

This work was co-authored by William Pohlchuck, Bhargava Raman Sai Prakash, Rachel Dudukovich, Daniel Raible, Brian Tomko, Scott Burleigh and Tom Herbert.
This post concerns the Delay Tolerant Networking (DTN) Internetworking overlay service that supports communications over paths of consecutive links that may introduce significant delays and/or disruptions. The service is therefore essential for air/land/sea/space mobility use cases, where delay and/or disruption can interfere with traditional interactive communications.
We specifically focus on performance aspects of DTN implementation architectures, including domains of application such as the International Space Station (ISS) where DTN experiments with both traditional radio frequency and high data rate laser links are underway. We finally show that increasing the Licklider Transmission Protocol (LTP) segment size results in better DTN performance even when Internet Protocol (IP) fragmentation is invoked. This result indicates an unfulfilled need for larger packet sizes and better IP fragmentation support in the Internet.
Delay Tolerant Networking
The subject of Delay Tolerant Networking (DTN) has been under active investigation in the Internet Engineering Task Force (IETF) and Consultative Committee for Space Data Systems (CCSDS) even before the earliest concepts of the IETF Delay-Tolerant Networking Architecture were published as RFC 4838 in April 2007.
The work then progressed to the point that the IETF formed a DTN working group, which now produces DTN standards for the Internet. Most notably, the DTN Bundle Protocol (RFC 9171) defines a ‘bundle’ as the atomic unit of transfer for a DTN protocol stack layer below the application layer. DTN bundles are often quite large (for example, 100KB, 1MB or even more) and associated with bulk transfer, in contrast to the much smaller Internet Protocol (IP) ‘packet’ more commonly associated with interactive Internet communications.
The transmission of bundles in the DTN architecture is coordinated by Convergence Layer Adapters (CLAs), with adapters defined for TCP, UDP and a new DTN-compatible CLA termed the Licklider Transmission Protocol (LTP) (RFC 5326). Each CLA is responsible for transmitting bundles to the next DTN ‘hop’, which due to the overlay nature of the architecture may be separated by many underlying IP hops connected by consecutive IP links. In particular, the LTP CLA provides a reliable delivery service that is more compatible with the delay and disruptive nature of DTN communications than traditional reliable transports such as TCP and QUIC.
The bundle protocol invokes the LTP CLA whenever reliable and delay-tolerant transmission of bundles is necessary. LTP then breaks each bundle up into smaller pieces known as ‘blocks’ and breaks each block up into still smaller units known as ‘segments’ (as we will explain later, it is this segment size that has the most profound effect on performance). LTP then includes each segment in an IP packet for transmission over a consecutive series of IP links for which there is an associated path Maximum Transmission Unit (path MTU).
If the IP packet size exceeds the path MTU, a process known as IP fragmentation breaks each packet into still smaller units of transfer known as ‘fragments’, which the DTN peer as the final hop in the IP link path must then reassemble. The DTN peer then submits each resulting segment to its own LTP CLA, which reconstructs first the LTP blocks and finally the original bundle. The DTN peer then either delivers the bundle to a local application or forwards it to the next DTN peer on the path to the final DTN destination.
This (sub)-layering arrangement allows more discrete processing and improved performance when the segment size can be increased — indeed, increasing the segment size provides an almost magical performance gain since nothing else has changed in the underlying network. Very simply, using larger segment sizes reduces the LTP workload and allows for greater end-to-end performance.
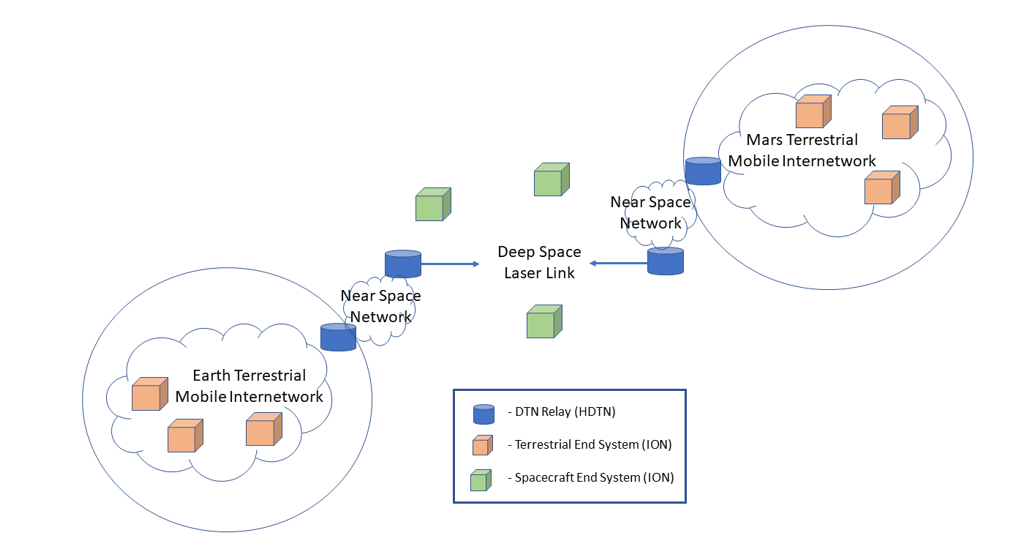
For space-based communications, interplanetary links (for example, between Earth and Mars Relays) will be expected to carry a very high traffic data rate since the number of available paths is so limited. This is true even though the one-way light time delay between Relays may be on the order of many minutes or even longer. A notional interplanetary DTN architecture is shown in Figure 1. We, therefore, consider DTN architectures that have been designed to transfer bundles via the LTP CLA at the highest possible data rate, and we consider the differences between the intermediate system (for example, Relay) and end system (for example, spacecraft or ground station) performance requirements. Two such architectures are discussed in detail in the following sections.
HDTN — A high-rate DTN implementation for peak performance
The High-rate Delay Tolerant Networking (HDTN) architecture was designed to allow for asynchronous processing of bundles throughout the stages of its bundle pipeline. Early prototypes of HDTN focused on the separation of control and data plane messages and the development of a message bus architecture between its main modules.
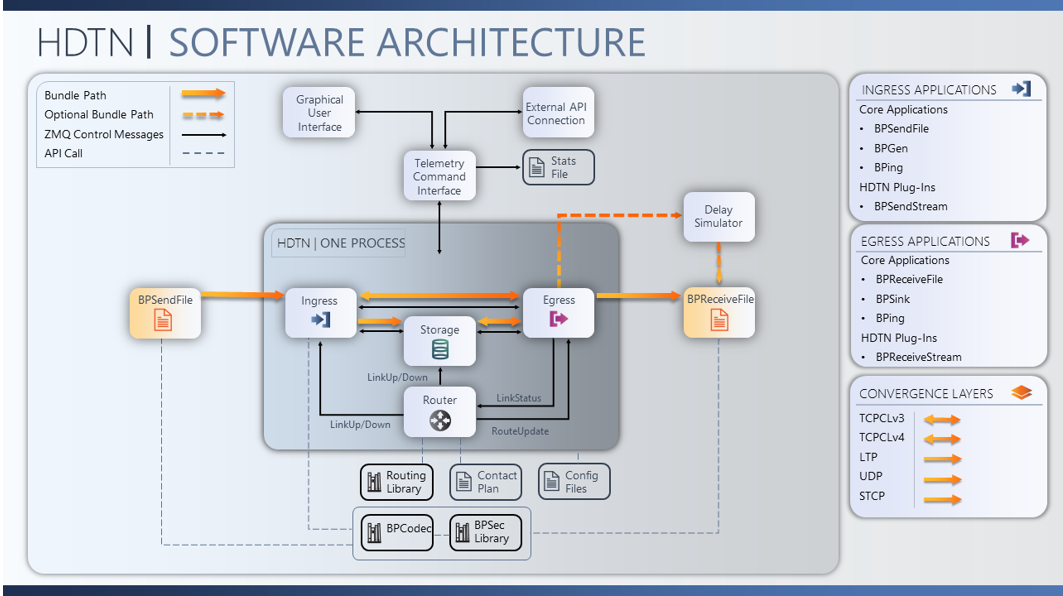
The main HDTN modules are ingress, storage, router, egress, and telemetry and command interface. Ingress ingests incoming bundles and interprets bundle header information. Storage manages stored data, bundle expiration, bundle fragmentation, and custody of bundles. The router reads contact plan information to determine when bundles should be stored and released to appropriate outducts. Egress manages outgoing data queues. The telemetry and command interface provides a generalized API for sharing data with the HDTN web interface, external modules, statistics, and administrative logging. HDTN uses the ZeroMQ library as its internal messaging framework. ZeroMQ allows the HDTN modules to run as separate processes using a TCP-based message bus or as threads within a single process using ZeroMQ inter-process communication for messaging. Figure 2 shows the notional HDTN software architecture.
The HDTN storage module has been specifically developed for high-speed Input/Output. Its early development was based on a Redundant Array of Independent Disks (RAID) striping concept and allows bundle storage to be distributed among multiple disks. HDTN storage was optimized for organizing bundles by priority and expiry for any given final destination endpoint ID.
Bundles are stored on solid-state drives in one or more user-specified binary files on the filesystem; hence if multiple disks are to be used for storage, the user can specify paths on different mount points on the system for HDTN to stripe across (for example, /mnt/sda1/store.bin, /mnt/sdb1/store.bin, and so forth). Bundles are always written in chained 4KByte segments (not necessarily contiguous) regardless of the number of disks, although this value can be changed at compile time. Allocating or freeing any given segment is done using CPU bit-scanning (or leading/trailing zero counting) instructions in constant time (approximately big O(5)). Reads to and writes from one or more disk(s) are non-blocking asynchronous operations utilizing a single thread.
The HDTN LTP implementation was developed to support a minimum of 1Gbps downlink rates with significant round-trip times (four seconds for optical communication from the ISS, and up to 10 seconds for Lunar scenarios). HDTN’s LTP implementation is natively cross-platform (utilizing the Boost C++ libraries) without the need for any emulation, running on Linux, Windows (Visual Studio), and macOS.
The HDTN LTP implementation uses an asynchronous design with callback functions, such that its timers, socket I/O, and packet processing all run in a single thread. However, a dedicated UDP packet receiver thread stores received packets to a circular buffer and feeds them into one or more running LTP engines to mitigate dropping UDP packets. The LTP implementation’s internal data structures use custom allocators that recycle allocated memory, avoiding the need for system calls to allocate and free memory. The LTP implementation takes ownership of memory using C++11 move operations, avoiding the need for copying memory. There is also an option to send multiple UDP packets asynchronously in a single system call natively on any operating system.
The LTP implementation will use any CPU instructions/extensions found during compile time to aid in SDNV encoding/decoding operations, such as the AVX256 x86 extension. For optimal performance, the LTP config parameters should be carefully tuned based on the link characteristics. HDTN’s LTP implementation is its own library within the main codebase and can be easily separated out for custom user applications.
The LTP implementation was carefully abstracted into virtual classes such that it doesn’t need to run over UDP. For instance, the HDTN LTP implementation can be currently configured to run natively over a local socket (type AF_UNIX on POSIX/Apple) or full-duplex pipe (Windows), framed by CCSDS LTP Encapsulation packets to a custom user application. The LTP implementation also contains an experimental feature for extremely long light times by storing session data on a solid-state filesystem rather than in RAM.
ION — a DTN implementation for end-system efficiency
The original intent of the Interplanetary Overlay Network (ION) design, back in 2005, was to provide an implementation of DTN that could be flown on the deep-space spacecraft of that time, a processing environment that couldn’t support the existing DTN reference implementation, DTN2. That environment was characterized by:
- No dynamic system memory allocation is permitted after the initial flight computer boot. To accommodate this constraint, ION has systems for ongoing private dynamic management of large statically allocated tranches of memory.
- No desktop operating system — the spacecraft flew the VxWorks RTOS. To accommodate this constraint, ION is built on an operating system abstraction named ‘ici’: VxWorks is expensive and difficult to develop on, so the software needed to run on Linux during development and then — without modification — on VxWorks in flight.
- No per-process memory protection, because VxWorks at that time didn’t have any. To accommodate this constraint, ION was designed to work in a shared-memory environment. This in turn is why ION relies on a robust transaction mechanism for mutual exclusion: critical sections must always be defended against race conditions and lockouts.
- No guarantee of processing opportunity at any time, because VxWorks is a real-time operating system; interrupt-driven tasks always have priority. To accommodate this constraint, no element of ION is time-critical — everything runs in the background, in the ‘idle’ cycles between interrupts.
- No ability to reboot the processor, ever. To accommodate this constraint, ION is highly modular, built entirely on daemons and libraries — we need to be able to start, stop, and even replace any module at any time without rebooting the flight computer and ideally without interrupting the operation of DTN.
- Sharply limited resources — memory, non-volatile storage, processing cycles. To accommodate this constraint, ION is written in C using Unix SVr4 system calls. Moreover, zero-copy objects are central to the design, and ION inter-process communication is all based on shared memory — shared memory is inconvenient but very fast, so in ION that constraint is turned into an advantage.
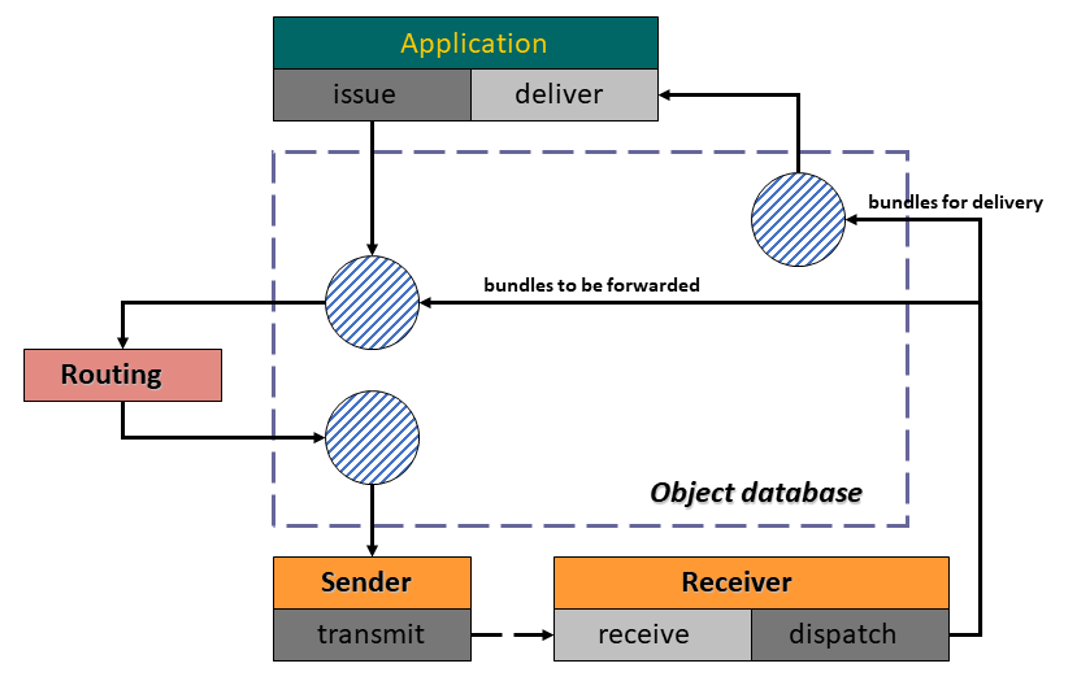
Finally, because developing flight software that works within these constraints has historically been expensive, ION was also designed to be as portable as possible as depicted in Figure 3. The intent was to enable ION to run on just about any platform with only minimal ici tweaks, so that: (a) other NASA centres and other government agencies could avoid the cost of re-developing DTN; and (b) widespread adoption and use would result in widespread exercise, causing bugs to be identified and repaired quickly and enabling the software to be made highly reliable and robust.
DTN on the International Space Station
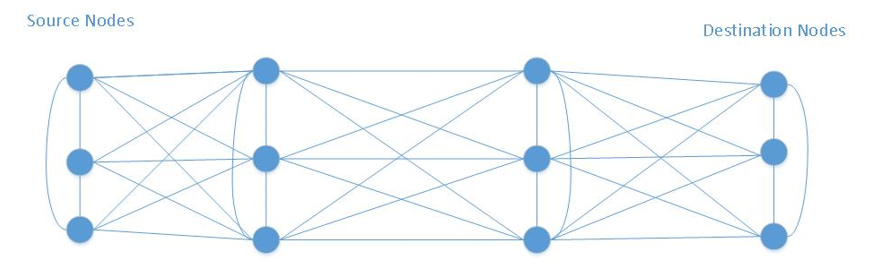
The International Space Station (ISS) is a unique environment and presents an opportunity where the IP systems, traditional Consultative Committee for Space Data Systems (CCSDS), and DTN coexist and support payloads. DTN can be represented as a mesh network, as shown in Figure 4, utilizing CCSDS Bundle Protocol (BP) and LTP across ground and space links to the ISS. Most nodes should have alternate paths around failed adjacent nodes. Intermittent connections can be found between payload users and the Huntsville Operations Support Center (HOSC) and between the HOSC and ISS.
Data flows are bidirectional. Due to connection restrictions, uplink and downlink are constrained and highly asymmetric. Payloads and payload developers do not have the capacity or knowledge to support multiple paths and the HOSC to ISS link is a singleton over the TDRSS Ku-band. Therefore, the ISS DTN system is as shown in Figure 5.
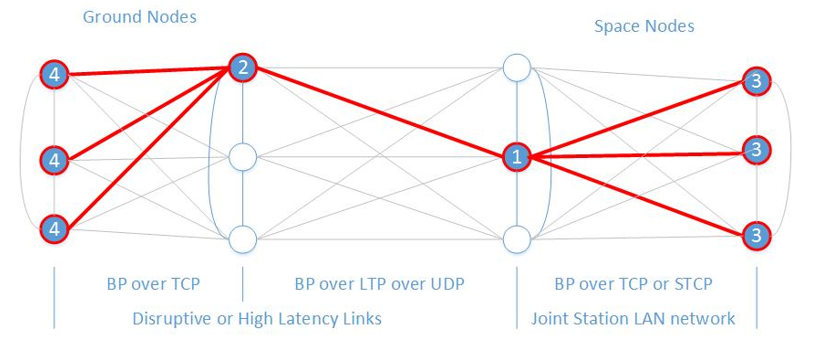
ISS DTN was developed with specific Convergent Layer Adapters (CLA) for each link with BP running over Transmission Control Protocol (TCP), LTP, User Datagram Protocol (UDP), and Simple TCP (STCP). The goal was to be as compliant with the CCSDS specification as possible and use the most common and applicable service.
Ground nodes communicate with each other over a reliable service: TCP. Payload control centres (whether they are a ‘guy in a garage’ or a Telescience Centre) communicate with the HOSC via bundle protocol over a TCP session. This is true whether they have contact with their payload or not. Uplink uses encapsulation of UDP data within the Advanced Orbital Standard (AOS) protocol. Embedded in the encapsulation is LTP. It provides a TCP-like connectivity over the space link. Some additional services and capabilities from the CCSDS specification support payloads, specifically:
- Compressed Bundle Header Extension (CBHE) supports more efficient bandwidth usage.
- CCSDS File Delivery Protocol (CFDP) provides reliable file transfers.
- Persistent data stores allow loss of compute capability on the ground without loss of bundles.
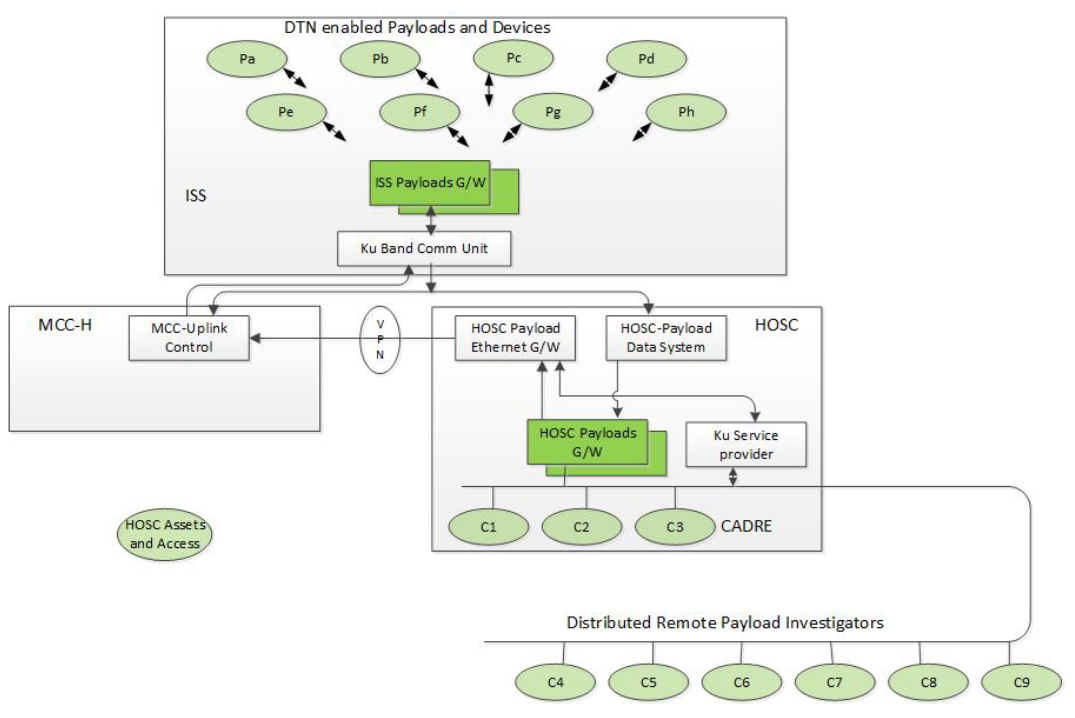
The architecture of Figure 4 supports DTN users locally and remotely interfacing with the HOSC. Payloads may use the capability if they have compliant DTN nodes. As shown in Figure 6, Payload Investigators or HOSC Cadre members can utilize DTN services by requesting Ku-band IP services and connecting to the HOSC Payloads Gateway. Data flows can be initiated from the vehicle to the ground or in reverse.
ION performance — performance implications for DTN end systems
Understanding the nuances of ION’s performance is vital for optimizing data transmission over vast distances where conventional networking protocols fall short. As we push the boundaries of what is possible with DTN, it is imperative to investigate how different factors, such as LTP segment sizes and MTU influence the throughput and reliability of these networks.
By conducting extensive performance testing, we aim to shed light on how adjustments to the LTP segment size can affect the efficiency of both HDTN and ION. Our research advocates a transition towards larger MTUs to better accommodate larger packets, thus paving the way for a more efficient digital communication landscape.
To facilitate this investigation, we employed the Common Open Research Emulator (CORE), in conjunction with ION version 4.1.2, on a robust virtual machine setup featuring eight processors and 23,465 MB of RAM, running on 64-bit Ubuntu 20.04.3.
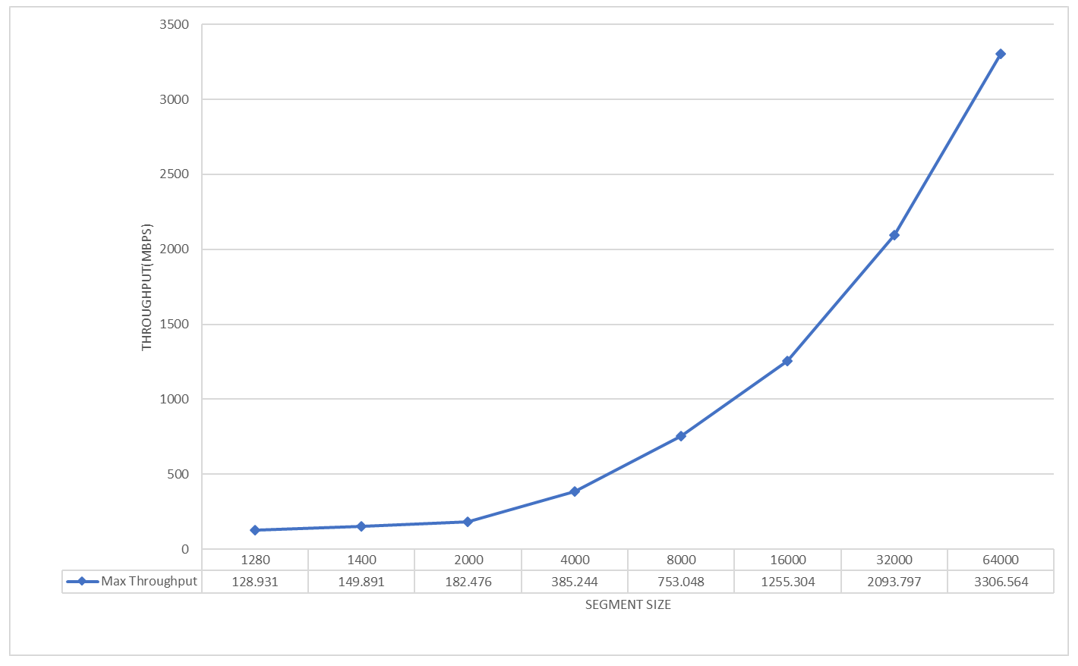
The data from our performance tests, as illustrated in Figure 7, shows a pronounced trend where increases in LTP segment size are associated with higher throughput levels in the ION framework. The tests began with smaller LTP segments yielding modest throughput, however, as we progressively increased the segment size, we observed a significant upswing in throughput. This pattern, clearly illustrated by the steep incline on the graph, suggests that LTP is more adept at managing larger data segments, and these gains are evident even when operating within the standard MTU of 1,500 bytes used during testing. It is also very significant to understand that all LTP segment sizes that exceed the standard MTU engage IP fragmentation by necessity, but our ION LTP studies have shown that higher data rates are achieved even if the network needs to perform fragmentation.
By considering the implementation of larger MTUs across the network, we could leverage the benefits of transmitting larger packets while still maintaining the adaptability provided by IP fragmentation. This would allow end systems to achieve higher network throughput with greater efficiency, potentially improving overall network capacity, as supported by the encouraging trend displayed in the graph.
Our team has further implemented and tested several popular performance enhancement techniques in ION that have been proven effective in certain other environments. In an initial effort, we replaced the (single-segment) sendmsg() / recvmsg() system calls with their (multi-segment) sendmmsg() / recvmmsg() counterparts.
These functions include multiple independent segments no larger than the path MTU in the user process to Linux kernel system call transactions, but they had little/no influence on ION LTP performance. We next implemented the Generic Segment Offload / Generic Receive Offload (GSO/GRO) functions in ION, which are used to transfer multi-segment buffers between user and kernel space, but these functions again showed only minimal performance gains.
Finally, we implemented a new ‘packet-of-packets’ service known as ‘IP parcels’, where we configured a parcel size of 64KB containing multiple segments no larger than the path MTU. The source then subjected the parcels to IPv6 encapsulation and fragmentation for transmission over the network followed by reassembly at the receiver. The parcel service did show modest performance gains due to more efficient packaging, but the increase was insignificant in comparison to the more dramatic increases seen for using larger transport protocol segment sizes. These results seem to confirm that the system call interface does not present a bottleneck for ION, whereas performance increases for using larger LTP segment sizes were significant even when IP fragmentation was engaged.
The use of larger transport layer protocol segment sizes that engage IP fragmentation has been known to provide greater performance since the early days of Internetworking when the Sun Microsystems Network File System (NFS) in the 1980s showed significant performance gains for setting larger UDP segment sizes for file transfer operations.
NFS servers that could operate with 8KB or larger segments dramatically outperformed those that dropped fragments at high data rates, forcing them to use 4KB or smaller segment sizes as a result. These fragment loss profiles do not seem to have carried over into the modern era where hardware and operating systems have been optimized to accommodate IP fragmentation at extreme data rates. In the modern era, large segment performance benefits can be seen using the ‘iperf3’ performance testing tool for both TCP and UDP, where increasing the segment size dramatically increases performance even when IP fragmentation is engaged.
HDTN performance — performance implications for DTN intermediate systems
The NASA Glenn Research Center High-rate DTN (HDTN) implementation was designed from a clean slate to enable peak data rate DTN LTP performance as a guiding principle for the architecture. We therefore conducted a performance study under HDTN using a local hardware testbed of powerful machines and 100Gbps Network Interface Cards (NICs).
Our testbed consisted of two Dell Precision 3660 workstations with the Ubuntu 20.04 LTS operating system. The workstations had 12th Generation Intel Core I7-12700Kx20 processors with 32GB memory, and the network line cards were Intel E810 CQDA2 100Gbps Ethernet NICs. We connected the workstations with a point-to-point Cat 6 Ethernet cable with connectors compatible with the NIC ports.
We then ran the HDTN ‘LTP 2Node Tests’ using the scripts ‘runscript_sender_ltp.sh’ on the source node and ‘runscript_receiver_ltp.sh’ on the destination node for the test. We began our HDTN tests using ‘conventional’ LTP segment sizes smaller than the path MTU (1,500 octets) and found performance values that approached but did not quite reach 10 Gbps. Setting progressively smaller segment sizes (1,400, 1,360, 1,280, 1,024, 576, and so on) resulted in correspondingly lower performance rates.
We then turned our attention to larger LTP segment sizes in HDTN and found similarly dramatic performance gains that paralleled our findings in ION, also confirming findings for NFS/UDP, iperf3 and others. With the 100Gbps NIC MTUs set to 1,500 bytes, we used progressively larger segment sizes that resulted in IP fragmentation at the source node and IP reassembly at the destination node.
We noted that performance increased sharply for segment sizes up to ~8 KB and then continued to increase gradually to a maximum segment size of ~64 KB. These performance increases prove that the invocation of IP fragmentation using larger segment sizes that produce moderate numbers of fragments produces the greatest performance gain, while progressively greater incremental performance improvements result from still larger segment sizes. With the NIC MTUs set to 1,500 bytes, the peak performance seen for larger segments was a factor of 2 greater than when segments smaller than the MTU were used as shown in Figure 8.
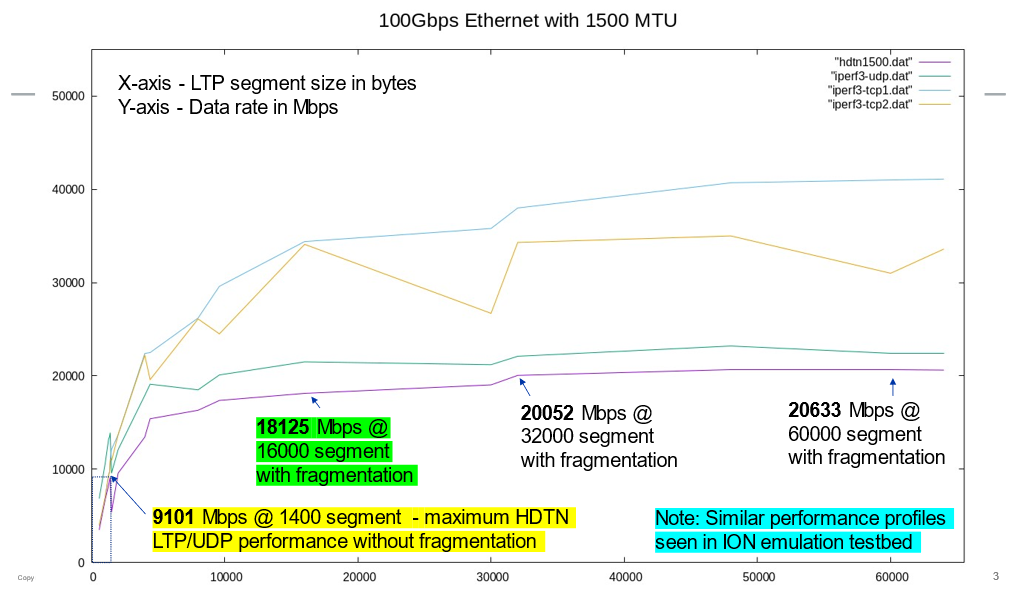
We then set the NIC MTUs to 4,500 and reran the tests. In this new configuration, a segment size of 4,400 bytes produced a factor-of-2 performance gain over conventional segment sizes even though fragmentation was not yet engaged at that size. Setting a segment size up to ~8KB (with fragmentation engaged) increased performance by a factor of 2.5 over conventional sizes, while setting the largest possible segment size of ~64KB increased performance by a factor of 2.7 as shown in Figure 9.
These observations prove that, while invoking IP fragmentation sustains significant performance gains for larger segment sizes, even greater performance is possible when larger segments can be sent as whole packets over paths with sufficient MTU. This finding was further proven when we set the NIC MTUs to 9,702 octets, where a 9,600 LTP segment size brought nearly a factor of 3 performance gains and larger segment sizes that invoked IP fragmentation brought incrementally greater gains as shown in Figure 10.
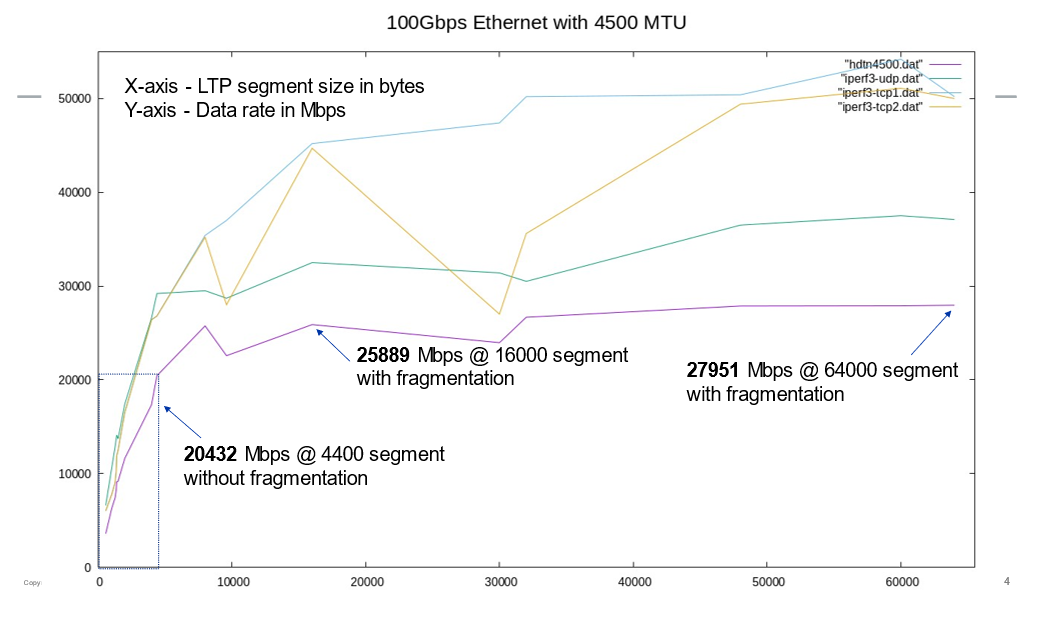
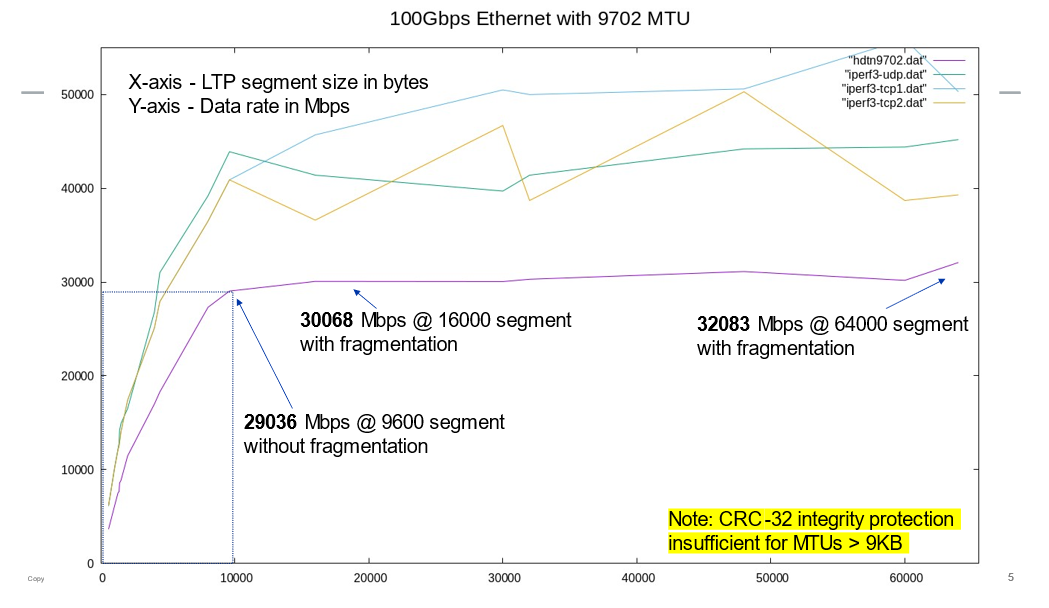
Our tests under both ION and HDTN have shown that both a robust fragmentation/reassembly service and the ability to transit larger whole packets without fragmentation contribute to greater performance when progressively larger LTP segment sizes are used. These tests are further supported by our iperf3 (TCP, UDP) findings, where TCP performance increases even more dramatically when the TCP segment size is increased. We were unable to reproduce the performance profile results for QUIC since the ‘qperf’ performance testing tool uses a fixed segment size of 1,280 bytes regardless of the underlying path MTU. A QUIC performance testing tool that adaptively engages larger segment sizes would provide another useful data point.
Some concerns have been raised about performance degradation due to IP fragment loss, but loss due to congestion is rare in modern Internetworking while mitigations such as IP fragment retransmission and segment size adaptation can be applied to compensate for congestive loss.
We also expect to see an increase in Internet link MTUs, where larger path MTUs will begin to emerge. This can begin with the ~9KB ‘jumbo’ frame sizes supported by many Ethernet NICs that support 1Gbps or higher data rates but should continue to enable support for still larger frame sizes. As such large-MTU paths become more and more common, a new approach to larger packets known as IP Parcels and Advanced Jumbos (AJs) can provide the network- and higher-layer services necessary to support the larger MTUs, with the current day Gigabit Ethernet ~9KB ‘jumbo’ as just the still-too-small ‘tip of the iceberg’ of possible sizes.
Delay-tolerant Networking with Firewall and Service Tickets (FAST)
DTN is designed for the Interplanetary Internet, a communication system envisioned to provide Internet-like service across interplanetary distances in support of deep space exploration. Because of the distances involved, conventional Internet approaches are either unworkable or impractical.
One technique that doesn’t work so well with DTN is Quality of Service (QoS). The communications path with DTN consists of terrestrial, near-Earth, and deep space segments. These segments create a very heterogeneous path, and their service characteristics can be wildly different so the current one-size-fits-all approach of Internet protocols for network QoS doesn’t work. In particular, a few Type of Service (ToS) bits in the IP header aren’t expressive enough to productively leverage QoS in end-to-end communications with DTN.
Enter Firewall and Service Tickets (FAST). FAST is a solution that facilitates coordination among the various players in communications for QoS and network services. The basic idea is that applications signal the network for the services they want applied to packets. This signal is encoded in the form of a ‘ticket’ that indicates the network services that the network applies to packets.
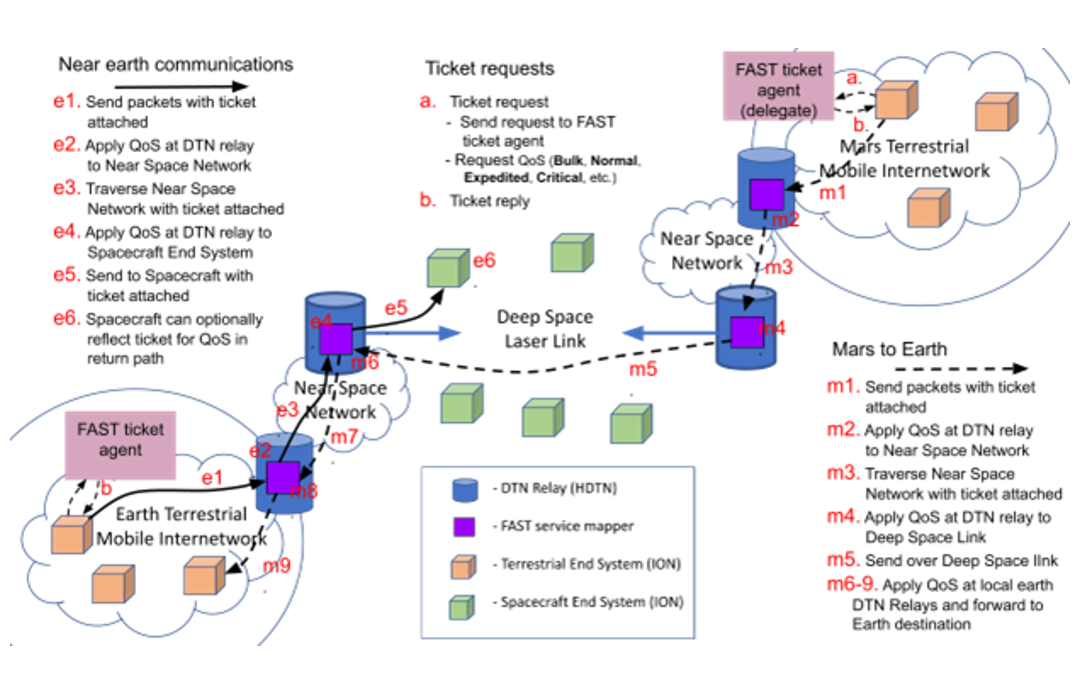
Applications request tickets from a ticket agent in the network for the desired services, issued tickets are attached to packets, and tickets are processed by network elements to provide services for each packet. FAST is quite flexible and expressive, so it facilitates requests for QoS that can be targeted to various segments in DTN. An example of DTN with FAST is shown in Figure 11. This diagram depicts the use of FAST in an internetwork composed of a terrestrial Earth network, near-Earth spacecraft, and a Mars terrestrial network. At each segment, FAST tickets are interpreted to provide the best service for traversing that segment.
Conclusion
In conclusion, our work on implementations and architectures for DTN LTP high performance has identified several key points. First, an architectural approach tailored to specific use cases ensures the best fit for both end-system and intermediate-system deployments. For end systems, raw performance must be balanced with respect to resource constraints and operational limitations (for example, for size, weight and power-constrained deep space vehicles and terrestrial tactical assets). For intermediate systems such as space relays, the absence of alternate paths requires peak performance across any available paths based on architectures that are fundamentally designed to support sustained high data rates.
In both cases, our studies have shown that DTN LTP performance is maximized by using the largest possible LTP segment sizes even if doing so invokes fragmentation at lower layers.
Our performance results suggest that even larger LTP segment sizes could support still higher data rates using jumbo payloads that exceed current-day link MTU limitations. This suggests a need for research into link technologies that exceed the industry standard 9KB MTU limitation, possibly even extending to sizes that exceed 64 KB. Our work on IP Parcels and Advanced Jumbos (AJs) will explore this alternative further in future articles.
Finally, a means for signalling resource reservations with FAST can properly balance performance in heterogeneous Internetworks that carry both delay tolerant and traditional interactive communications.
Fred Templin, William Pohlchuck and Bhargava Raman Sai Prakash are technical staff members of The Boeing Company where their collaboration on AERO/OMNI/DTN performance has produced significant advancements. Rachel Dudukovich, Daniel Raible and Brian Tomko are researchers at the NASA Glenn Research Center, where they engineer the HDTN implementation for peak performance and publish their research in IEEE forums. Scott Burleigh is a retired engineer from the NASA Jet Propulsion Laboratory who continues his work in support of the ION DTN implementation and as a core contributor to the IETF and CCSDS DTN standards communities. Tom Herbert is the Founder and CEO of SiPanda, a long-time contributor to Linux Networking with over three hundred kernel patches, and a well-known contributor to the IETF.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.