

This is the second post in my series on NATs, based on my AusNOG 2016 presentation. In the first post, I discussed Network Critical Success Factors (NCSFs). In this post, I detail the trouble with Network Address Translation (NAT).
The trouble with NAT
Now that we have described the Network Critical Success Factors (NCSFs), we’ll use them to evaluate Network Address Translation (NAT).
I’ve been using the acronym NAT as a generic term. Per RFC2663, there are two forms of NAT – “Basic NAT” which involves one-to-one address translation, and “NAPT” or Network Address Port Translation, where many internal addresses are translated to a single external address. NAPT is the most commonly deployed form of NAT.
The troubles with NAT apply to both forms of NAT, so I’ll continue to use the term NAT in this article.
Packet modification failure
At face value, the term “Network Address Translation” would sound like it is as simple as changing the IP addresses in the outer IP packet header – which is what I believed when I first learned of NAT back in 1996.
Unfortunately that is not the case. Depending on the type of NAT occurring, and the application protocol traversing the NAT device, modifications need to be made to multiple field values in the IP header, the transport protocol header and possibly even the application protocol payload. If the IP address is carried in the application protocol in text form, that could even mean increasing the size of the packet, which might push the packet size over the next link MTU, meaning fragmenting the packet. And if the transport layer protocol is TCP or similar, adjusting the current and every subsequent sequence number…
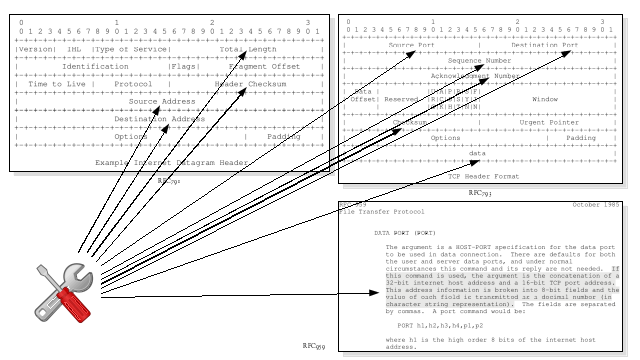
Due to the number of changes necessary, the need to understand the transport layer protocol, and possibly the application layer protocol, there are many opportunities for NAT to fail. For example:
-
Failure to understand the transport layer protocol and therefore being unable to successfully modify the transport layer protocol header if necessary. For example, DCCP (RFC4340) and SCTP (RFC4960) are two alternative transport layer protocols that could provide benefits over UDP and TCP, however, they cannot be deployed because NATs don’t commonly understand them.
-
Failure to understand the application layer protocol and therefore being unable to successfully modify the application layer protocol payload if necessary. This is the issue I encountered in 1996, where the NAT device did not understand the NetBIOS Name Service protocol (RFC1002).
-
Failure to see the transport layer header or application layer protocol header or payload due to encryption, and therefore being unable to modify the transport layer header or application header or payload if necessary.
-
In cases where modification is successful, strong end-to-end packet authentication may cause the receiver to consider the packet to have been a victim of a “Man-In-The-Middle” modification attack somewhere in the network, and the authentication check fails.
The result of any of these failures to understand and modify the packet may result in the packet being either dropped by the NAT device or dropped by the final destination host upon arrival.
Referring to our NCSFs, this dropping of packets caused by the failure of the NAT process, is an availability failure. Considering our baseline minimum of greater than 99% packet delivery, for some types of packets that have been submitted to the network, the delivery success rate is 0%. Other types of packets, successfully understood and modified by the NAT, will achieve the 99% arrival minimum success rate (unless there is some other fault in the network).
State / Loss of state
In most cases, a NAT device needs to remember very specific details of previous packets it has processed, so that it can perform modifications on subsequent related packets.
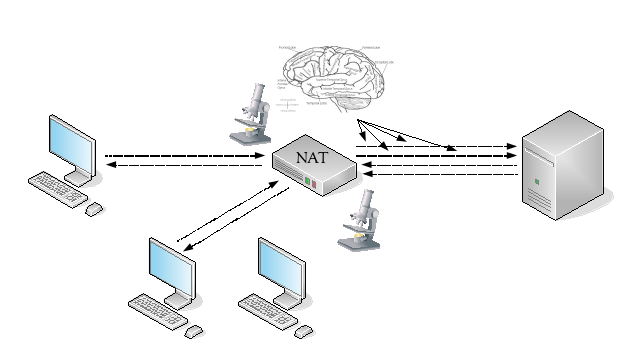
This necessary detailed knowledge or memory of past packets is known as “state”.
As state is created based on packet contents that can differ for each packet, such as the IP addresses or transport protocol port numbers, the NAT device is now vulnerable to a state exhaustion attack, where packets are purposely created to consume the NAT device’s state capacity until it cannot create any further new or additional state. The way the NAT device reacts when state capacity is exhausted is implementation dependent – it may stop operating entirely, or may not allow new application sessions while existing application sessions continue.
Another issue is the loss of state information if the NAT device fails. As the state information is necessary to perform the NAT function on subsequent packets, loss of NAT information may cause any current application sessions traversing the NAT device to fail. Loss of state would still impact the application sessions even if an alternative network path between the application endpoints exists. The fate of the application session is tied to the fate of the NAT device, regardless of any available network redundancy.
Some NAT devices support device redundancy by providing a state synchronization mechanism over a dedicated link between the devices. While this overcomes the issue of loss of state information, the infrastructure to support the state synchronization may be expensive if geographic diversity of the NAT devices is required. Examples of possibly expensive NAT redundancy links are dedicated links spanning diverse, non-adjacent racks within a single data centre, incurring cross-connect costs, or dedicated NAT redundancy links spanning geographically diverse data centres.
In terms of our NCSFs, the need for state, the consequences of loss of state, and the possible expense of NAT device state redundancy impacts the availability and budget NCSFs.
The operation of the conventional IPv4 and IPv6 forwarding function is stateless. There is no need to remember anything about past forwarded packets. Failure of the forwarding device will impact a small number of in-flight packets. They’ll be resent over an alternative network path if it exists, with a high chance of arrival success if the transport protocol on the hosts, such as TCP, recovers from packet loss using retransmission.
Peers require 3rd party assistance
There are broadly two types (or architectures) of applications:
- Client/server
- Peer-to-peer
Client/server applications are ones where the server holds or provides some property or function that cannot; isn’t practical to retain or perform; or is best not held or performed on the clients. For example, a client/server database has all of the data residing on the server, meaning there is a single authoritative copy of the entire set of data at the server, and the clients request and receive the data they require at the time they require it, meaning that it is also the current data at the time of the request.
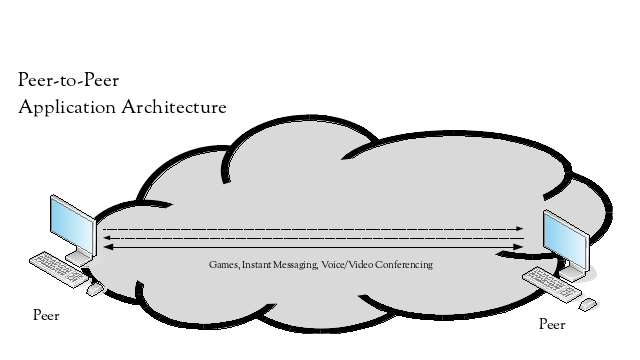
Other applications are or suit peer-to-peer, meaning there is no strong boundary or delineation between devices providing a property or function. The application peers can equally provide services to or make requests from the other application peers. Applications such as games, instant messaging and voice or video conferencing can suit a peer-to-peer application architecture.
Peers in an application that follows a peer-to-peer architecture expect to be able to communicate with each other directly. However, when these peers reside behind different NATs, they cannot. To communicate successfully, they need the assistance of a 3rd party host that is visible to both of the peers.
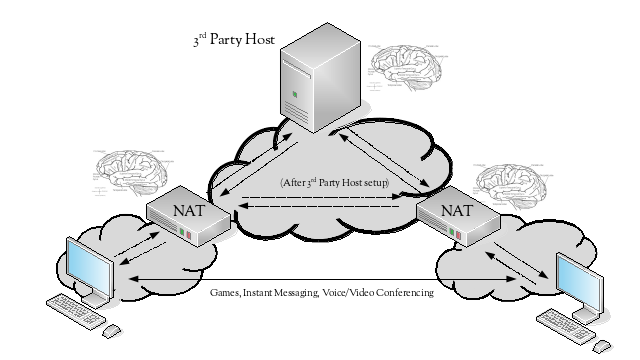
The 3rd party host either acts as a relay for all communication between the peers, or acts as a broker to help set up a more direct path between the NAT devices in front of the peers, as occurs with STUN (RFC5389).
The now required 3rd party host becomes another point of failure for the application, in addition to the points of failure the NAT devices introduce due to them having to maintain state.
If the 3rd party host is acting as a relay for all communications between the peers, then its failure will cause communications between the peers to fail, despite there likely being an alternate path between the NAT devices. It may also become a performance bottleneck if it is acting as a relay between many sets of peers.
Finally, the 3rd party host has to be trusted. If it is acting as a relay between peers, it is a natural interception point for communications between the peers. This interception could only be avoided if end-to-end encryption and authentication is used between the peers, however this may prevent the 3rd party host being able to act as a relay.
Even if the 3rd party host is only involved in establishing a more direct communications path between the NAT devices, it still has visibility to the metadata of which peers communicated with other peers and at what time.
The ability to trust the 3rd part host becomes particularly important if it resides somewhere on the Internet, which is likely to be the case in the scenario shown in the diagram above. It is quite possible that “free” or “public” 3rd party hosts have been purposely set up to intercept traffic from unsuspecting peers. Various parties on the Internet can have a strong incentive to provide this sort of “free” 3rd party host service, if the benefit is easy and secret traffic interception.
Considering our NCSFs, the need to use a 3rd party host has had an availability and performance impact.
With the requirement for a 3rd party host, due to the limitations imposed by NAT, what has really happened is that applications that would benefit from a peer-to-peer model have been forced to adopt a client/server model.
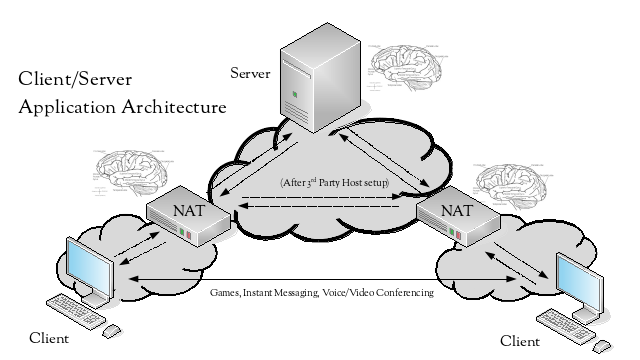
If NAT wasn’t necessary, then the architecture becomes a lot simpler – the peers can directly communicate, so there may be no need for a 3rd party host.
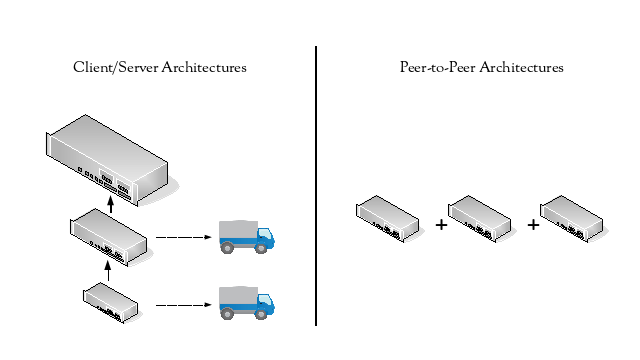
A final observation is that client/server architectures tend to be scaled using a vertical scaling approach, where as peer-to-peer architectures tend to be scaled using a horizontal scaling approach. As mentioned before, the advantage of a horizontal scaling approach is that when scaling, capacity is only added to the system, unlike the vertical scaling approach, where an existing resource also needs to be replaced when adding capacity.
What is the nature of the Internet Protocols?
As we’ve just seen, operating in the presence of NAT can cause a host to act as, and therefore commonly be classed as, having an exclusive role of either being a client or server.
So are the roles of hosts acting as either clients or servers in the nature of the Internet Protocols? Do the terms “client” or “server” appear in the IPv4 or IPv6 RFCs?

No, they don’t.
IPv4 (RFC791) doesn’t specifically describe device roles, however IPv6 (RFC2460) does:
-
Node – a device that implements IPv6.
-
Router – a node that forwards IPv6 packets not explicitly addressed to itself.
-
Host – any node that is not a router.
So this can only mean that nodes in IPv6 (and by implication IPv4) are peers at the IP or network layer.
So what does being a IP layer peer mean? It means that a device with an IP address should be able to:
-
Send packets to and receive packets from all other devices with IP addresses attached to the same network, security permitting.
-
Use its own IP address to identify itself to others when referring to itself.
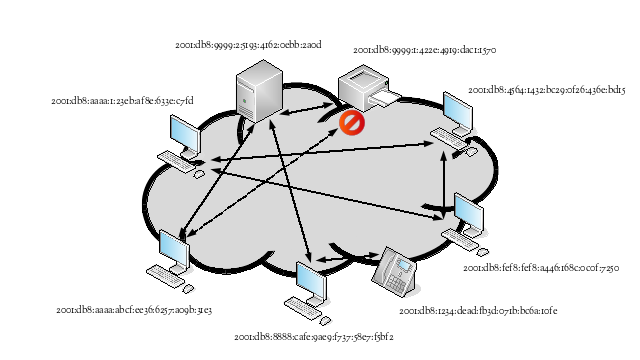
The following shows examples of inter-application communication flows when IPv6 hosts have the ability to act as peers of each other. The hosts are spread across different IPv6 networks and different subnets within the same IPv6 network. Some of the communication flows correspond to client/server applications, while others correspond to peer-to-peer applications. In the case of the printer, direct access is prohibited; print jobs have to be submitted to the print server, which is authorized to send them to the printer.
If the nature of the Internet Protocols is peer-to-peer, then that really means that client/server is just an application level communication model, or architecture over the top of the peer-to-peer network layer. Other applications may suit a peer-to-peer communications model. There is nothing to prohibit an application choosing a mix of client/server and peer-to-peer communications if it suits. The peer-to-peer network layer facilitates any of the application communications models or architectures the application developer chooses. Facilitating application developers helps facilitate the application end-users – our ultimate customers.
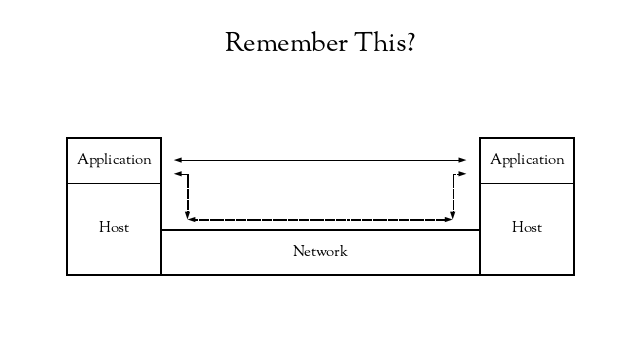
If we return to our simplified communication model, the thing to notice is that the hosts are not designated clients or servers – it is just application instances communicating with each other, utilizing the services of the underlying hosts and network.
Mark Smith is a network engineer. He has worked at a number of networked organizations since the early 1990s, including a number of residential and corporate ISPs. Most recently he has been working in the AMI/Smartgrid sector.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
An excellent analysis. Thanks. The reality is that IPV4 has been hacked to death to meet new needs. I personally believe IPV6 will need some rework in the next few years. I’m also still disappointed with the slow IPV6 uptake.
Thanks.
>> I personally believe IPV6 will need some rework in the next few years
Hi Gregory, what kind of rework do you think is needed for IPv6?