

Reverse DNS is a special DNS top-level zone (in-addr.arpa. for IPv4 and ip6.arpa. for IPv6), which can be used to obtain fully qualified domain names for an IP address. For example, the address 2001:DB8::1 has the reverse record 1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.b.d.0.1.0.0.2.ip6.arpa..
Clients can ask the DNS server responsible for that record where in the DNS tree it points to by requesting a pointer (PTR) record. They then get a DNS name as the answer. In addition, operators can also put CNAMEs into the reverse DNS tree, to refer clients to another name.
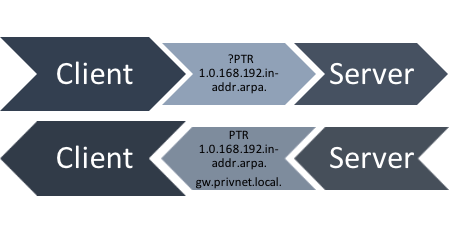 Figure 1 — Reverse DNS schematic.
Figure 1 — Reverse DNS schematic.
You might ask yourself ‘Who cares about reverse DNS?’. Well, researchers use it to understand links and build topologies, track IPv6 deployments and to create hit lists to perform IPv6 security scans. You also see reverse DNS being used to forward-confirm mail servers to protect against spam, and as a useful information source to enrich log files.
Who maintains reverse DNS zones?
Every owner of an IP network has to delegate the corresponding reverse DNS zone to one of their authoritative name servers and fill the zone with correct information. In the past, researchers were not convinced that this really happened. They saw a lot of PTR record requests receiving SERVFAIL answers (over 20%) and concluded that reverse DNS is simply not a priority for network operators.
To get better data on this, we took a look at how people use reverse DNS in the wild using an active method to collect reverse DNS zones and a passive method — the Farsight DNS data stream.
Farsight collects this dataset by combining the outbound DNS traffic of recursors all around the world. By not collecting cache-hits and individual queries, they avoid the issue of collecting too much private information.
A passive look at reverse DNS
Taking a look at the Farsight dataset, we noticed that it looks… well, funny. There is no day pattern in the observed queries per day, and the day pattern between the (far too many) PTR queries and the observed AAAA queries is disjointed.
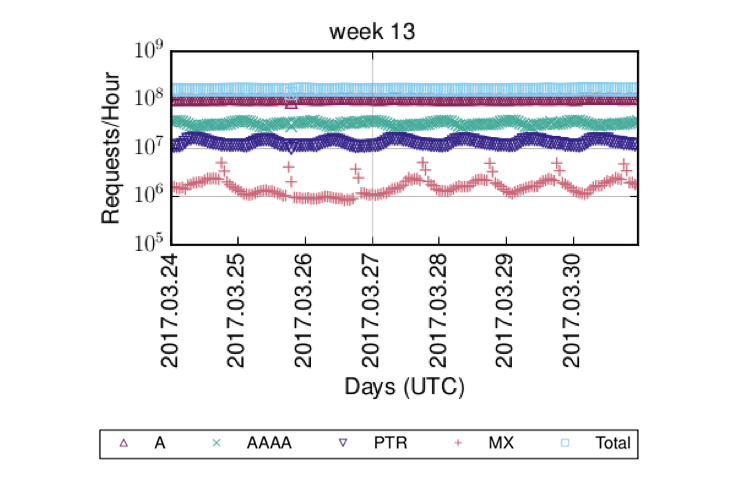
Figure 2 — Unclean reverse DNS dataset.
Upon further investigation, we found that a single operator is responsible for this effect; they contribute nearly 50% of all(!) queries in the dataset and produce a significant number of PTR queries. However, most of these PTR queries are destined to ip6.int., the long discontinued former reverse DNS zone for IPv6, all asking for names that would belong to IPv6 addresses in 70::/8.
Similarly, we also saw a lot of queries for DNS service discovery, which — incidentally — also uses PTR record types, mostly for names in vendor-domains, such as dell.com, apple.com, and hp.com. Hence, we assumed that there is something funny with that ISP and excluded it from our analysis. This made our data (Figure 3) look a lot more like we would expect it to look.
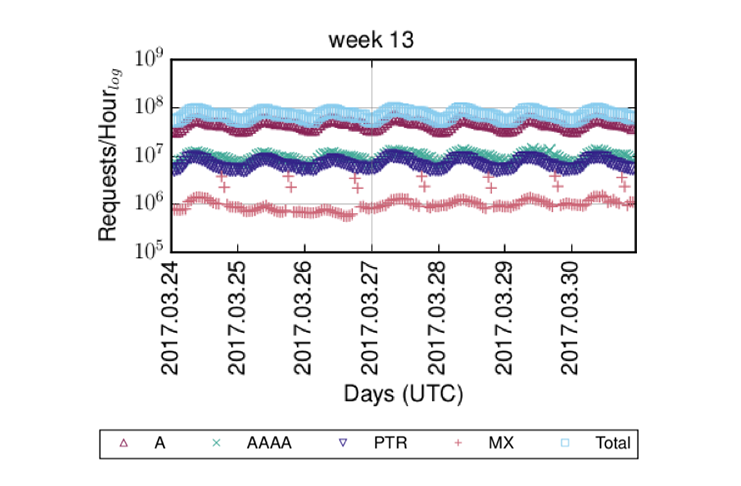
Figure 3 — Cleaned reverse DNS dataset.
Note that the regular outlier you can see in MX queries is a single Russian operator who seems to run a weekly ‘Mailinglist message digest’ campaign.
Not everything that uses PTR records actually is reverse DNS
As mentioned before, it seems like not everything that uses PTR records actually is reverse DNS. While this might seem counter-intuitive, there are, in fact, other standards that use PTR records, for example, DNS-SD (DNS service discovery).
We gave this a look (Figure 4), and found that reverse DNS is the dominant use-case for PTR records — over 99% of PTR queries ‘belong’ to IPv4 reverse DNS.
IPv6 reverse DNS only makes up a fraction of that, with roughly 0.9%. The rest of the queries we found corresponds to DNS service discovery.
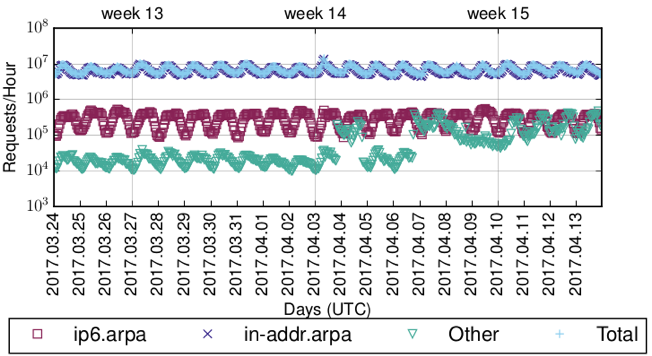
Figure 4 — PTR queries matched to use cases.
Note, the outliers for ‘other’ queries most likely correspond to an ISP deploying a new app to CPEs/set-top boxes that constantly performs DNS-SD for services below a TV networks’ domains.
What do the servers say?
Next, we looked at response codes for reverse DNS queries.
Comparing IPv4 and IPv6 reverse DNS, straight away we see that IPv4 reverse DNS queries are successful in roughly half of all cases. We see successful delegations but no data being present (NXDOMAIN) in 25% of cases, and real error in only ~12% of cases.
IPv6 provided a totally different picture. Nearly 95% of requested names do not exist, even though the corresponding zone is delegated. On closer investigation, we found this to be due to more queries for addresses in reserved IPv6 networks leaking to the global DNS ecosystem. This includes queries for private ranges, but also queries for Toredo address ranges, a discontinued 4to6 transition technique.
Filtering these ranges out changes the picture significantly. Now roughly one third of all queries receive an answer. Furthermore, while close to 64% of requests are for names that do not exist — that is, IP addresses that do not have a reverse DNS record — we see real errors in less than 3% of cases, significantly less than for IPv4. Filtering reserved and special-use IPv4 names has no influence on the total numbers for IPv4.
| rcode | in-addr.-arpa | ip6.arpa | ip6.arpa w/o Resv. |
| NOERROR | 47.21% | 4.00% | 32.20% |
| NXDOMAIN | 25.36% | 94.87% | 63.87% |
| REFUSED | 15.47% | 0.14% | 1.11% |
| FAILURE | 8.77% | 0.81% | 1.34% |
| SERVFAIL | 3.17% | 0.18% | 1.38% |
| FORMERR | 0.01% | <0.01% | <0.01% |
| NOTAUTH | <0.01% | – | – |
| NOTIMP | <0.01% | – | – |
CNAMEs: Talk to somebody else…
The last noticeable observation from our passive data is there are only occasional CNAME responses for IPv6, while there is a stable set of CNAME responses for IPv4 reverse DNS (Figure 5).
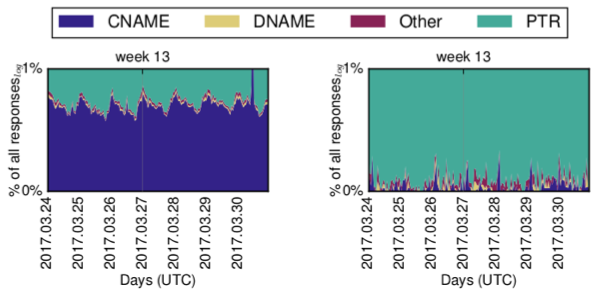
Figure 5 — Response types for IPv4 (left) and IPv6 (right).
This is connected with RFC 2317 style delegation of CNAME records. For IPv6 reverse DNS, this is no longer necessary, as the DNS hierarchy changes at every nibble of an IPv6 address.
An active look at reverse DNS
In addition to the passive look at reverse DNS, we also used the technique we presented earlier in this Blog series to collect IPv4 and IPv6 reverse zones.
Similar to our observations in the passive measurements, we saw a lot more SERVFAIL for IPv4 reverse DNS than for IPv6; roughly the same as in the passive measurements. We also found that most dynamically generated IPv6 reverse DNS zones have a size of /48.
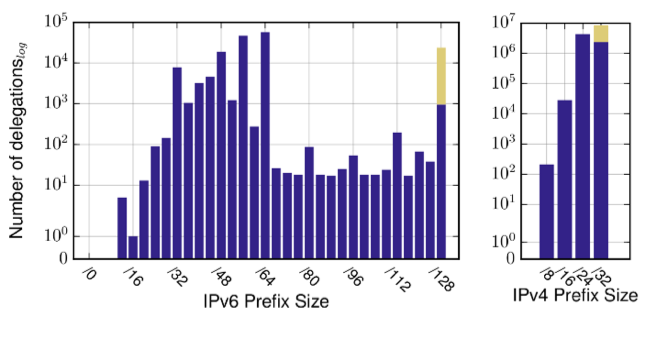
Figure 6 — Number of delegations as per IPv6 (left) and IPv4 (right) Prefix Size.
Taking a look at how delegations are done, we found IPv6 reverse DNS to be top driven; most delegations happen for /32, /48, and /64s (which is to be expected based on addressing policies).
Similarly, looking at delegations and CNAMEs (Figure 6), we find that IPv4 reverse DNS is commonly delegated with CNAMEs for blocks smaller than a /24, as suggested by RFC 2317.
A more unusual observation from the active measurements is that we actually see a lot of CNAMEs for IPv6 reverse DNS (Figure 6), however, on closer investigation, we found that operators like to preserve reverse naming between IPv4 and IPv6 reverse DNS this way — they have CNAMEs from their ip6.arpa. records pointing to the corresponding names in in-addr.arpa., where they authoritatively maintain the content.
Reverse DNS is not as badly delegated as people think
To summarize, we found that reverse DNS is not as badly delegated as people think. Furthermore, it is still relevant and people out there actively use it.
In relation to IPv6, we find it interesting that there are far less broken delegations (SERVFAIL) than for IPv4. However, this may simply be due to the use of IPv6 reverse DNS having had less time to go wrong.
The significant difference between reverse DNS use in IPv4 and IPv6 is also an interesting finding. While various large content providers claim that there is 20-40% IPv6 adoption rate, our numbers suggest something different.
We assume this is due to a pattern where larger organizations, content providers, and ISPs rollout IPv6, where smaller ones don’t — this explains the high traffic volume seen by Akamai and Google, for example. However, it also means that there is a large, heavy tail of small and medium-sized Internet participants still missing out on IPv6.
As for the future of reverse DNS research, we plan to take a better look at how operators maintain and update reverse names.
This blog article is based on: Fiebig, Tobias, et al. ‘In rDNS We Trust: Revisiting a Common Data-Source’s Reliability.’ International Conference on Passive and Active Network Measurement. Springer, Cham, 2018. Thanks to co-authors Kevin Borgolte, Shuang Hao, Christopher Kruegel, Giovanni Vigna, and Anja Feldmann.
Tobias Fiebig is an assistant professor at TU Delft, where he uses large-scale network measurements to understand human factors in information security.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.