

In this series ‘IXP from Scratch‘ DD-IX is showing us how they built and run DD-IX, an Internet Exchange Point located in Dresden, Germany. DD-IX is driven by a grassroots community passionate about contributing to a resilient and efficient Internet. The series began with some basic background and is now covering technical design decisions.
In this post, we start by explaining the configuration of our switching infrastructure using common IETF protocols to implement redundancy, full usage of resources, and seamless adaptivity in case of failures or maintenance. We then continue presenting the configuration of our route servers with a special focus on isolating different LANs and dynamically excluding invalid routes.
Building bridges
Our switching infrastructure consists of two Arista DCS-7050SX switches donated by third parties (thanks again!). Each switch serves one Point of Presence (PoP). Both switches are connected via two CWDM-based 10G links.
Right from the beginning, we aimed for scalability that allows us to easily expand our IXP to connect additional switches and PoPs without sacrificing fault tolerance and resource sharing. Combining plain Ethernet, link aggregation, and spanning trees may work for small LANs with few switches but becomes a significant challenge in larger deployments due to slow convergence during topology changes and limited flexibility in directing packet forwarding. A key feature of this classic approach, however, is that it is based on open standards and a distributed control plane — features that are also very important to us. Consequently, any <Your vendor building bridges> Software Defined Lock-in solution would not work for us either.
In the following, we describe our setup based on MP-BGP EVPN (Multiprotocol BGP Ethernet VPN) on top of VxLAN (Virtual Extensible LAN), both defined by the IETF.
Set up a fabric
We need various broadcast domains that are implemented on the switching hardware as common VLANs:
- The peering (V)LAN in which peers are connected.
- Quarantine VLAN for the assessment of new peers.
- Management VLAN since we do not have an out-of-band management, yet.
Typically, large broadcast domains do not scale since unknown MAC addresses lead to larger flooding, even in switched environments. Using VXLAN and EVPN we can tunnel Layer 2 traffic via an IP network, enabling coherent Layer 2 domains without spanning a VLAN across all switches. Using a multiprotocol routing protocol allows us to provision MAC addresses via unicast and to balance traffic across multiple ports in parallel.
Our EVPN setup uses an IGP in the underlay and full ‘meshed’ Internal Border Gateway Protocol (iBGP) sessions between the loopback interfaces of our two switches. Instead of the complex Open Shortest Path First (OSPF) monster, we choose IS-IS as the Interior Gateway Protocol (IGP).
Bundle resources: To LAG or not to LAG?
We do not use any Link Aggregations (LAGs) for the underlay ports but deploy Equal-Cost Multi-Path (ECMP) routing. Running a routing session on each individual link instead of aggregating links on Layer 2 brings various advantages:
- Links can be released from traffic by disabling the individual routing session. This allows link maintenance with zero packet loss as the routing protocol will gradually move the traffic instead of abruptly turning off ports.
- Reconfigurations or even replacing the IGP of the underlay is possible without traffic disruption in the overlay.
- Bidirectional Forwarding Detection (BFD) is performed independently on each link.
Detecting errors: To BFD or not to BFD?
To quickly detect link errors in the underlay, we use BFD on all underlay ports. This allows us to reduce IGP convergence times to a minimum without tuning any routing protocol default timers.
We don’t use BFD for MP-BGP EVPN because a router interface connected to a switch port in the Peering LAN is virtually static and cannot move. If one of our PoP switches fails or becomes isolated, quickly removing the MAC addresses of unreachable ports from the EVPN doesn’t improve the situation.
Protecting the peering LAN
The most challenging part of setting up our switches is to protect the Peering LAN to which the routers of our peers are connected — see also APNIC and MANRS.
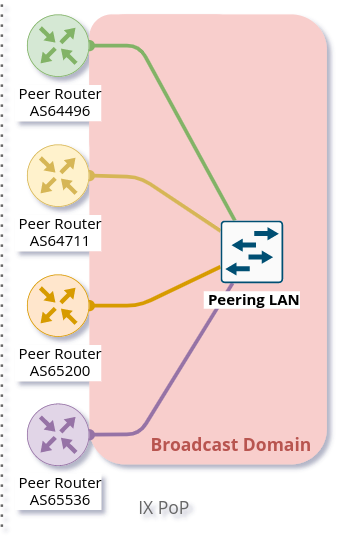
That might seem like a straightforward setup, but in reality, various types of remote stations are connected to this VLAN, each with different levels of trustworthiness, such as:
- Our route servers (very trustworthy).
- Directly connected peer routers (trustworthy).
- Different types of Layer 2 backhauls for remote peer routers (not trustworthy).
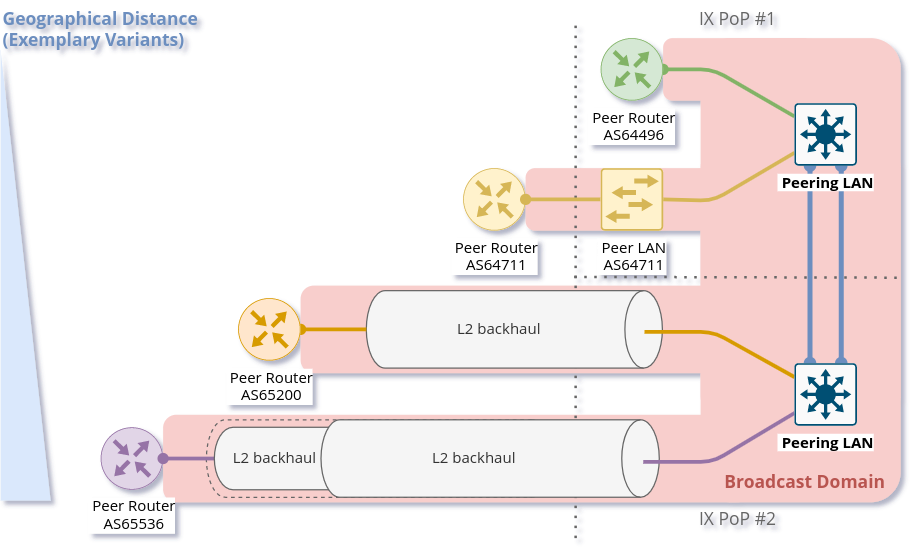
What could possibly go wrong?
- The Peering LAN is just a bridge and all peering ports with Layer 2 backhauls are building a large carrier-spanning (economy-spanning? continent-spanning? …) broadcast domain. No one has the intention to build a loop!
- Any router in the Peering LAN can unintentionally cause disruptions by using incorrect Layer 2 or Layer 3 addresses, performing Proxy ARP, or doing other weird things.
- Even if you trust your peers, there is still a risk that a router could be exploited by an attacker so it doesn’t matter whether you trust your peers or not.
Several incidents in the past (for example, 2014, 2015, 2023) give good reasons for zero trust.
Peering ports basics
To mitigate risks, we harden each switch port leveraging our switching configuration. The ports are configured depending on the physical port status setting in the IXP Manager.
We automatically assign the following configuration to all ports connecting peers having the status ‘Connected’:
interface Ethernet11
description PEER AS65372 peer1
switchport access vlan 600
ip access-group peer-eth11-ipv4 in
ipv6 access-group peer-eth11-ipv6 in
mac access-group peer-eth11 in
no lldp transmit
no lldp receive
sflow enable
storm-control broadcast level 0.01
storm-control multicast level 0.01
storm-control unknown-unicast level 0.01This configuration limits Broadcast, unknown unicast, and multicast (BUM) traffic to prevent packet storms from external networks into our fabric. On each peering port, we use ingress sFlow sampling to build traffic statistics. We also apply the following inbound ACLs at Layer 2 and Layer 3:
mac access-list peer-eth11
10 remark AS65372 allow arp broadcast
11 permit vlan 600 0x000 00:53:42:8b:7b:20 00:00:00:00:00:00 ff:ff:ff:ff:ff:ff 00:00:00:00:00:00 arp
20 remark AS65372 allow nd multicast
21 permit vlan 600 0x000 00:53:42:8b:7b:20 00:00:00:00:00:00 33:33:ff:00:00:00 00:00:00:ff:ff:ff ipv6
30 remark AS65372 drop other broadcasts or multicasts
31 deny vlan 600 0x000 any 01:00:00:00:00:00 fe:ff:ff:ff:ff:ff log
40 remark AS65372 allow lan access
41 permit vlan 600 0x000 00:53:42:8b:7b:20 00:00:00:00:00:00 any arp
42 permit vlan 600 0x000 00:53:42:8b:7b:20 00:00:00:00:00:00 any ip
43 permit vlan 600 0x000 00:53:42:8b:7b:20 00:00:00:00:00:00 any ipv6
100 remark AS65372 drop any
101 deny any any log
! …
mac address-table static 0053.428b.7b20 vlan 600 interface Ethernet11The Layer 2 ACL allows IPv6 Neighbor Discovery multicasts, and IPv4 ARP broadcasts but no other Layer 2 non-unicast traffic. Furthermore, only packets of the EtherType IPv6, IPv4, and ARP are allowed to enter these ports. Sorry OSI, you shall not pass.
We require that all peers use only a single static MAC address on their peering ports, and add a corresponding static MAC address-table entry.
Filtering IPv6 peering addresses is specifically challenging
ipv6 access-list peer-eth11-ipv6
10 remark AS65372 IPv6 multicast (RFC 5963)
11 permit ipv6 any host ff02::1
12 permit ipv6 any host ff02::2
13 permit ipv6 any host ff02::16
14 permit ipv6 any ff02::1:ff00:0/104
15 deny ipv6 any ff00::/8 log
20 remark AS65372 allow router IPv6
21 permit vlan 600 0x000 ipv6 host 2001:db8:79::3c0c:1 any
30 remark AS65372 deny IPv6 abuse
31 deny vlan 600 0x000 ipv6 2001:db8:79::/64 2001:db8:79::/64 log
100 remark allow any other traffic
101 permit ipv6 any any
! …
ip access-list peer-eth11-ipv4
10 remark AS65372 allow router IP
11 permit vlan 600 0x000 ip host 198.51.100.71 any
20 remark AS65372 deny IP abuse
21 deny vlan 600 0x000 ip 198.51.100.64/26 198.51.100.64/26 log
100 remark allow any other traffic
101 permit ip any anyLayer 3 ACLs are used to prevent peers from using IP addresses that aren’t assigned to them. In IPv4, this is straightforward since we allocate peering LAN IP addresses to peers, with the support of IXP Manager. However, in IPv6, it’s less clear due to the use of link-local addresses. Firstly, IXP Manager doesn’t provide the ability to manage (static) link-local addresses. Secondly, autoconfigured link-local addresses require dedicated monitoring to detect them. In the future, we would like to see standardized rules for configuring link-local IPv6 addresses in IXP peering LANs, which would simplify IP filtering.
We have link-local multicast filters following RFC 5963 — ‘IPv6 Deployment in Internet Exchange Points (IXPs)’. This also serves to suppress incorrectly configured router advertisements.
Configurations may include features that are not available
We are aware that the hardware in our switches (Trident2 BCM56850 series) does not support the outer VLAN option in any ACL. Not every setting visible in the active configuration is actually functional — this is a common ‘feature’ with many switch vendors that use generic software images.
This is dangerous because although the configuration on different switch models is syntactically correct, it may (surprisingly) have different semantics! Depending on how the ACL is written, it could either fail open or fail close.
Also, be careful when replacing the switch with a different model in the event of a failure or upgrade — your ACLs might have different semantics.
Be prepared for maintenance
It is necessary to do maintenance on switches from time to time. We use ‘involuntary BGP session teardown’ according to RFC 8327 — ‘BGP session culling’ to disable traffic forwarding on a single switch for maintenance. This is implemented by inserting additional Access Control Entries (ACE) at the top of the peer ACLs during maintenance:
ipv6 access-list peer-eth11-ipv6
5 deny tcp 2001:db8:79::/64 eq bgp 2001:db8:79::/64
6 deny tcp 2001:db8:79::/64 2001:db8:79::/64 eq bgp
! …
! …
ip access-list peer-eth11-ipv4
5 deny tcp 198.51.100.64/26 eq bgp 198.51.100.64/26
6 deny tcp 198.51.100.64/26 198.51.100.64/26 eq bgp
! …This intentionally breaks any BGP session between the peers and our route servers and all direct peerings to other peers in the peering LAN on the switch in maintenance. BGP sessions that do not terminate on the switch under maintenance continue to work, though.
When the maintenance is complete, these ACEs will be removed and the BGP sessions recover. This allows us to do (emergency) maintenance without directly interacting with all affected peers.
Route servers
Our route servers run on dedicated hardware Alpine Linux in diskless mode allowing for robust operation, as discussed in Part [LINK] of this series. We use a single BIRD2 instance as a routing daemon.
Isolate the peering LAN
The route servers are connected to the management LAN and the peering LAN. For security reasons, network packets must never be routed between those networks. Deploying firewall rules is the first step but it’s not sufficient on its own. We also need to tune ARP responses and other settings of the Linux kernel to achieve full isolation.
The Linux kernel provides a lightweight built-in solution to implement partitioning of kernel resources such as user IDs, file systems, processes, or the network stack. So-called network namespaces (netns) enable the creation of partitions with their own isolated IP routing configuration. Processes and interfaces can be moved between netns as required. Our route servers have a bonding link (LAG) where the VLANs of the PoP Management LAN and the Peering LAN are attached (Figure 3).
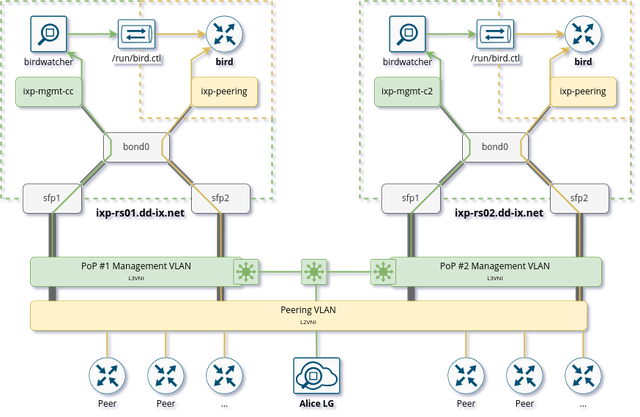
The peering LAN subinterface and the BIRD BGP daemon are assigned to the peering network namespace. While network namespaces in Linux provide hard isolation for any IP-based connection, it does not affect UNIX domain sockets. So we can still use the BIRD CLI birdc from the default network namespace to manage the BIRD daemon running inside the peering netns. This also works for monitoring tools such as birdwatcher and bird_exporter.
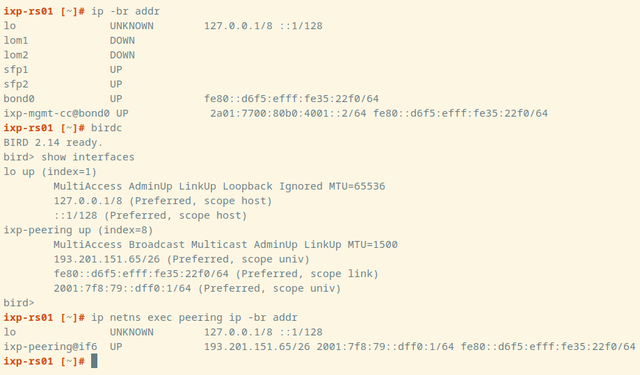
Alpine Linux has built-in support to run daemons inside network namespaces. We use IfState to have a fully declarative network configuration (disclaimer: Thomas is an upstream developer of IfState). IfState also has native netns support allowing us to configure such a setup easily (see our jinja2 template for /etc/ifstate/config.yml).
BGP configuration
The BGP configuration of IXP route servers must prevent the distribution of incorrect routing information between peers. RFC 7947 and RFC 7948 provide a good overview of important requirements. Instead of implementing policies to ignore invalid routes from scratch, we use a well-known and tested framework.
Exclude invalid routes from advertisement
At DD-IX, we build the basic BIRD configuration of our route servers using arouteserver provided by Pier Carlo Chiodi. Our configuration of arouteserver is available in our DD-IX Ansible IXP repository. The BIRD configurations are automatically rebuilt and activated several times a day to reflect changes in route objects, RPKI material, and so on.
Transparency is important
Debugging in case of errors, unexpected behaviour, and so on, requires full transparency into the configuration of our route servers. To make the most recent configurations available to our peers, we use the built-in feature of arouteserver to create a textual representation of the route server options and policies and publish the output automatically on our website.
IPv4 prefixes and an IPv6 next hop?
RFC 8950 defines the option to advertise IPv4 prefixes with an IPv6 Next Hop. This feature is supported by arouteserver. Although this feature doesn’t appear to be provided by many IXPs yet, we decided to try this feature in our greenfield setup. Unfortunately, we had to deactivate it for now because it conflicts with our monitoring setup.
Conclusions
We would like to emphasize the following takeaways:
- Running a larger switching infrastructure that allows for fast failovers and uses available resources flexibly is more than deploying link aggregation and spanning trees. There is no need, however, for proprietary solutions. Open IETF technologies for virtualization work perfectly.
- Securing your peering LAN is a must but it also introduces complexity, especially when it comes to debugging Layer 3 filters. In our next post, we will describe how we generate our configurations and ACLs.
- Deploying RFC 8950 causes issues in some monitoring setups, primarily because the use of two address families in a single BGP session is not always supported.
- A route server should not propagate any route advertised by a peer. Tools exist to compile a list of valid routes, but operator input is also needed to create RPKI Route Origin Authorizations (ROAs) and apply filters!
- IPv6 introduces the special consideration of link-local addresses. Currently, our community does not have a clear understanding of which addressing scheme should be used. This, however, is a requirement for the creation of filter rules. We hope that this will be clarified among IXPs in the future.
Thomas operates data centre and ISP infrastructure as a professional at AS15372. He is a co-founder of DD-IX and an open source enthusiast.
This post was originally published at RIPE Labs.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.