

Marco Davids and Willem Toorop co-authored this post.
DNS nameservers are crucial for the reachability of domain names. For this reason, nameserver operators rely on multiple nameservers and often replicate and distribute each server across different locations around the world. Operators monitor the nameservers to verify that they meet the expected performance requirements. Monitoring can be done from within the system, for example, with metrics like CPU use, and from the outside, mimicking the experience of the clients.
In this article, we focus on the latter. We take the root server system as a use case and highlight the challenges operators and researchers face when monitoring highly distributed DNS deployments from the outside. We also present recommendations on building a monitoring system that is more reliable and that captures only the relevant metrics.
Distributing DNS nameservers
The DNS is a prime example of a decentralized and distributed system. For example, it is a decentralized system in that SIDN is responsible for .nl, Verisign is responsible for .com, and you, the reader, are responsible for your own domain names. It is also a distributed system because each of those operators uses a geographically dispersed set of authoritative nameservers to provide information about their part of the namespace.
Probably the most distributed and decentralized service in the DNS is the root zone. The root server system comprises 13 different nameservers, operated by 12 different organizations, all reachable via IPv4 and IPv6. ‘Under the hood’, the nameservers consist of more than 1,900 ‘sites’ (physical or virtual machines) located in networks all over the world. The root server operators accomplish that by using a technique called ‘anycast’. The Internet’s routing protocol, Border Gateway Protocol (BGP), makes sure that queries to each root server are sent to the site that is topologically closest to the machine sending the request in terms of network distance.
The root server system provides information about all authoritative nameservers for Top-Level Domains (TLDs), such as .nl, and also acts as a trust anchor for DNS security extensions (DNSSEC). And, even though a resolver will send relatively few queries to the root servers during a day, the unlikely event of a large-scale outage of the root servers will ultimately have consequences for the reachability of all domain names globally.
The need for external DNS monitoring
Monitoring a group of distributed DNS servers from within (endogenous monitoring) is relatively straightforward and makes use of metrics of both individual server instances and the system as a whole. Basic examples are CPU and memory use, the number of queries received per second, and the serial number of the zone currently being served. More advanced metrics include whether resolvers reach their nearest anycast sites, and the time it takes for requests to reach the nameserver.
However, by relying on internal monitoring only, operators might overlook how their clients experience the service. In the DNS, monitoring from the outside (exogenous monitoring), using vantage points (VPs) that mimic real clients, provides valuable insights. For example, it can reveal problems on the network path towards a nameserver, help during operational changes, and reveal if third parties are trying to meddle with the information the nameserver is providing.
Finally, external monitoring enables others to monitor public DNS services independently. That is where the root servers come into the picture again. As described above, the root server system plays an important role in the DNS. It is, therefore, in the Internet community’s interest that the root servers are available and performing correctly at all times. Today, the only standard operational data for the root server system is the RSSAC002 data, which root server operators provide voluntarily. The ICANN Root Server System Advisory Committee (RSSAC) developed RSSAC047 for use by a future root server system governance body under which root server operators may need to meet contractual obligations for performance, availability, and quality of service.
External monitoring at .nl
.nl relies on three nameservers forming the .nl nameserver system. In total, the nameserver system consists of more than 80 sites located in networks all over the world.
To monitor the .nl nameservers externally, SIDN also relies on the measurements by RIPE Atlas. As with the root servers, all RIPE Atlas probes query our nameservers regularly. The measurements are processed and presented on Grafana dashboards internal to SIDN. Additionally, SIDN relies on anycast-based performance measurements obtained using Verfploeter, which is a hybrid external and internal monitoring tool.
We recommend reading our blog post on the DNS infrastructure for .nl if you would like to know more.
RSSAC047: Metrics for the root
RSSAC047v2 proposes the requirements for the root server monitoring system, including the metrics that the system needs to monitor. The metrics apply both to individual root servers and to the root server system as a whole.
The metrics are:
- Availability: The amount of time root servers and the root server system are unreachable.
- Response latency: The time it takes to respond to a query.
- Correctness: Whether the servers respond with the expected information.
- Publication delay: The time it takes to serve the latest version of the root zone.
RSSAC047 also proposes how measurements should be aggregated and the expected performance levels.
For example, to measure the availability of a root server, the measurement system should send an SOA query for the root zone every five minutes from each measurement VP. At the end of a month, the measurement system calculates the percentage of queries that did not successfully obtain a response (for example, because they timed out). If more than 4% of the queries were unsuccessful, the measurement system flags a root server as not having met the defined availability threshold. Once a month, a report is generated summarizing how the root servers and the root server system as a whole performed for each metric.
Case study: Monitoring the root server system
ICANN has developed an initial implementation of the monitoring specifications and has been monitoring the metrics listed above for more than two years. The software is open source.
The initial implementation is currently still in the development phase, and the generated reports are solely for information purposes. Nevertheless, on multiple occasions, the generated reports did not match the experience and expectations of either operators or the community. First, the initial implementation reported on several occasions that the root server system did not meet the availability threshold. Second, in May 2024, one of the root letters was serving a stale root zone for several days, but the initial implementation did not report anything unusual.
In response, the root server operators Verisign and ISC asked us and NLnet Labs to study the implementation and deployment of the measurement software and the measurements obtained. The goal was to understand whether the root server system was actually performing inadequately. Additionally, during the course of the study, one of the root servers failed to publish root zones on time. We therefore also wanted to understand why the measurement software did not report on the high publication delay.
Monitoring challenges
During the course of the study, we identified several challenges that need to be taken into account when measuring the root server systems externally. We also formulated recommendations on how those challenges could be addressed. You can find more details of our study in our report.
We believe that the insights we obtained are valid in relation to monitoring systems for other distributed DNS services as well. The general challenges we identified and our associated recommendations are considered in the remainder of this article. Our study of the root server system is used for illustration purposes.
Challenge #1: VP selection
The first major challenge when measuring highly distributed DNS systems is the selection of VPs. Where RSSAC047 is concerned, the initial implementation relies on 20 custom VPs, deployed on different cloud platforms and at data centres all over the world.
For RSSAC047, the goal was to strike a good balance between coverage and manageability. In general, however, monitoring system operators have the following three options:
- Decide which sites are most crucial for monitoring, and try to find VPs that allow them to be reached.
- Select VPs that reflect the most ‘important’ clients.
- Select VPs that are evenly distributed (across an economy, continent, or the world).
Note that route changes can cause a VP to reach different sites at different times. The DNS Name Server Identifier (NSID) option helps the measurement platform to track which sites each VP reaches.
For the deployment of the initial implementation of the root monitoring software, we found that the low number of VPs relative to the number of sites decreased the confidence in the measurement results. Because of the low coverage, usually only one VP measured the timeout of a given site at a given time. It was, therefore, often unclear whether the timeout was actually caused by the root server site, the network, or the VP itself.
In addition, we found strong signs that some VPs were at locations with poor connectivity. For example, they often failed to reach all root servers at the same time, which is a strong indication that the VP or the network of the VP caused the timeouts and not the root servers.
Challenge #2: Defining the metrics
The second major challenge involves the definition of the metrics.
This became apparent when we looked closer at the publication delay reported for one of the root servers. We found that, while the measurement system did pick up on the missing zone files, the reports did not mention the problem. The reason for this is the way the measurements are aggregated.
According to RSSAC047, the monthly publication delay of a root server is calculated by taking the median across all measured delays. Zone files that are never published are not taken into account. The metric is simple, but it has the disadvantage that it only signals problems with zone publication when the delay was high for at least half of the month.
As in the example of RSSAC047, metrics often need to strike a balance between simple but vague and complex but detailed. The publication delay metric is calculated in a very simple manner, which also results in the loss of (important) details.
Other challenges
Operators and researchers who would like to monitor highly distributed systems also face other challenges that we did not address in our study. Examples include the cost of the monitoring platform, the availability of VPs at different locations, and the measurement frequency.
Our recommendations for measuring distributed DNS deployments
Based on our analysis of the RSSAC047 measurements, we make three recommendations for improving the monitoring systems of distributed DNS systems like the root.
Recommendation #1: Introduce health checks
We recommend implementing health checks of the VPs themselves.
In the case of RSSAC047, we developed and deployed two extensions to the current implementation in a one-month trial.
First, we continuously monitored the availability of the VPs from an additional monitoring node. While these measurements, too, can be ambiguous (because of network problems between the monitoring node and the VP, for example), they add one additional signal that can help with interpreting the measurements by the VPs.
Second, we implemented traceroute measurements directed to services not related to the root server system. The assumption was that if these measurements were to fail at the same time as the root server measurements, that would be a strong sign that the connectivity problems were not caused by the root servers.
Recommendation #2: Increase confidence
Second, we argue that using more VPs enables a highly distributed system to be monitored more accurately, even though it might increase the noise in the monitoring system.
In order to retrospectively test whether a timeout was caused by the root servers or not, we relied on the measurements by more than 10,000 RIPE Atlas probes that query the root servers every few minutes. If tens or hundreds of probes reported connectivity problems at the same time, then the root server very likely had problems. Figure 1 shows an example where the initial implementation signalled a timeout (vertical blue line), and a large number of RIPE Atlas probes failed to reach the same server (orange line). This was, for us, a strong sign that the measurement from the VP could be trusted and that the root server or the path towards the root server was indeed unavailable.
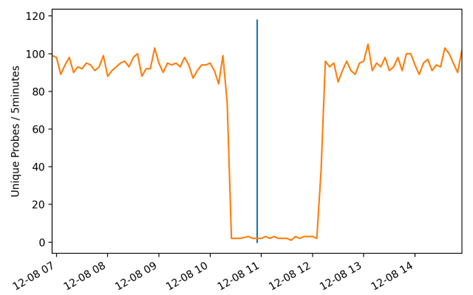
By implementing recommendations #1 and #2, we were able to confirm that the availability of the root server system was very likely higher than reported by the initial implementation.
Recommendation #3: Tune and test the metrics
Our third recommendation is to develop test cases that help operators propose metrics that actually enable reporting on expected outages and to define appropriate alarm thresholds. By developing test cases of outages that should and should not be picked up by the metric, operators can make sure that the metric only triggers reports on relevant events.
In the example of RSSAC047, test cases that simulate different scenarios of delayed zone publication could have helped RSSAC to ascertain whether the metric was actually capable of reflecting relevant outages.
Main takeaway: Finding the right balance is key
How you want to monitor a distributed DNS service depends on many different things: The scale of the service, whether you’re operating the service yourself or not, the reason why you want to monitor in the first place, and who the audience is for the reports created by the monitoring system. That applies not only to the RSSAC047 measurements but also to other platforms that monitor distributed DNS systems.
Where RSSAC047 is concerned, it has already taken two iterations to improve the metrics, and a third will likely follow. We hope that our study will help improve the metrics further. You can find more details of our study on our website. The information on our site also looks more closely at the source code and describes in great detail how we came to the conclusion that the root server performance is very likely better than originally reported.
We would like to thank Verisign, ISC, and ICANN for their support throughout this study. We would also like to thank the root server operators and the members of the RSSAC caucus for their feedback.
If you have any feedback about this blog post or our report, please contact us at moritz.muller@sidn.nl.
Moritz Müller is a Research Engineer at SIDN Labs.
This post was originally published at SIDN Labs.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.