

In early September, I presented at the AusNOG 2016 conference on the topic, “The Trouble with NAT”. APNIC asked me to write a follow up blog series covering my presentation. This is the first post of three, and in this post I’ll discuss the concept of Network Critical Success Factors (NCSFs) before getting into ‘the trouble’.
It was 1996…
…and I was attempting to deploy Network Address Translation (NAT) for the first time for a corporate customer. NAT was fairly new; I was new to NAT; and the Internet was fairly new to mainstream corporates and enterprises.
My customer had built a large international network and had used RFC1918 private addressing. As dial-up Internet access was also becoming more widely available, they wished to connect their network to the Internet so that their staff could access their email as well as their Microsoft Word documents from home.
Unfortunately, the NAT implementation that I’d recently been trained on and that my employer supplied could not perform address translation on the IP addresses carried inside the payloads of the NetBIOS packets necessary for the staff to access the Windows NT file server where their documents were stored.
It disappointed me that I was not able to fully solve my customer’s problem. It was also the first experience I had of NAT causing something that I wanted to achieve, to fail. My AusNOG presentation and this article are based on that experience and subsequent ones with NAT and the trouble it causes. It is also one of the main reasons why I’ve made IPv6 one of my technical focuses.
A lot has been written about NAT and its limitations. One perspective I haven’t remembered coming across is that of NAT from primarily a network operator’s perspective.
On being a network operator
At some time or other all network engineers will have seen this diagram, showing the way data flows between applications over an Internet Protocol network:
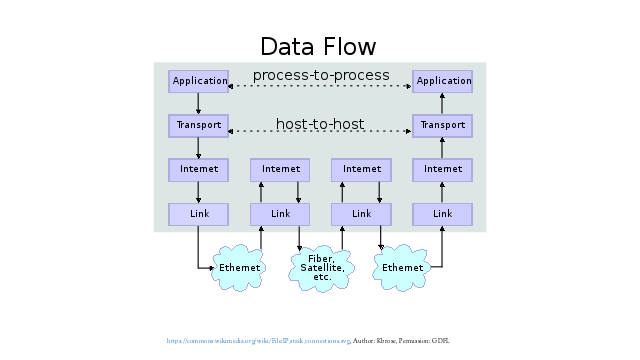
This diagram can be simplified into three main entities: applications, hosts and the network.
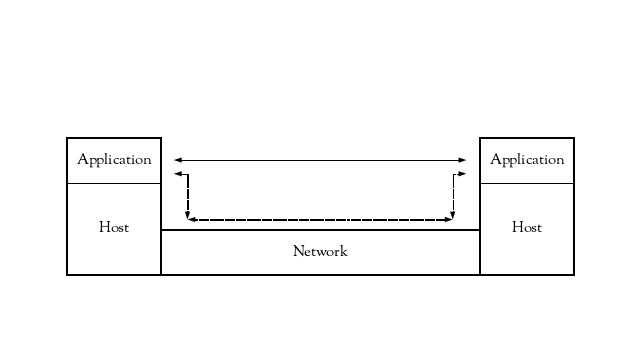
The entities that have the intent to communicate with each other are the networked applications; the hosts and the network assist the applications with that communication. A different perspective on this simplified model is to include and consider the entities using and supporting the applications, hosts and network:
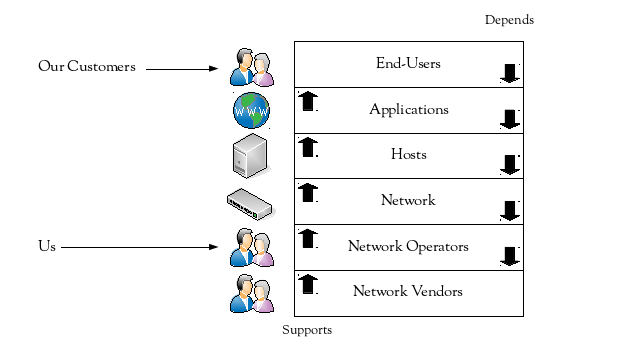
As network operators, we directly support the network. However, the network only exists to facilitate the communications of networked applications. That makes our ultimate customers the end-users, and their satisfaction is our fundamental goal.
Network Critical Success Factors (NCSFs)
So if we’re operating the network to support end-users and their applications, what are the critical things we need to achieve? I think there are four NCSFs. They’re pretty obvious and straightforward, however we’ll discuss them because we’ll be using them to later evaluate NAT.
Available
The first NCSF is that the network needs to be available when the end-users and their applications wish to use it. The end-users and their applications therefore drive and define the network availability requirements.
In more practical terms, that means that when a network application asks its host to facilitate communication with another remote application end-point, packets that the host submits to the network for delivery should have a high probability of being delivered to the destination host, within an acceptable time frame.
While the availability required is dependent on who is using the network and when they need it to be available (for example, compare availability for an ISP versus a corporate network serving users between the hours of 8am through 6pm, 5 business days of the week), I think it is useful to have a minimum baseline for how many packets the network needs to deliver successfully between any of the attached hosts.
To determine this figure, we can look to the design assumptions for the Internet Protocols. “The Design Philosophy of the DARPA Internet Protocols” mentions that “as a rough rule of thumb for networks incorporated into the architecture, a loss of one packet in a hundred is quite reasonable”. Although the “network” being referred to is what is now more commonly known as an individual link, and is being used to describe when link layer reliability mechanisms may be necessary, we can extrapolate this to mean that between any pair of hosts attached to the network, the baseline minimum of successful delivery needs to be at least 99 out of every 100 IP packets.
In other words, when a host submits a packet to the network, it should have a greater than 99% chance of arriving at the destination host.
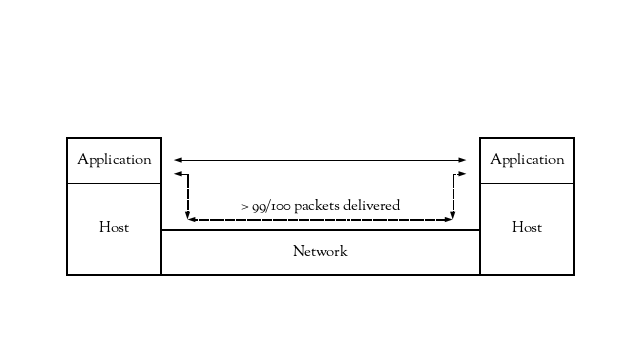
One thing to notice is that no specific type of IP packet has been mentioned. This delivery percentage applies to IP packets regardless of whether they’re carrying ICMP, TCP, UDP or any other upper layer protocol.
Scalable
Another NCSF is that it is scalable. In very simple terms, this means that the network can be grown along a number of dimensions as need requires. The sort of scaling dimensions for a network are:
- Network elements (routers/switches)
- Links
- Network capacity
- Hosts
- Geographic sites
A scalable network is really more of an inherent requirement of a network than an explicit one driven by the end-users and the applications they wish to use. As a network operator, it would be unacceptable for us to say to an end-user (who needs to attach to the network) that “the network is full”.
Two common scaling models
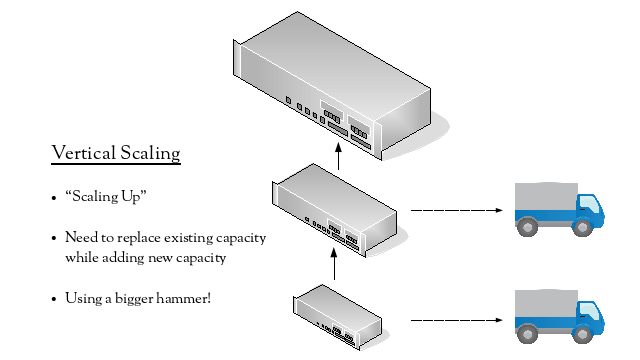
There are two common scaling models, which we’ll use to later consider NAT. The first one is vertical scaling, also commonly known as “scaling up”. This involves replacing the existing device with a larger one, meaning that both the existing device’s capacity is replaced as well as additional new capacity being added. This can be described as “buying a bigger hammer”. Hopefully, the existing device can be redeployed somewhere else in the network, or at least sold to recover some funds.
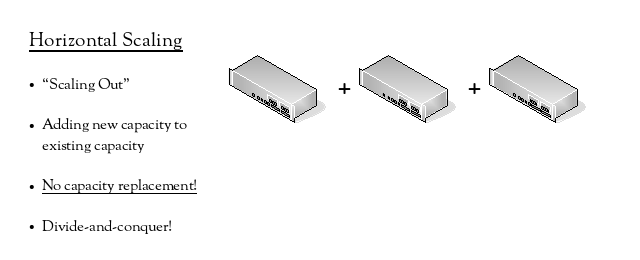
The second scaling model is horizontal scaling, or “scaling out”. In this model, capacity is added without having to replace existing capacity, usually by adding another device of the same type as those that already exist. This can be described as a “divide-and-conquer” approach – the large problem is broken down to smaller versions of the same problem and solved with multiple smaller devices of the same type. The major advantage of this model is that there is no replacement of existing capacity.
Adequately performing
This NCSF should need very little explanation. The network needs to perform adequately in terms of:
- Throughput
- Latency
- Packet delivery success
- Packet order
As before, the network performance requirements are driven and defined by the end-users and their applications.
It is tempting to call this NCSF “high performing”. While everybody would like high performance, it can then be easy to fall into the trap of providing performance that is far in excess of what is necessary to support the current and short-to-medium-term future needs of the applications. This unnecessary performance may be at the expense of some of the other NCSFs or at the expense of something else the organization who owns the network may need.
Constrained by budget
It would be rare to have an “open chequebook” or an unlimited budget when constructing and operating a network. Even if that were the case, we need to be responsible with the funds available, as if they’re spent on the network, they cannot be spent on something else. So within the constraints of the budget, we need to achieve availability, scalability and adequate performance.
Relationship between NCSFs
I think NCSFs have precedence, with availability being the most important to achieve, after that scalability, and finally adequate performance, with the overarching constraint of the budget.

Scalability and adequate performance are of no value if the network isn’t available when the end-users need it to be. Adequate performance doesn’t matter if the network can’t be scaled to attach a new end-user or geographic site.
Mark Smith is a network engineer. He has worked at a number of networked organizations since the early 1990s, including a number of residential and corporate ISPs. Most recently he has been working in the AMI/Smartgrid sector.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.