

RPKI data can be transported in two ways — an HTTPS-based distribution protocol called RRDP, and via RSYNC. Each transportation mode has unique advantages and downsides, with RSYNC serving as the backup for RRDP. In this article, I’ll explain an idea and provide pointers to running code, on how to optimize the RRDP-RSYNC failover process. This proposed optimization helps reduce bandwidth and CPU cycles consumed for both the server and the client.
Background
As noted in RFC 8182 Section 4.1, one of RRDP’s design objectives was for the new transportation mode to co-exist alongside ‘good ole’ RSYNC. To facilitate mapping objects between RRDP and RSYNC, in RRDP both a hash and a path name are provided alongside the Base64-encoded object itself; this metadata can be used to create a representation of the set of files on a file system.
RFC 8182 doesn’t provide much detail on how exactly Relying Parties (RPs) can query, combine, and validate RPKI objects fetched from repositories through different means of transportation. So, I’ll try to fill in some of the blanks.
The RSYNC synchronization protocol uses a very efficient ‘trick’ to determine which files need to be transferred from server to client. Instead of opening and reading the entire file, only the file’s metadata is used to determine whether it needs to be sent over the wire.
The file’s last modification timestamp (‘mod-time’) and the filesize are compared, and if either one differs from the local copy, the file is assumed to have changed and therefore needs to be transferred. The trick is useful because making a decision to transfer by just relying on the file’s metadata consumes far fewer IOPS and CPU cycles than reading the entire file and calculating the 128-bit MD4 checksum of the file (rsync’s --checksum command line option).
During normal operations, RPs will prefer RRDP transport, and if and only if there is any kind of issue with the RRDP service (examples of issues: an expired HTTPS TLS certificate, network reachability issue, malformed XML, and so on), the RP will connect to the RSYNC service. RSYNC is useful as a secondary backup synchronization channel to RRDP.
Most RP implementations serialize the RRDP data structures to a file system where each signed object, certificate and CRL is represented as a DER-encoded file. Most RP implementations do not set the newly created file’s mod-time to any particular value; instead, the serialized files end up on the file system with the mod-time ‘now’ (the moment the RRDP data was serialized to disk). As a consequence of the linear progression of time, clients can obtain newly created data only after the data was published, and there always is a small delay (in the order of a few minutes) between the creation of RPKI files and the RP serializing these RPKI files to disk.
Following rsync’s algorithm (relying on the mod-time + filesize to decide to transfer), one can imagine that the RP’s local mod-time (for a file retrieved via RRDP) will never match the mod-time of the exact same file observed through the RSYNC service. This means that following any kind of failure in RRDP, a full synchronization needs to happen via RSYNC, despite many of the files actually being identical to what was previously fetched via RRDP.
A synchronization minimization technique for RP implementations
The following technique builds upon the concept of the RP having a validated locally stored cache which is robust in the face of issues with transportation issues. Assuming the RP previously successfully synchronized via RRDP and now needs to switch to RSYNC, the RP can use the previously fetched data as a starting point to start the RSYNC synchronization task.
Both GPL Rsync and OpenBSD’s openrsync support a special feature through the --compare-dest=<DIR> command line option. This option instructs the rsync utility to use <DIR> as an additional hierarchy to compare against before doing transfers. If a file in <DIR> is found to be identical to the file on the sender’s side, the file will not be transferred.
This is very useful for creating a sparse hierarchy — transferring only files that truly have changed. As an added benefit, the use of --compare-dest=<DIR> ensures the ‘known good’ local copy (the validated cache) is not overwritten should the RSYNC server somehow end up sending trash. This is because the difference between the locally validated cache and what the remote server offers ends up in a ‘staging’ directory for further examination and validation. For example, using --compare-dest=<DIR> allows the RP to find newer manifests while minimizing file transfer and local storage usage.
As mentioned before, a mismatch in mod-time and/or file size will result in a transfer of the file. If the RP can store the file (fetched via RRDP) with a mod-time that likely is the same mod-time as exposed via the RSYNC service, chances are the file doesn’t need to be transferred!
How to set ‘good’ mod-times before connecting to the RSYNC service
While the RRDP XML documents themselves do not contain any file metadata information, only a hash, a path name, and the Base64-encoded file data itself are exposed in RRDP; each and every RPKI Signed Object, Certificate, and CRL does have useful timestamps embedded in the objects themselves!
I’ve found that the following internal timestamps — already today — in more than 30% of cases happen to coincide with what the RSYNC service lists as the purported mod-time:
- Signed objects (ROA, MFT, ASPA, GBR): The CMS signing-time.
- X.509 certificates: The X.509 notBefore timestamp.
- X.509 CRLs: The CRL thisUpdate timestamp.
At the time of writing, 100% of signed objects in the RPKI ecosystem contain a CMS signing-time field. It turns out this field is incredibly useful to minimize RSYNC synchronization, because many Certificate Authorities (CAs) happen to immediately serialize to a file system after signing, and oftentimes RSYNC servers publish from that same directory structure.
In other words, if an RP uses a file system hierarchy as its locally validated cache and sets the mod-time of RPKI objects retrieved via RRDP to be the CMS signing-time, X.509 notBefore, or CRL thisUpdate timestamp; an RP can easily see a 30% to 40% reduction in the list of files to be transferred when synchronization via RSYNC is needed.
I’ve implemented the above mod-time fixup trick in OpenBSD’s rpki-client, and for fellow RPKI developers, published an Internet draft explaining the approach.
Another side-effect is that through less than 100 lines of code, the debuggability of the locally validated cache is greatly improved — a file’s mod-time suddenly means something significant. Rather than indicating when the RP wrote the file to disk (which is somewhat arbitrary), it now shows when the file was signed. This helps pinpoint what could be files of interest when using ls -al.
I encourage fellow RP implementers (like FORT, Routinator, and rpki-prover) to investigate the use of --compare-dest=<DIR> combined with the ‘fix-up’ of the mod-times of files stored on the file system following RRDP fetches. Application of these techniques will improve operations for both RPs as well as Publication Point (PP) operators.
The synchronization minimization technique for Publication Points
Some PP operators have in the past (or will in the future) sought to simplify their operations by moving to a ‘single source of truth’ for the origin of their PP data. Krill-sync and rsyncit are example implementations of the concept of synthesizing an RSYNC publication based on an RRDP data source, by serializing the RRDP files into a file system hierarchy.
Now, we know that some RP deployments will ‘fix up’ the mod-time of files fetched via RRDP. Logically, on the PP side of the house, a similar fix-up’ will further improve and reduce the list of files to be transferred. Predictable mod-times on both sides of the synchronization channel improve performance.
To help PP operators, I’ve authored a liberally licensed open-source utility named rpkitouch (as in my mind it bears some resemblance to the POSIX ‘touch’ utility). The rpkitouch utility will extract the CMS signing-time, X.509 notBefore, or CRL thisUpdate timestamp from the contents of a file and adjust the mod-time of the file on the file system accordingly.
This utility compiles and runs on both Linux and BSDs linked against either OpenSSL or LibreSSL. The utility is not opinionated on the validity of objects (for example, from a validity time window or cryptographic perspective), it only performs the most minimal sanity checking in order to be able to reliably extract the relevant internal timestamp.
The rpkitouch utility is not needed when ‘RRDP-to-RSYNC’ tools (like krill-sync and rsyncit) implement the proposed mod-time fixup strategy (which I believe recently happened)!
I’ve shared the rpkitouch utility both for real-world use, but also as an example for other implementation efforts. I encourage all developers of RPKI publication software to adopt the idea of setting file mod-times to the CMS signing-time, X.509 notBefore, or CRL thisUpdate. Already today, both APNIC and RIPE NCC’s RPKI repositories successfully follow this approach!
Harmonizing RRDP and RSYNC in a locally stored file system hierarchy
To better understand and compare the current state of various RP implementations, I executed rpki-client 8.6, Fort 1.5.4, and Routinator 0.13.0 twice in so-called ‘one shot’ mode — once with RRDP enabled and once without. This way, a switchover from RRDP to RSYNC was simulated. During these executions, I measured each implementation’s inode consumption over time. All three implementations currently use a file system hierarchy as a ‘database backend’ to store RPKI objects. Measuring inode consumption provides clues about the internal workings of these implementations.
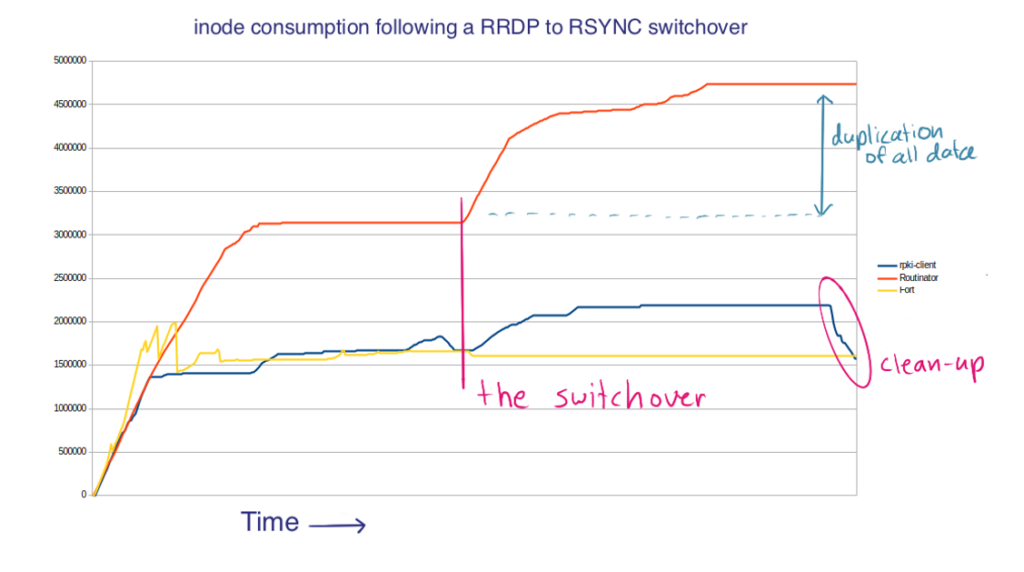
Analysing Figure 1 from left to right
A complete ‘pristine’ (minimal) copy of all cryptographically valid RPKI objects reachable via the five Regional Internet Registry (RIR) Trust Anchors is 306,235 files across 70,452 directories (at the time of writing). On a memory file system formatted as a Fast File System with default settings, this ends up consuming roughly 1,700,000 inodes. What immediately stands out is how Routinator (the orange line) shows close to double the number of inodes compared to rpki-client (blue) and Fort (yellow) after having completed initial synchronization via RRDP. Inspection of Routinator’s repository cache directory suggests the full directory hierarchy appears in duplicate.
Figure 1’s vertical pink line in the middle of the graph marks the moment the validators were launched for a second time, now in RSYNC-only mode.
Again, the Routinator implementation shows a significant jump in inode consumption compared to Fort and rpki-client. Inspection of Routinator’s repository cache directory suggests the full directory hierarchy now appears in triplicate (a total of 216,245 directories) together containing 676,939 files. The total number of files being more than double the theoretical lower limit of 306,235 files, suggests there might be duplication of data to some extent.
Following the transport switchover, the blue rpki-client line shows both an increase and subsequent decrease in inode consumption. This can be explained by this implementation’s use of the –compare-dest=<DIR> feature — only the difference between the remote servers and the locally stored cache is transferred and saved in a temporary staging directory, then in the clean-up phase (after validation), all files are moved into their final destination, or deleted if they are unreachable following the cryptographic chains. As more and more PP operators embrace the mod-time fix-up strategy, I expect this increase/decrease pattern to reduce.
The Fort line (yellow) shows yet another pattern, the number of inodes remains at the same level following the initial RRDP synchronization. Inspection of the system’s process list shows that the RSYNC synchronization happens ‘in place’, rather than first placing the RSYNC-fetched data in a separate staging directory (like Routinator and rpki-client do). I believe there are some downsides associated with this particular ‘in-place’ synchronization strategy. Some time ago I cautioned against the use of rsync’s –-delete feature and suggested an alternative approach to decide which objects to evict from the local cache.
In summary, both Routinator and rpki-client maintain a robust local cache that can survive various publication point failure modes. Routinator achieves this by storing objects in duplicate, rpki-client by leveraging the –compare-dest=<DIR> feature. The former approach is somewhat more costly in terms of inode consumption, storage, IOPS, and network traffic; the latter recycles pre-existing locally stored data, which positively impacts local inode consumption and synchronization burden.
On the other hand, the Routinator approach allows for the resumption of RRDP sessions, while rpki-client requires downloading a full RRDP snapshot when switching back to RRDP. To me there is no obvious right or wrong approach here, I simply observe that different implementation choices resulted in different program behaviour characteristics.
Note that concerns about inode consumption and congestion can be addressed by storing the local RPKI cache on a file system that doesn’t use the concept of inodes, such as ZFS, Btrfs, or XFS.
A possible optimization for the Routinator project might be to pre-populate its RSYNC staging directory with data previously fetched through RRDP, while the Fort project might benefit from introducing the concept of a staging directory in order to use –compare-dest=<DIR>. Following both suggestions, setting the mod-times according to the timestamps internal to the RPKI objects should help optimize RSYNC synchronization.
In conclusion
RP deployments benefit from setting the mod-time of a file fetched via RRDP to a timestamp most likely to align with the mod-time on the remote RSYNC server. In turn, PP operators benefit from setting the mod-time of files presented via their RSYNC service to align with the RPKI object’s internal timestamps — to take advantage of any RPs having implemented the same mod-time strategy. Additionally, RP implementations would do well to investigate taking advantage of rsync’s –compare-dest=<DIR> feature.
My hope is that by sharing the above ideas, eventually, all stakeholders in the RPKI ecosystem will see a reduction of synchronization burden, in case network circumstances warrant switching back and forth between the RRDP to RSYNC transport modes.
Job Snijders (Twitter, Mastodon, homepage) is a Principal Engineer at Fastly where he analyses and architects global networks for future growth, and also an OpenBSD developer.
Adapted from the original post on the SIDROPS mailing list.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.