

The Network Management session at APRICOT 2026 brought together four presenters to share practical, data‑driven insights into how operators can better understand and optimize their networks.
Covering topics from DNS‑based analysis of Content Distribution Network (CDN) efficiency to open source zero-touch deployment solutions, the session highlighted how careful instrumentation and thoughtful tooling can reveal surprising truths about network behaviour, and guide more effective operational decisions.
What your DNS logs say about CDN efficiency
Presenter: Abu Sufian
Abu Sufian, Head of Technology at ADN Telecom (and an APNIC Community Trainer), presented on information you can find in your DNS logs, and what this says about CDN efficiency.
Most ISPs in Bangladesh rely on public DNS resolvers like Google or Cloudflare, with 60% – 70% of visible DNS being resolved through the use of these public DNS services. Optimal content location selection is in the hands of third parties, not directly computed by the asset owner or the client.
Without some work, operators have almost no insight into where their users’ CDN traffic is really going, which cache nodes serve them, and whether those are on-net or global. Since choices made by DNS servers will directly affect cost (of service delivery) and quality (delay to content), it’s important to the bottom line of a business to understand how DNS is informing these choices.
Abu showed how the CDN source-per-query could be identified using cost-effective open source tools without impacting production systems. He used PowerDNS Recursor, ClickHouse, and Grafana to build a system for visualizing DNS queries, fed from live resolver logs, to classify CDN placement from Facebook and Google.
PowerDNS was chosen because its Python/Lua scripting mechanisms made it possible to identify and capture queries to specific parent domains. These were fed to ClickHouse in near-real time as a JSON data feed. The ClickHouse database was simple, just three fundamental tables for:
- Raw queries
- CDN-IP map selected
- A data reduction over these primitives
Mapping from this into a Grafana dashboard was logically simple and provided both high-level visual overviews and a drill-down model into the specific IP bindings and their mappings.
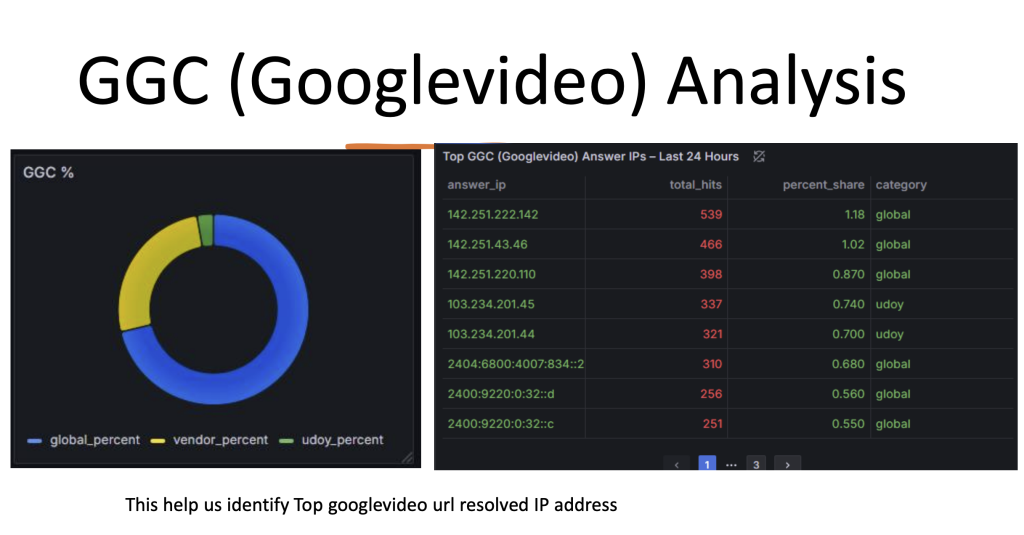
Abu said that the project validated ADN Telecom’s search for opportunities to analyse data in the DNS, and has potential for future integration with Border Gateway Protocol (BGP) data, such as origin-AS, or a NetFlow analysis approach. It’s available on GitHub for public contributions.
Slides: What your DNS logs say about CDN efficiency
Grafana-powered traffic dashboard for customer networks
Speaker: Munkhtulga Bayarkhuu
Munkhtulga Bayarkhuu, a Network Planning Engineer at Skymedia in Mongolia, presented a dashboard system his company has been developing in Grafana for enterprise customers. It’s a network bandwidth monitoring solution built using open source tools. The project came from an enterprise customer’s interest in understanding a breakdown of where their traffic comes from, and a request for help coding a solution.
Skymedia uses LibreNMS for network management, which provides information about device health and counters, but doesn’t provide traffic breakdowns by source and destination. Akvorado is used for Internet Protocol Flow Information Export (IPFIX) and NetFlow data analysis, and provides flow-level aggregations and diagnostics.
The customer required Role-Based Access Control (RBAC) to protect against potential leakage of unassociated flow information, privacy concerns, and competitor risks. Akvorado doesn’t provide RBAC, making it unsuitable for direct customer use. Instead, says Munktulga, Skymedia decided to design a Grafana dashboard that unified LibreNMS and Akvorado outputs under an RBAC model.
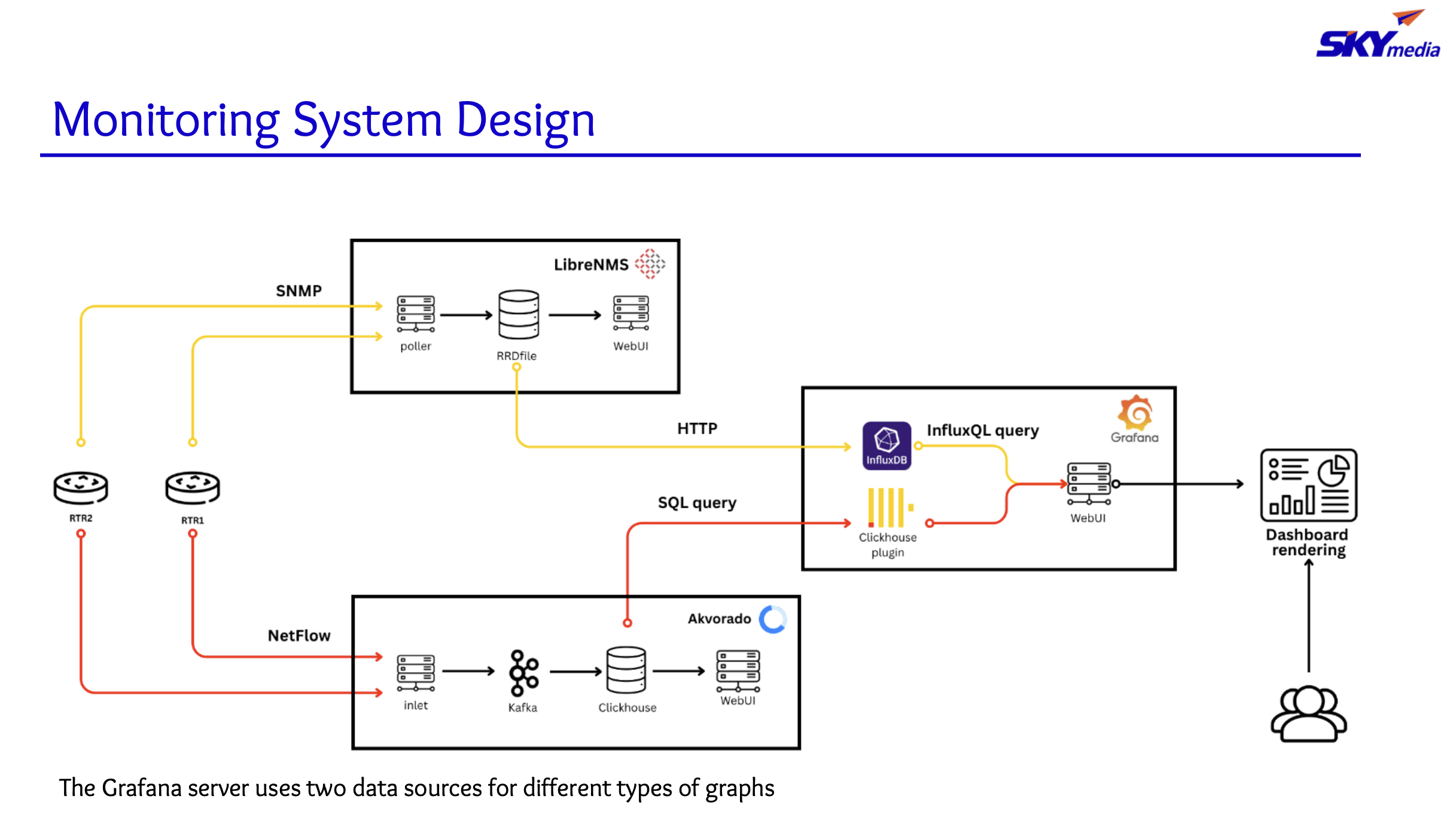
Khuslen (also from Skymedia Mongolia) continued Munkhtulga’s presentation with a dive into the internal systems architecture.
By visualizing everything through a single Grafana dashboard, the solution removes the need to switch between multiple monitoring systems, making it easier for the customer to use while improving accuracy and data security. Data is integrated from LibreNMs using InfluxQL, and from ClickHouse using an Akvorado plugin. The integrated data is presented through a web user interface. The LibreNMS feed operates on a five-minute cycle, slightly behind real-time, but isolates the query load to the customer. The Avkorado feed is a direct SQL query set, which means the dashboard has some exposure to risk of data loss if that feed goes down in real-time.
The project had some challenges with data flow and high data retention costs, which led them to modify their workflow. They added a ‘clone’ system with lower retention, and did more SQL tuning to reduce the query load on ClickHouse. SQL tuning was needed because dashboard elements directly and asynchronously queried the ClickHouse database. An attempt to integrate the data flow inside InfluxDB didn’t work, and the likely path out is reimplementation to architect a more resilient database structure that isolates the customer’s load.
The presentation showed how to make a functional, usable, open-source answer to a customer question: “Where is my traffic going?”
Slides: Grafana-powered traffic dashboard for customer networks
Deployment automation using a Source of Truth (SoT) tool
Speaker: Ulsbold Enkhtaivan
Ulsbold Enkhtaivan, an IP Network Manager from Mobicom (and also an APNIC Community Trainer), presented on mobile operator backhaul network tools. These tools provision the data used to get the radio network facing customers ‘glued’ into a ground-based, reliable, high-bandwidth system. With frequent updates in the field reflecting changing network load and customer expectations on radio service, Mobicom needed a ‘zero touch’ deployment method. Ulsbold described the system his team designed to configure routers, using NetBox and Zabbix, with Python as a glue and configuration logic system.
This allows people in Ulsbold’s role to use email-based workflows to confirm configuration changes in the field. NetBox and Zabbix are then able to track deployment status and move systems from planned to active deployment. Jinja was used to template JSON-to-configuration conversions targeting multiple vendor backends. Paramiko, an implementation of the Secure Shell (SSH), was used to send configuration changes into the live configuration systems through device serial number coding, and a fetch-change-test-rewrite cycle.
Zabbix integration with Netbox is built on integrations on GitHub. The NetBox system became the ‘source of truth’ about devices on the network, and Ulsbold said the integrity of the serial-number-to-configuration mapping became critical. Integration with systems monitoring ensured that documentation of the complete life cycle of device identity, device availability, console access, templated change, and functional active configuration was captured and maintained in NetBox.
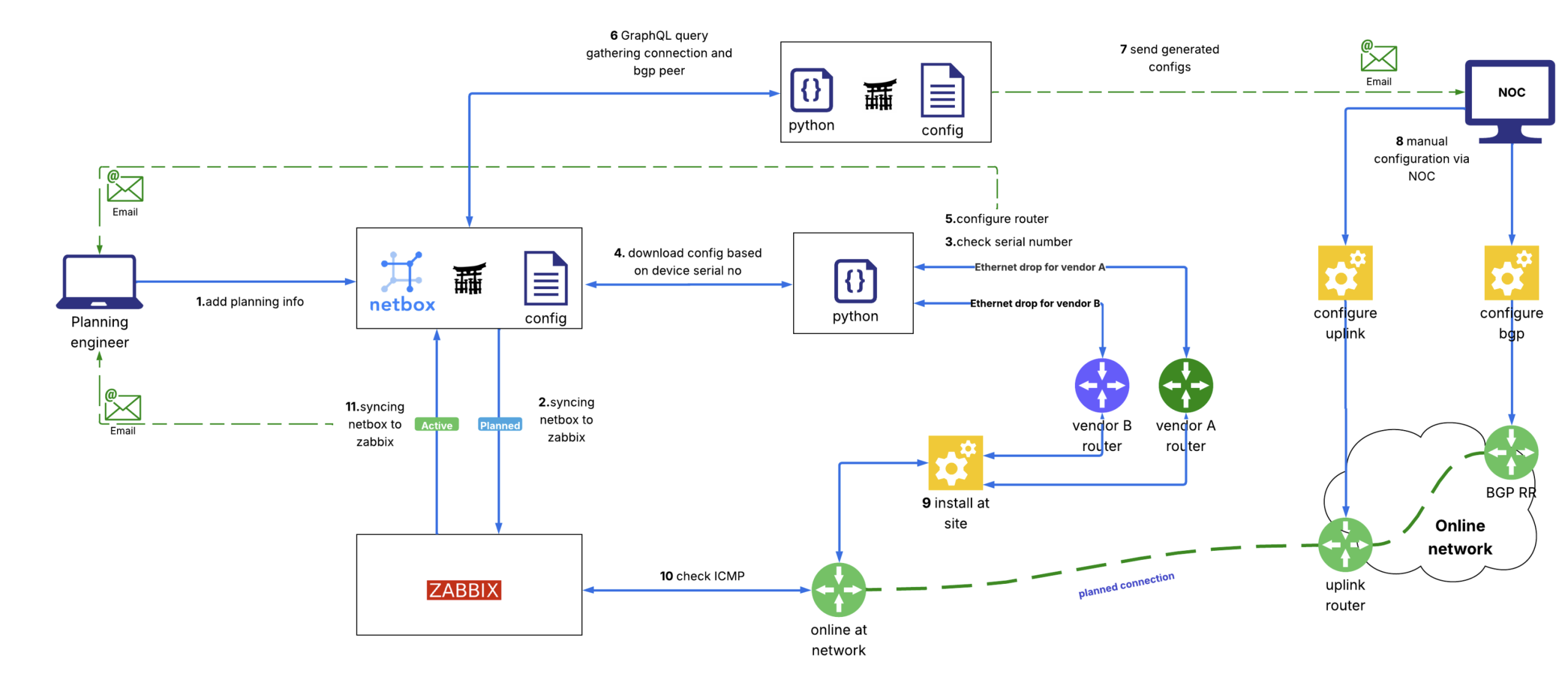
The system has been extended to identify devices from interface IDs, with the intention of adding automation for device-to-device relationships. At this time, the system is mediated manually to avoid critical routing and switching plane failures.
Ulsbold says that the system has improved confidence, provides a source of truth, and reduced the wage costs of manual intervention and on-site demands. There are some scaling issues, but he says these will be better managed in the future.
Slides: Deployment automation using a SoT tool
The evolution of network configuration management
Speaker: Tim Raphael
Tim Raphael, the IP Automation Regional Product Manager for Nokia, spoke about a history of network configuration management approaches seen at Nokia and in the wild, and potential future paths.
Tim began by touching on early network configuration using direct command input to serial consoles, with NVRAM-backed storage of the configuration locally. Typically, text files of configuration were serially loaded from a UNIX system. These had to be typed in by hand due to the limitations of the technology of the time.
RFC 789 from 1981 stands as a historical record of note by Bolt Beranek and Newman of the impacts of configuration changes on the IMP/TIP ARPANET routers of the time, and as a call to action for systematic configuration management. It’s the ‘birth’ of network management protocol.
Tim discussed RFC 1028, which specified Simple Gateway Management Protocol (SGMP) in 1987, and RFC 1021, which specified High-level Entity Management System (HEMS) in the same year. Common Management Information Protocol (CMIP) came from the International Standards Organization (ISO) — rather than IETF RFC methods — in 1990.
The presentation showed how these efforts led to the idea of standardizing information about network devices from across vendors in a Management Information Base (MIB). The MIB was an ASCII text file that used Abstract Syntax Notation One (ASN.1) to catalogue namespace, types, and structural dependencies through the Object Identifier (OID) mechanism. But, MIBS were slow, with long round-trip times (RTT) that returned collections element by element. By the 1990s, with thousands of MIB entries, the volume of query-response calls was huge.
This led to the emergence of the command-line interface (CLI) systems, either direct to the device or layered over an abstraction like SNMP. Protocols like TFTP became common for initial network device configuration.
The Transaction Control Language (TCL) based ‘expect-send’ pattern allowed network operators to move from modifying live configuration by entering commands manually, to applying complete configurations in one shot. The logic was machine-driven, said Tim, but emulated manual entry. The next obvious step down this path was to design an Application Programming Interface (API) that provided the same methods to perform request-response changes.
This gave a standard format for sending and receiving configurations, over SSH or TLS, with opportunities for mutual authentication, and uplift from plain text to XML and JSON. Parsing improved, and performance cost dropped massively.
By 2010, Yet Another Next Generation (YANG) had emerged as a human-readable notational data model for network topologies. It has fixed nested objects and consistent logical models of containers, with lists and leaves. Vendors standardized around using simple typed data for device configuration. YANG provided protocol independence to the specific XML or JSON required per device, and allowed an ‘openconfig‘ project take shape.
In 2015, the Google gRPC framework (originally called ‘stubby’) was open sourced, including, but not limited to:
- Protobufs are an efficient binary format.
- gRPC Network Management Interface (gNMI), a protocol for network device configuration and state management, especially using YANG.
- gRPC Network Operations Interface (gNOI) is a protocol for performing actions on network devices.
This combination of open source software allowed operators to manage devices from different vendors using common RPC request-reply sequences.
Legacy models of network management were imperative, with specific commands issued to effect specific changes. Newer models are declarative: The desired end state is specified, to be reached using device capabilities. It isn’t a natural fit for network devices that act on a complex ‘network product’, Tim says, but it has significant benefits. If you are willing to accept ‘eventual consistency’ using a transactional ‘done or none’ model in your network, you get access to the complete continuous integration, continuous development (CI/CD) workflow. You can treat your network like code, with a rich ecosystem for life cycle management, testing, and deployment.

Finally, Tim walked through Artificial Intelligence (AI) approaches to diagnostics. He suggested use cases that could be a good fit, like root-cause analysis, and digesting alarms and event logs. In these cases, AI can help operators understand, mitigate, and prevent incidents in their networks. Tim also pointed to AI as a mechanism to propose changes (and show reasoning), or to assist in a security audit. This cautious approach is sensitive to the criticality of the network configuration process and retains humans in the loop for functional changes.
Slides: The evolution of network configuration management
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.