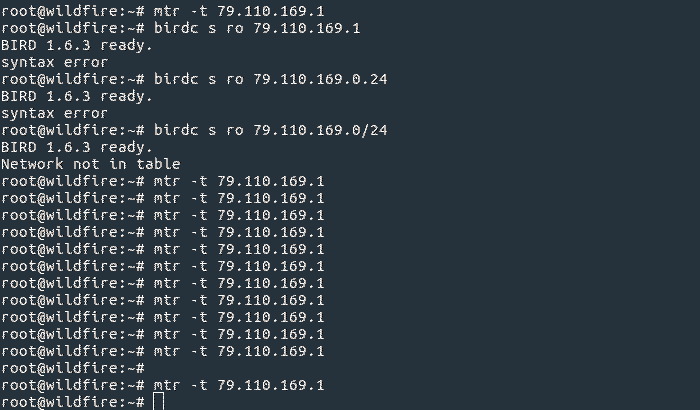
Here you can see the route slowly being released out of all of the carriers, then the carrier backbones, and then the carrier inter-peering relationships. It also exposes some interesting and strange routing as options to route a prefix begin to run out!
Want to learn more?
Anyway, as I said to the audience, we have had the fast part, now we can have the furious part! If you generally like this kind of post, I aim to post once a month on various (mostly networking related) matters. If you want to stay up to date with these, either subscribe to my blog’s RSS or follow me on Twitter.
I would like to thank AS57782 / Cynthia Revstrom for lending some IPv4 space for this post, and helping out on the traceroute demo you see above.
If you do have any questions about this talk, please feel free to reach out on email (ben at benjojo dot co dot uk) or Twitter, or leave a comment below! Until next time!
Adapted from original post which appeared on Ben’s Blog.
Ben Cox is a systems engineer from London, who started off with a background in web security and has found a fascination in Internet infrastructure and protocols.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.