

Anycasting IP space has become quite a meme in the networking world in the past few years. After being used sparsely in the past for UDP-based services such as DNS, it is now being used for TCP-based services too, meaning that all the services that use TCP are now also being served on anycast IP ranges (ie, HTTP, or other TCP-based applications, such as games).
Before anycast was used in this way, providers who had services in multiple locations would use a practice called GeoDNS, where the DNS server would send you to the (hopefully) correct and nearby unicast address to the customer making the DNS request.
You can see that Google does this currently for their root domain — here is an example of a DNS lookup for it in Japan:
ben@jp:~$ dig google.com +short
216.58.200.206
And of the same query in the EU:
ben@it:~$ dig google.com +short
216.58.205.206
These IP addresses take the system to a nearby server of Google’s. The reasoning for this is better performance/reliability (the packets do not have to move as far around the earth) and load balancing (lots of smaller server deployments, rather than a very large server deployment).
At the time of writing, my blog is behind Cloudflare, a service that uses anycast to serve its traffic. This means that wherever you look up my blog you get the same IP addresses (provided there is no tampering from your ISP):
ben@it:~$ dig blog.benjojo.co.uk +short
104.20.96.16
104.20.97.16
ben@jp:~$ dig blog.benjojo.co.uk +short
104.20.96.16
104.20.97.16
The idea is that, rather than having the DNS server pick where the client goes, you use the routing layer of the Internet to guide traffic to the closest location. This also means that if a failure were to happen to a set of servers, traffic would re-route to the next place where that IP address is serviced (in practice, the routing layer has many complicated failure models, just like GeoDNS has).
This also means that no single deployment is directly targetable — you cannot force a client in Italy to go to Japan by giving it a set of addresses, and the routing layer of the client ISP (and their upstream ISPs) are the ones that make that choice. This means that traffic floods are spread over all the servers (assuming the sources of the flood are distributed around the world).
However, there are deployment concerns with anycast. Traffic can be hard to attract into the right places, as it is the client’s ISP that decides where the traffic goes, making the need to use traffic engineering necessary (often with BGP community strings to prevent announcements to some networks/regions).
Below is a RIPE Atlas traceroute measurement of an unnamed anycast deployment; you can see traffic is not quite contained in any country for quite a lot of the time, with some traffic in the United States going to Japan, and even a trace going from the US, EU, India, and then Singapore!
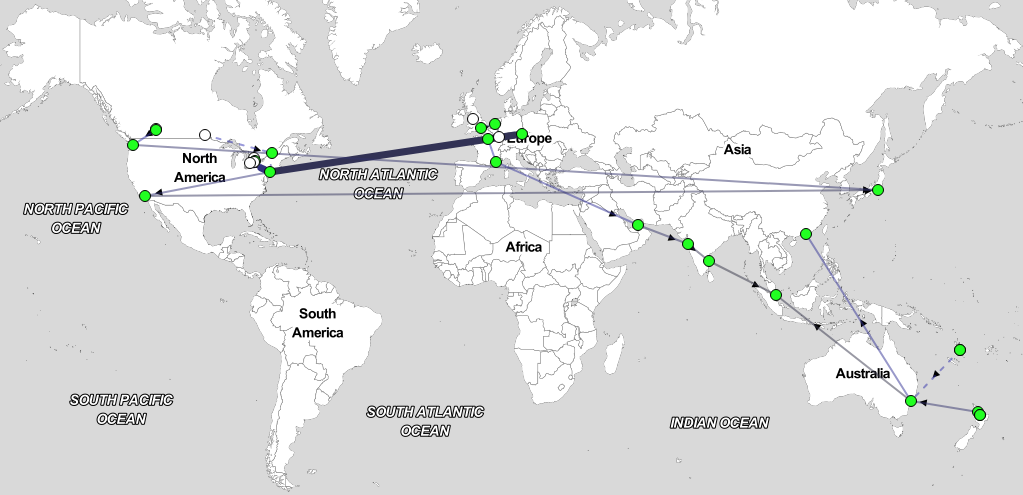
This is often caused by a mix-up of upstream providers in a region. If you do not have direct access to a Tier 1 ISP then you easily end up with large amounts of traffic going to the wrong place because of the large routing attraction those networks have.
Sometimes it is either not possible nor economical to have all of your server deployments backed behind the same set of Tier 1 ISPs, and this will mean that you will have a much harder time keeping traffic in regions.
A CDN called Fastly made this pretty awesome talk last year that shows a newer way to deploy IPv6 networks, using both GeoDNS and anycast concepts. The video is here below, but given it’s 23 minutes long — skipping to 11 minutes gets to the point faster — I will summarise it as well:
João Taveira explains that Fastly was a unicast (ie, GeoDNS) network in the beginning, and it grew to have an anycast offering due to some clients requiring anycast. The interesting part is where they end up: they begin to do a model called backing anycast. IPv6 makes backing anycast easy because of the sheer amount of IP addresses a service provider can use.
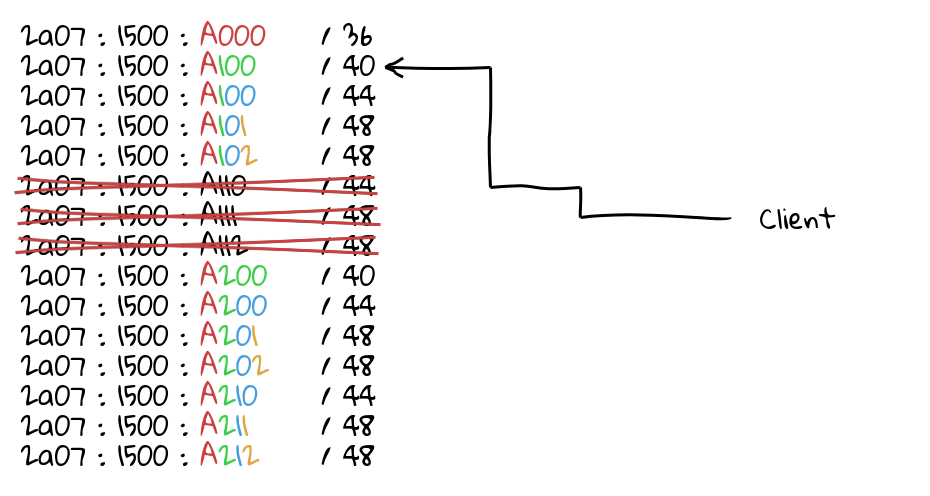
The idea is this: because a network operator will be allocated around a /32 or larger in IPv6 address space, this allows them to have 16 bits of individual prefixes they can announce. (In my example, the AAAA’s are what is announceable on a /32 — the 0000’s are too small to announce on the routing table.)
This means you could announce two prefixes per PoP — the /32 “super” block, and the deployment unicast specific /48 — and you can use GeoDNS to ensure a client ends up in the correct place. If that prefix is attacked, you can drop the prefix, and traffic falls back to the super block, which is hopefully spread out enough that your service can absorb the attack, all while the /48 you dropped is probably still serving the traffic from the same place, assuming that the super block ended up in the same deployment.
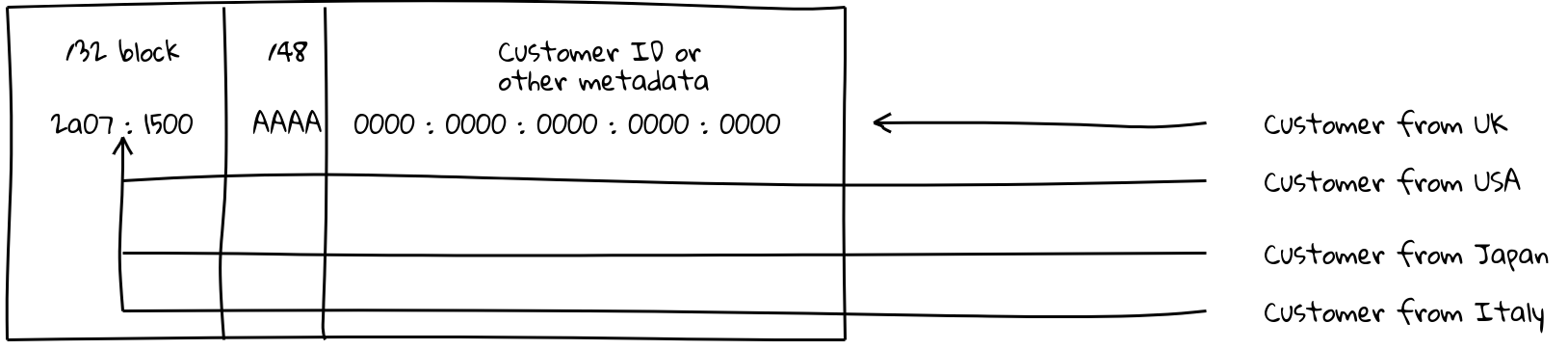
This means you can fix the 99th percentile of clients that are not going to the correct PoPs on anycast, while also not being as vulnerable to traffic floods and other issues involved with unicast-only models. You may even decide not to send a specific IP address on GeoDNS all the time. Instead send the majority of your traffic to the super block by default assuming in good faith that the Internet routing layer will take care of it.
But João argues: why stop at that? Since you can now control clients routing to you, while maintaining the optional ability to protect the network from attack, you could divide it up much finer and by provider!
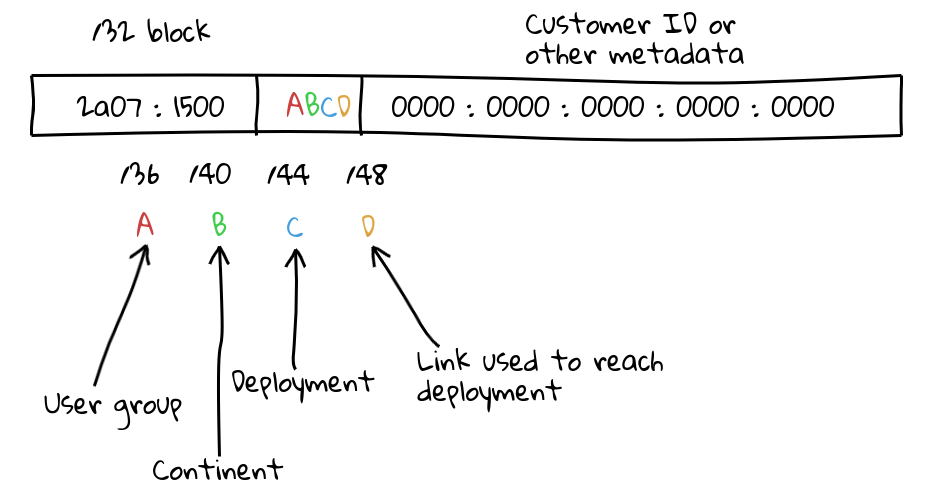
In my example, I have kept in mind some things:
- User groups, the idea is that you spread your users around these groups — this way, you can traffic engineer on a finer scale, other than “all users everywhere”.
- There is obviously a very set amount of continents, but you may want finer control over it. Say, east coast North America vs west coast North America: you have 15 options slots here to fill, ensuring you leave one for “global anycast”.
- This model assumes you are not going to have more than 15 deployments in a continent — this may not be true, but it’s also worth pointing out if you have more address space — say, a /29, and you can just scale the model up and give yourself more bits.
In practice, failover works like this:

Assuming a client is being sent to a specific deployment on a specific link, and something happens to that link and it is taken offline, traffic stays within deployment! Ensuring connections do not break!
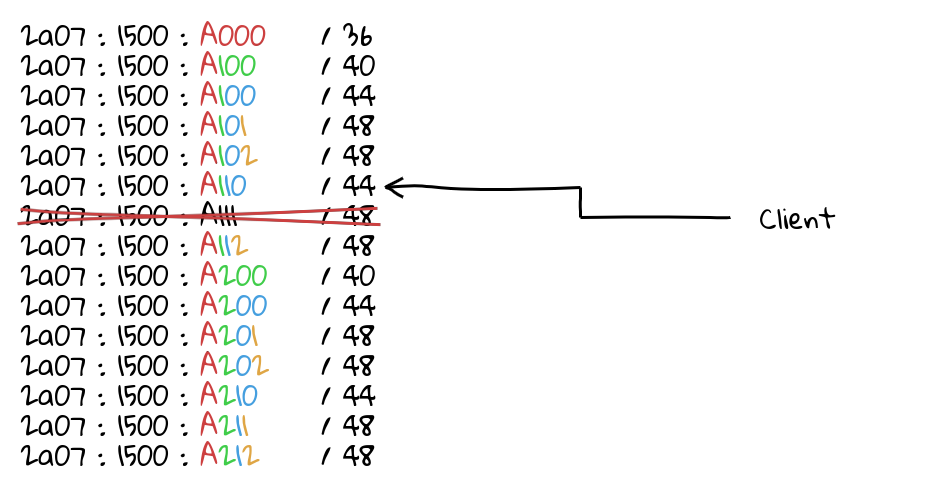
However, let’s say something requires the deployment to stop serving traffic (for example, attack or system maintenance). When you withdraw the prefixes of the deployment, traffic will failover to the nearest deployment within the region!
This reduces the unpredictable redirection of traffic, ensuring the network works better when not all of the deployments are online.
To observe and recreate this idea I used Vultr, a VPS host that allows their customers to have automated BGP sessions to build an anycast network.
To save time and avoiding writing 15 different bird configs, I used their “Startup Script” feature to build the BGP config in real time (using imperfect bash). On boot, this script produces a config that looks like this:
router id 45.63.88.76;
protocol kernel {
persist;
scan time 20;
export none;
import none;
}
protocol device {
scan time 10;
}
protocol static
{
route 2a07:1500:1000::/36 via 2001:19f0:ac01:5ba:5400:00ff:fe7d:1fdd;
route 2a07:1500:1300::/40 via 2001:19f0:ac01:5ba:5400:00ff:fe7d:1fdd;
route 2a07:1500:1310::/44 via 2001:19f0:ac01:5ba:5400:00ff:fe7d:1fdd;
route 2a07:1500:1311::/48 via 2001:19f0:ac01:5ba:5400:00ff:fe7d:1fdd;
route 2a07:1500:1312::/48 via 2001:19f0:ac01:5ba:5400:00ff:fe7d:1fdd;
...
}
protocol bgp vultr
{
local as 206924;
source address 2001:19f0:ac01:5ba:5400:00ff:fe7d:1fdd;
import none;
graceful restart on;
multihop 2;
neighbor 2001:19f0:ffff::1 as 64515;
password "xxxxxxx";
export filter {
if (net = 2a07:1500:1311::/48) then {
bgp_community.add((20473,6000));
bgp_community.add((64699,2914));
}
if (net = 2a07:1500:1312::/48) then {
bgp_community.add((20473,6000));
bgp_community.add((64699,174));
}
...
if (net = 2a07:1500:131B::/48) then {
bgp_community.add((64600,2914));
bgp_community.add((64600,174));
bgp_community.add((64600,3356));
bgp_community.add((64600,1299));
bgp_community.add((64600,2516));
bgp_community.add((64600,3257));
bgp_community.add((64600,6939));
bgp_community.add((64600,63956));
bgp_community.add((64600,17819));
bgp_community.add((64600,7922));
}
accept;
};
}
The config produced uses the Vultr BGP communities (A) to allow the per link (upstream providers) prefixes to work.
Using RIPE Atlas you can see (darker blue = higher latency) that the anycast roll-out by default is actually pretty good, but there are a few details worth pointing out, where it has gone wrong.
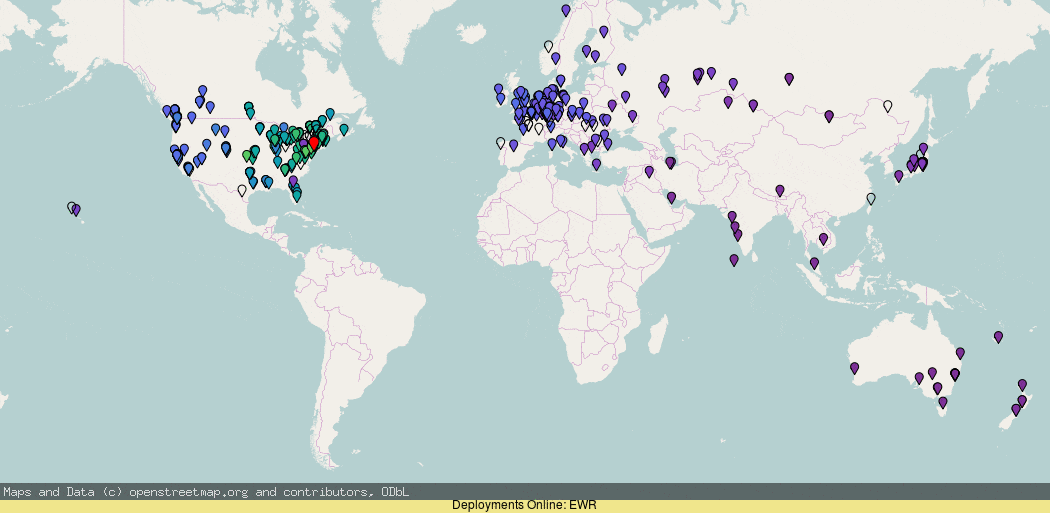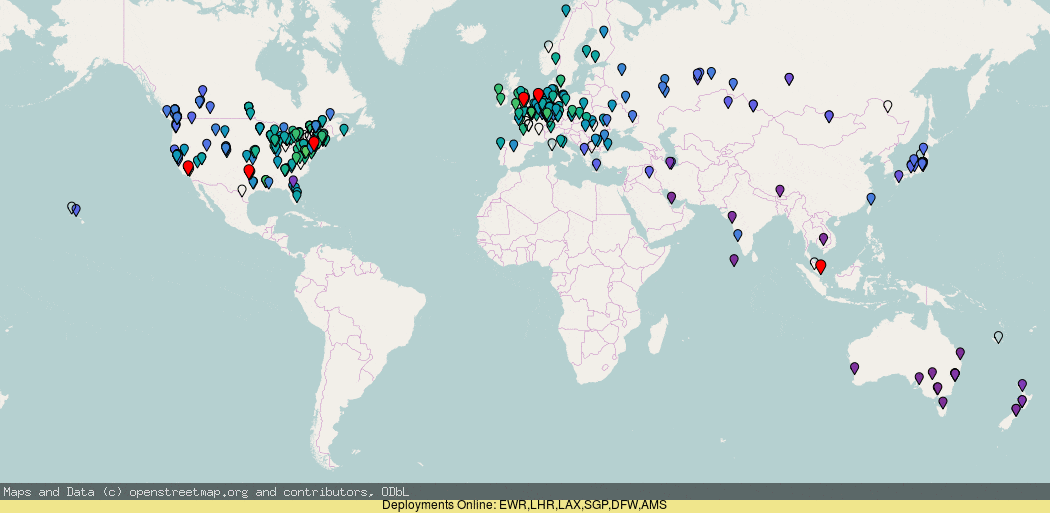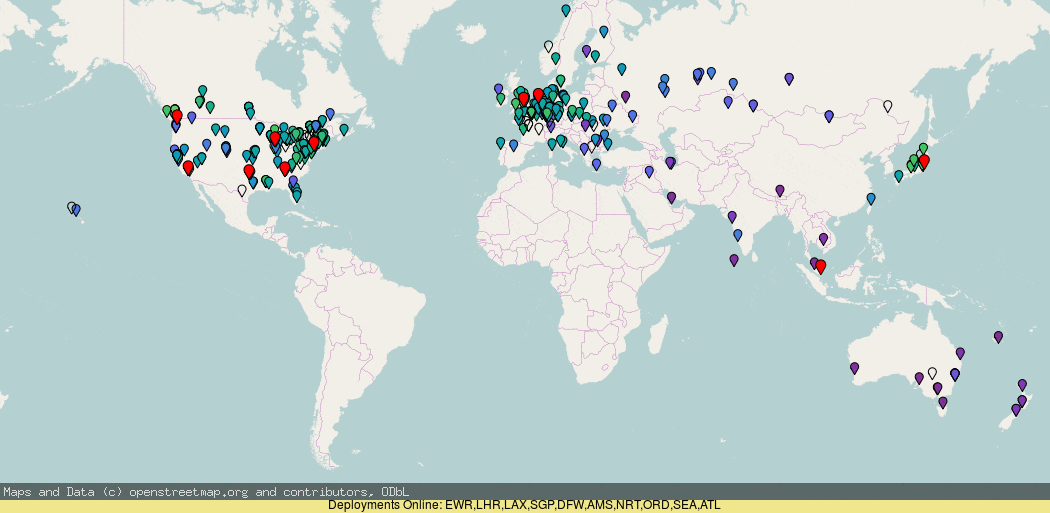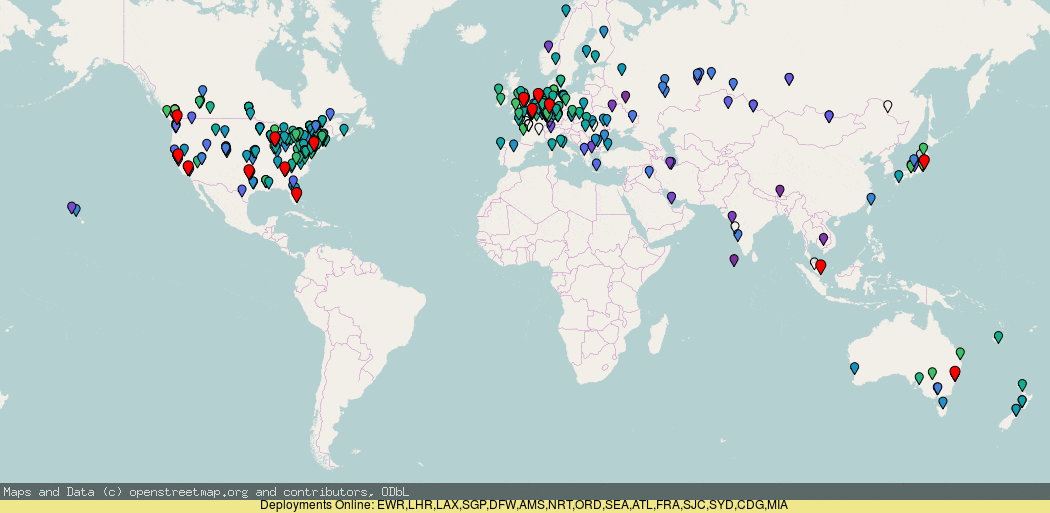
If you look closely, you will notice that the addition of London (LHR) deployment actually made the west coast ping worse! And the deployment of more PoPs on the west coast did not make a massive improvement (though it did for Canada).

To prevent this from happening, we can use DNS to ensure those clients go to the correct coast:
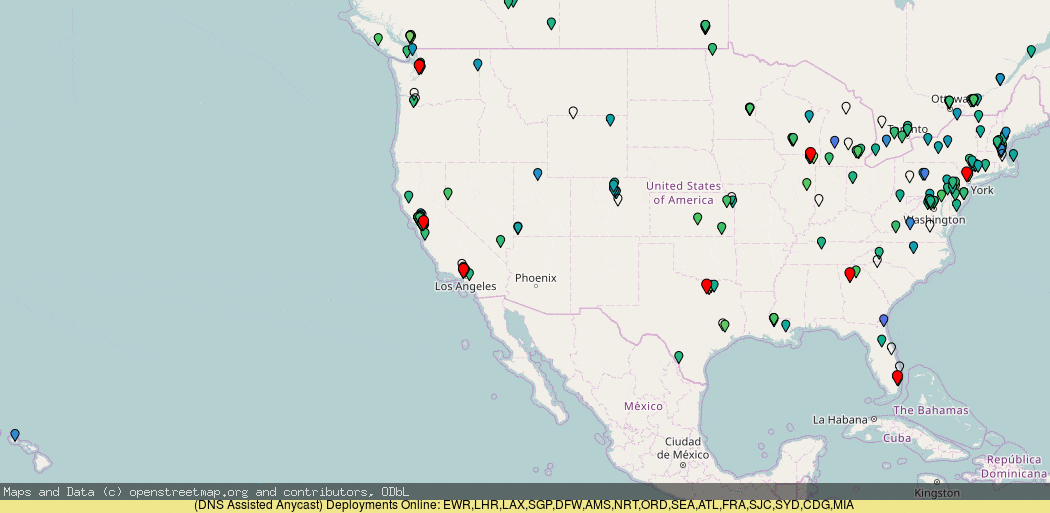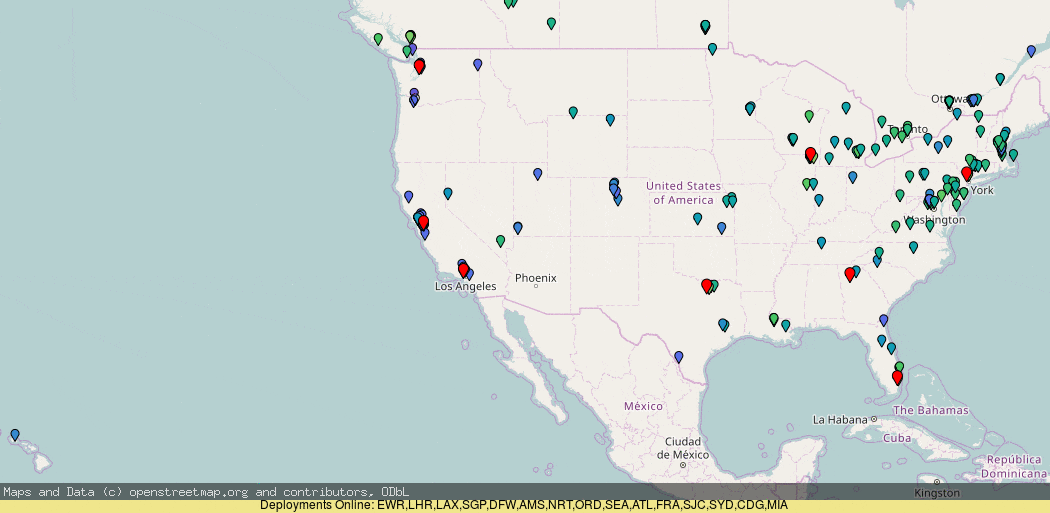
Here, it makes quite a big difference in sorting out those cases of mis-routing.
This takes the latency histogram (produced using mmhistogram) from:
Values min:0.54 avg:72.35 med=47.76 max:287.74 dev:61.90 count:448
Values:
value |-------------------------------------------------- count
0 | * 5
1 | * 5
2 | ** 6
4 | **** 12
8 | ******************* 53
16 | *************************************** 104
32 | ******************** 54
64 |************************************************** 133
128 | *************************** 72
256 | * 4
… to a surprisingly low:
Values min:0.54 avg:32.51 med=21.32 max:219.32 dev:33.56 count:455
Values:
value |-------------------------------------------------- count
0 | ** 9
1 | * 6
2 | ** 10
4 | ******** 31
8 | ************************ 86
16 |************************************************** 173
32 | ************************ 84
64 | ************* 45
128 | *** 11
256 | 0
Or as a graph:
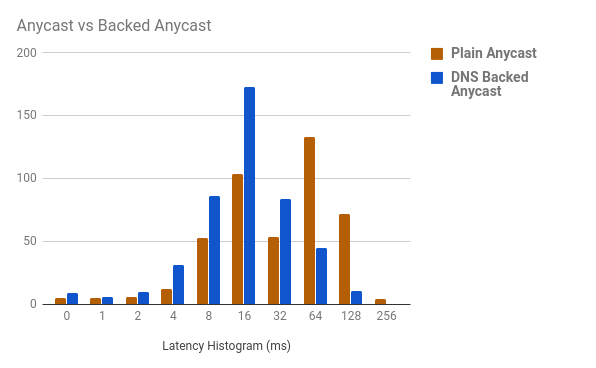
Overall, if you do not have the resources to ensure that your providers are consistent over all regions, this is a great way to ensure that your traffic follows a (hopefully) logical path.
The only downside of this approach is that it would be cost prohibitive to apply on IPv4, as the amount of IP addresses required are very high and the world is a tad short of IPv4.
I hope you have found this interesting, and I hope to have more networking content around soon. You can use my personal blog’s RSS, or my Twitter, to ensure you know when that happens!
Ben Cox is a systems engineer from London, who started off with a background in web security and has found a fascination in Internet infrastructure and protocols. In his spare time he tinkers with old and new protocols to bring them to life.
Editor’s note: The technique discussed in this article uses bits of address space to carry information. This use of address space may not be recognised by the address usage policies of Regional Internet Registries, affecting the ability of an address holder to receive further address space. Operators interested in this practice are encouraged to participate in the Policy Development Process to provide guidance to registries when assessing requests for additional resources.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.