

When you’ve studied External Border Gateway Protocol (eBGP), you will have been told there are two ways to achieve successful peering to a router that is directly connected:
- Run the session between the IPs on your physical interface, and their physical interface
- Run the session between loopback IPs
The second option involves a trivial bit of extra work, usually in the form of a static route, so that your border router knows how to get to this external IP address on the router at the other end of the link.
You might have also learned that by default, such a peering will not work, because eBGP packets are sent with a time-to-live (TTL) of 1. To fix this, you have to configure something called ‘multihop’, which sets the TTL to be something larger than 1.
Unfortunately, this fact leads many new students to make some incorrect conclusions about the way that the TTL value is processed.
Upon learning about eBGP and multihop, many new students assume that a directly connected router will decrement the TTL before accepting a packet on a loopback interface. In fact though, this is not the case. The TTL can definitely be 1, and it will work absolutely fine.
In today’s post, we’re going to unpick the confusion and take a close look at how the TTL really works — and how it can actually be used to increase the security in your network, using something called the Generalized TTL Security Mechanism.
First, let’s get ourselves clear on when the TTL is actually decremented.
When is the TTL decremented?
The time-to-live field is a number in the IPv4 header that goes down by one every time a packet passes through some kind of ‘Layer 3 device’ — in other words, a device that connects two or more subnets together and can forward packets between them. Whether it’s a router, a firewall or a ‘Layer 3 switch’, the point is that the TTL is decremented by 1 when:
- A packet enters a device.
- A Layer 3 lookup happens.
- The packet is forwarded to a new subnet.
- The packet either exits the physical device or is forwarded to a different virtual instance (for example, a Virtual Routing and Forwarding (VRF), a virtual router, and so on) within the device.
The equivalent field in the IPv6 header is the ‘hop count’ field — a much more meaningful name, in my opinion.
You probably know already that the purpose of this TTL/hop count field is to prevent catastrophic problems when a routing loop occurs. Thanks to the TTL, packets will eventually be dropped when this value reaches zero. Even if a packet loops a few dozen times around a network, it will eventually be discarded.
Here’s a crucial point to understand — if a packet arrives at its destination, the TTL is not decremented one final time. In other words, suppose you remotely log on to a router, using a protocol such as Secure Shell (SSH). Let’s say the SSH packet arrives at the router with a TTL of 60. In this case, the router simply processes the SSH information. It does not set the TTL value to 59, and then process the payload.
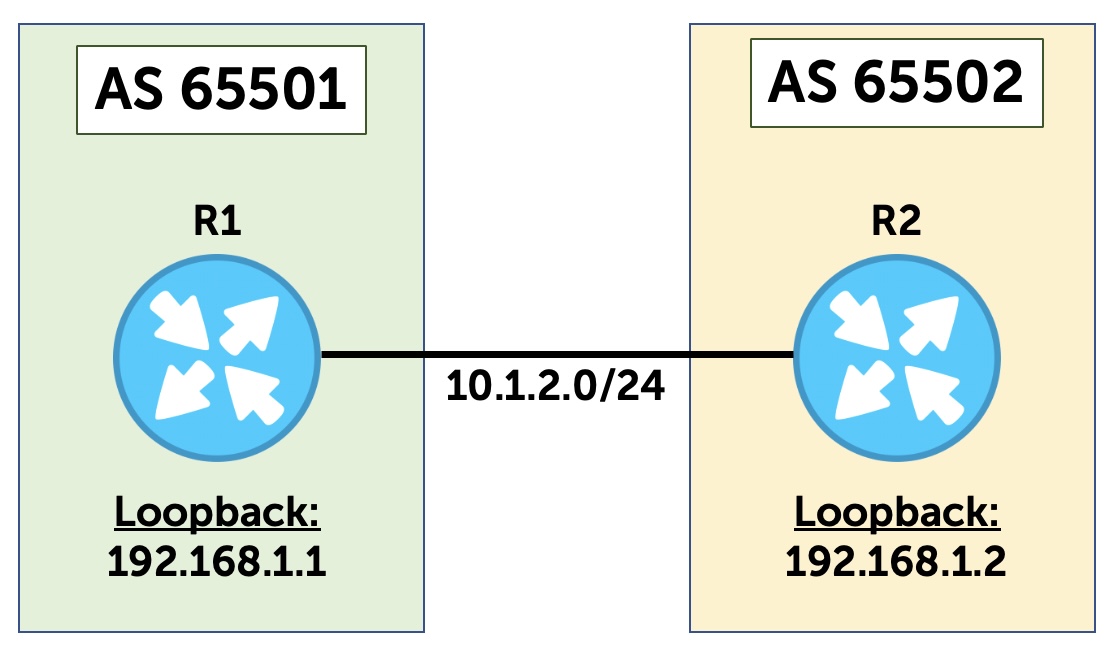
This is true even if you SSH to a different IP than the one on the incoming interface, such as the loopback IP address of the device. In fact, let’s test this. The diagram below shows the topology we’re going to use for most of this post. It shows two routers, each at the border of an Autonomous System (AS). R1’s interface on this shared link is 10.1.2.1, and R2’s interface is 10.1.2.2.
Let’s go onto R1, and ping R2’s loopback with a TTL of 1:
root@R1> ping 192.168.1.2 ttl 1
PING 192.168.1.2 (192.168.1.2): 56 data bytes
64 bytes from 192.168.1.2: icmp_seq=0 ttl=64 time=3.823 ms
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=2.633 ms
^C
--- 192.168.1.2 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max/stddev = 2.633/3.228/3.823/0.595 msVoila — we have success! If the ping were decremented by one as soon as the packet arrived on the incoming interface, this ping would have failed — and we would have received a ‘TTL exceeded’ warning.
By contrast, if this ping had been to something beyond R2, then it definitely would have failed. In this case, R2 would be a transit box for this ping packet. R2 would receive the packet with a TTL of 1, set it to 0, and then drop the packet.
Now we’re clear on that, let’s take a look at how eBGP sessions set their TTL value by default.
Internal BGP (iBGP) and eBGP
A router that talks iBGP (that is, BGP to other routers in the same AS) needs either a full mesh of peerings to every other router in the AS, or (more likely) a peering to one or more route reflectors.
Either way, it is important to know that two iBGP speakers do not need to be directly connected to each other. Indeed, there’s a good chance that the two iBGP speakers will actually be many hops away from each other. As such, the TTL is set high enough that two routers can form an iBGP peering with each other, no matter how far away they are from each other inside the AS (within reason).
By contrast, you may have learned that eBGP connections have a TTL of 1 by default. In other words, by default, two routers need to be directly connected to establish an eBGP peering.
Why is this the case in eBGP? Well, a TTL of 1 makes it more difficult for a hacker to establish a false connection to you if that hacker is multiple hops away. Even if they are able to work out exactly how many hops away you are, and craft a packet accordingly, your reply will still have a TTL of 1, and therefore will fail at the first hop in the reverse direction.
Now, a more interesting question — who decided that this should be the case?
Here’s a fun fact — if there’s a source on the Internet that explains when it was decided that eBGP should use a TTL of 1, I can’t find it. I can’t even find it in any RFC. I looked in the RFC for BGP v4 (RFC 4271) and went all the way back to BGP v1 (RFC 1163). None of these documents contains the text ‘TTL or ‘time to live’ or ‘time-to-live’. It’s not even in the RFC for Exterior Gateway Protocol (EGP) (RFC 904), back in 1984.
My best guess is that this is how it worked in Cisco IOS, and so everyone else also did it. However, it’s perfectly possible that other vendors were doing it before Cisco. Without a primary source, I can’t say for sure. If there are any longer-serving engineers reading this who have a primary source that defines this as an actual standard, I’d love to know.
So, this appears to not be an ‘official’ part of the way that eBGP should work. Everyone just seems to do it like this! Presumably, this means that another vendor could do it differently if they wanted to, and they wouldn’t be breaking any rules? This seems absurd to me, and I surely must be wrong — but like I say, I can’t find this in any RFC. Please do let me know if you find something I’ve missed.
The default behaviour of eBGP
In addition to the TTL of 1, there is something else interesting about a default eBGP session.
On every vendor I’ve used so far, the default behaviour is that eBGP sessions must be created using the IPs that are inside a subnet on a physical interface. This is a mandatory requirement. In our example topology (Figure 1), this means that R1 can create an eBGP session to 10.1.2.2 (the other end of the R1-R2 link), but not to 192.168.1.2.
Indeed, if you try configuring an eBGP session to a neighbor that isn’t on a directly connected subnet, your router won’t even attempt to establish a BGP peering in the first place. You can configure it, but the routers will not send BGP Open messages to each other.
Why is this?
Well, in the example, R1 has no way of telling that 192.168.1.2 is actually configured on R2. If R1 is definitely going to set the TTL to 1 in its BGP packets, then R1 needs to know that the neighbor is directly connected.
A reasonable response to this might be — wait, why does R1 need to know that? Why can’t R1 just try sending a packet with a TTL of 1 anyway? If the neighbor is directly connected, it will respond. If it isn’t, the packet will be dropped, so who cares? My guess is that this is ‘something to do with security’. Again, without a primary source or a standards doc, I can’t say for sure. In any case, it seems that many vendors run with the following logic:
‘If an eBGP session is configured to an IP that is not known on a directly-connected subnet, then do not attempt to make the connection — and refuse any connection attempts from the remote router’.
Let’s test this in Junos.
Testing TTL and eBGP
In Figure 1, you can see two routers that are directly connected together. The connection between R1 and R2 has the subnet 10.1.2.0/24.
- R1 has the .1 IP.
- R2 has the .2 IP.
Suppose that R1 has the following eBGP configuration, and R2 has the equivalent.
If you look carefully at this config, I’m pretty sure that even non-Junos folks will understand what’s going on here — we have an eBGP peering that runs between the IPs on the cable that connects these devices together:
root@R1> show configuration protocols bgp
group TO_R2 {
type external;
peer-as 65502;
neighbor 10.1.2.2;
}I’ve run a packet capture (PCAP) on the resulting session. Looking at the IP header of the BGP open message from R1 to R2, we see a TTL of 1, as expected:
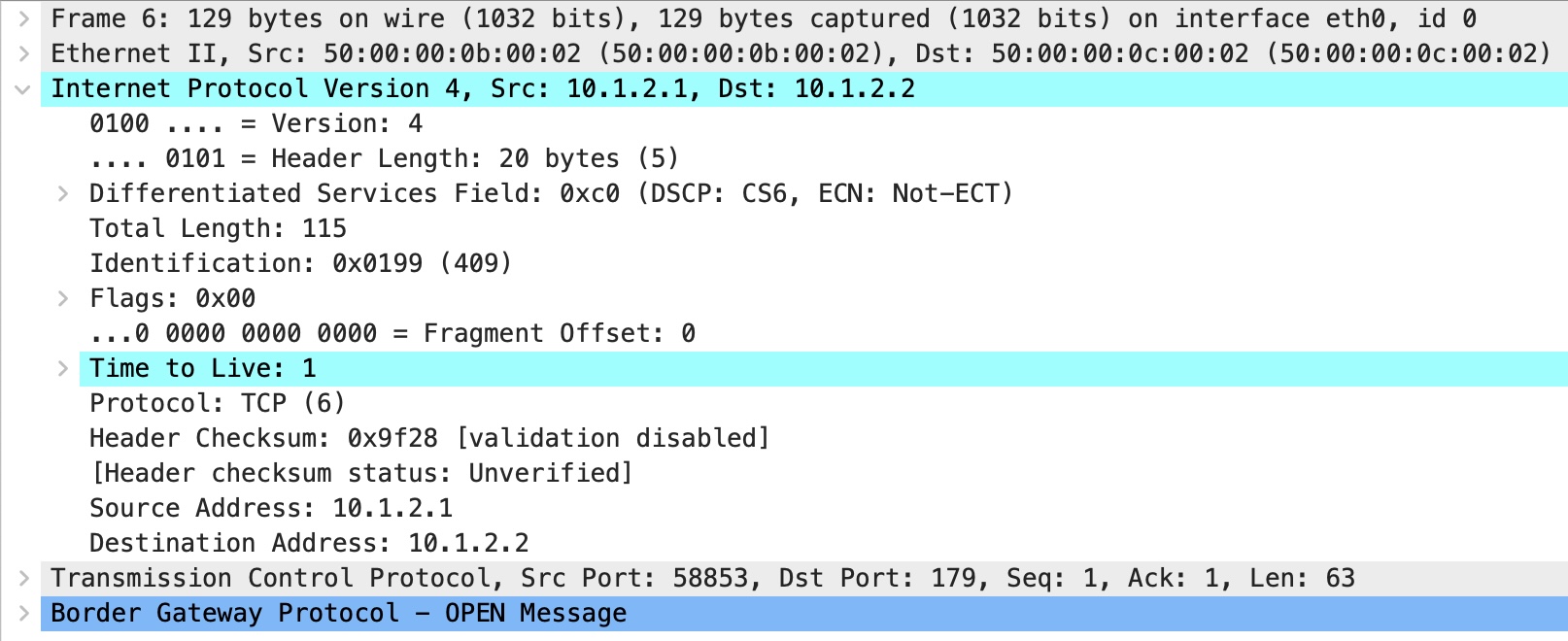
So far, so good!
Now, I’m going to delete this config and replace it with a source and destination of the two loopbacks. Remember, you saw from the pings earlier that R1 and R2 can talk to each other’s loopback IPs.
This is the config on R1. R2 has the equivalent config:
root@R1> show configuration protocols bgp
group TO_R2 {
type external;
local-address 192.168.1.1;
peer-as 65502;
neighbor 192.168.1.2;
}Before I commit, I start a fresh packet capture. I commit, and leave it for a few minutes:

This time, all BGP messages have stopped. It seems that both routers have followed the logic we mentioned earlier. The neighbor is not in a directly connected subnet, and therefore, the session is not even attempted.
As you would expect, both BGP sessions are in an idle state, because they are not attempting to establish:
root@R1> show bgp summary
Threading mode: BGP I/O
Default eBGP mode: advertise - accept, receive - accept
Groups: 1 Peers: 1 Down peers: 1
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet.0
0 0 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
192.168.1.2 65502 0 0 0 0 35 IdleThe so-called eBGP multihop solution
You may already know that the solution to this is to create a so-called ‘multihop’ peering.
Using this configuration statement, you can set the TTL to something else of your choosing. The result, as the command implies, is that you can create eBGP sessions that are multiple hops away.
Of course, in this case, we are absolutely not creating a multi-hop session. The BGP session is precisely one hop away, not two. And it’s exactly this point that confuses new students when they study how the IP TTL works. I dare say that this ‘multihop’ command has to be in the top 10 commands that confuse new students about how IP actually works.
If you were to read up on eBGP, you would learn that the TTL must be set to at least 2 for a loopback-to-loopback session to work between two directly connected devices. As such, a new student might reasonably conclude, therefore, that pings to a router’s loopback, for example, would decrement the TTL by 1 before the packet is processed by the loopback.
In other words, you might think that the TTL was decremented by one as soon as the packet arrives on the incoming interface, before any kind of processing. After all, why else would you need to set the TTL to 2?
In fact though, this is not the case at all. The reason for setting the TTL to 2 is to break the self-imposed rule we saw earlier. In effect, we are manually telling the router ‘it’s okay to make an eBGP session to this neighbor’.
Configuring eBGP multihop in Junos
Each vendor has their own way of configuring eBGP multihop, whether it be setting the TTL manually, or just letting your router take care of it.
Many examples from all vendors will set a TTL of 2. The reason for this is usually ‘security’, in that it means your session is very unlikely to accidentally travel so many hops away that an attacker could intercept.
We’ll talk more about that in a moment.
For the time being, let’s edit R1’s config to use a TTL of 2. The other router will remain unchanged:
[edit]
root@R1# set protocols bgp group TO_R2 neighbor 192.168.1.2 multihop ttl 2What happens next?
Our packet capture shows that a TCP handshake is successful in the first three packets (Figure 4). R1 sends a BGP Open message at packet 4, with a TTL of 2. However, R2 rejects it with a Notification message at packet 5. The remaining packets shut down the TCP session.
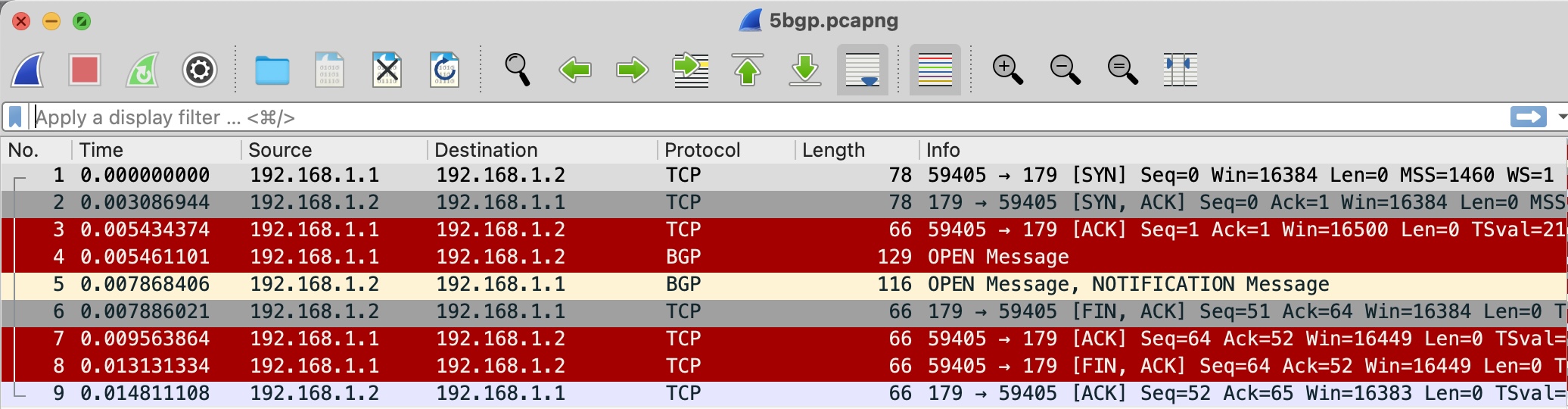
The fix, of course, is to set both ends to have a multihop TTL of 2. If you do this, the session will come up.
I could configure R2 with a TTL of 2 to prove this. But instead, let’s do something ‘cool’.
You see, in Junos, you can configure multihop with a TTL of 1!
Let’s do this on R1:
[edit]
root@R1# set protocols bgp group TO_R2 neighbor 192.168.1.2 multihop ttl 1And this on R2:
[edit]
root@R2# set protocols bgp group TO_R1 neighbor 192.168.1.1 multihop ttl 1And guess what? The BGP session comes up! Let’s filter the output to focus just on the line we care about:
root@R1> show bgp summary | match 192.168.1.2
192.168.1.2 65502 4 2 0 1 32 EstablThis proves that the TTL does not *have* to be 2 or more when you’re running eBGP between the loopbacks of two directly connected neighbors. A TTL of 1 works perfectly fine. You just need the correct configuration to make it happen.
Make no mistake about the way that the TTL field operates — its value is only decremented when it passes from one subnet to another, and from one device to another, whether that ‘device’ be physical or virtual.
We could end this post here — but there’s one final fun thing to tell you about.
The Generalized TTL Security Mechanism
On the surface, it might seem like a good idea to set a TTL of 1 for outgoing packets. This ensures that your router will never create a connection to a device that is multiple hops away, should your network be compromised. After all, why set it to 2 when you can set it to 1, and have everything work perfectly?
It’s not a bad idea from a security perspective. However, it turns out there’s an even bigger brain solution you can use.
Instead of a TTL of 1, what if you set the TTL to 255, and in addition, you configured your routers to only accept packets with a TTL of 255? A router that is genuinely multiple hops away would never be able to craft a packet like this, because the TTL would inevitably be decremented at each hop. If you receive any BGP packet on an interface with a TTL of 254 or less, you know that something isn’t right.
The name for this is the Generalized TTL Security Mechanism (GTSM). GTSM is defined in RFC 5082, and in Junos, the configuration is a three-step process.
First, you set a TTL of 255 on the eBGP peering. The configuration changes depending on whether your peering is to a directly connected IP, or to a loopback. If your peer is on a directly connected subnet, you configure it directly on the neighbor’s IP address:
[edit]
root@R1# set protocols bgp group TO_R2 neighbor 10.1.2.2 ttl 255If you’re using loopback IPs, you still need to enable ‘multihop’ because the neighbor is not on a directly connected subnet. You set the TTL under the multihop statement:
[edit]
root@R1# set protocols bgp group TO_R2 neighbor 192.168.1.2 multihop ttl 255If you try it the first way on a loopback IP, you’ll get a commit error:
[edit]
root@R1# set protocols bgp group TO_R2 neighbor 192.168.1.2 ttl 255
[edit]
root@R1# commit and-quit
[edit protocols bgp group TO_R2 neighbor 192.168.1.2 ttl]
'ttl 255'
This option is valid only for single-hop EBGP neighbor
error: commit failed: (statements constraint check failed)I’m going to use local interface IPs for this example.
Second, you create a firewall filter. For Cisco folks, IOS calls it an access list. I wrote about firewall filters here, if you want to learn how they work. For now, here’s the syntax in set format. Notice that I block all TCP packets on port 179 that don’t have a TTL of 255. You can add in some source addresses here too if you like:
root@R1> show configuration firewall family inet | display set relative
set filter TTL_SECURITY term BGP_NEIGHBOR from protocol tcp
set filter TTL_SECURITY term BGP_NEIGHBOR from ttl-except 255
set filter TTL_SECURITY term BGP_NEIGHBOR from port 179
set filter TTL_SECURITY term BGP_NEIGHBOR then discard
set filter TTL_SECURITY term ACCEPT_ALL_ELSE then acceptAnd here it is in hierarchy format:
root@R1> show configuration firewall family inet
filter TTL_SECURITY {
term BGP_NEIGHBOR {
from {
protocol tcp;
ttl-except 255;
port 179;
}
then {
discard;
}
}
term ACCEPT_ALL_ELSE {
then accept;
}
}Then, you apply the filter. This particular filter has been written to be applied on R1’s physical interface facing R2. Alternatively, with a bit more thought and editing, you could apply it to your loopback interface (lo0) to act directly on the control plane:
[edit]
root@R1# set interfaces ge-0/0/0 unit 0 family inet filter input TTL_SECURITYWhen I save my work, I can see the TTL is indeed 255:
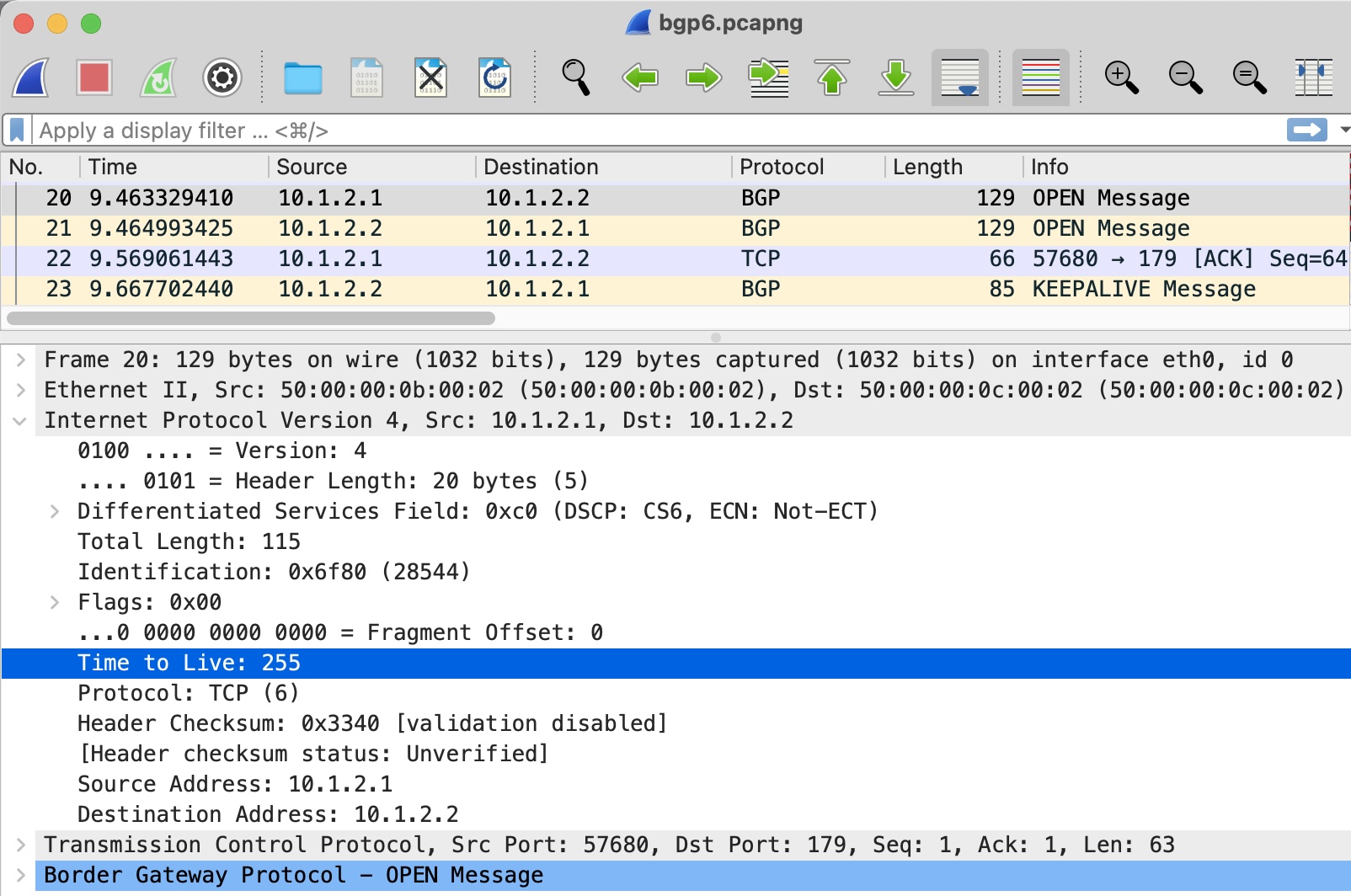
root@R1> show bgp summary | match 10.1.2.2
10.1.2.2 65502 16 14 0 3 6:07 EstablThat’s great and all but how do we know that this firewall filter is really protecting us from attack?
Let’s really verify this
Just to test this, let’s add a third router into the mix. Figure 6 introduces R3. We’re going to make a multihop eBGP session between R1 and R3’s loopback, with a TTL of 255.
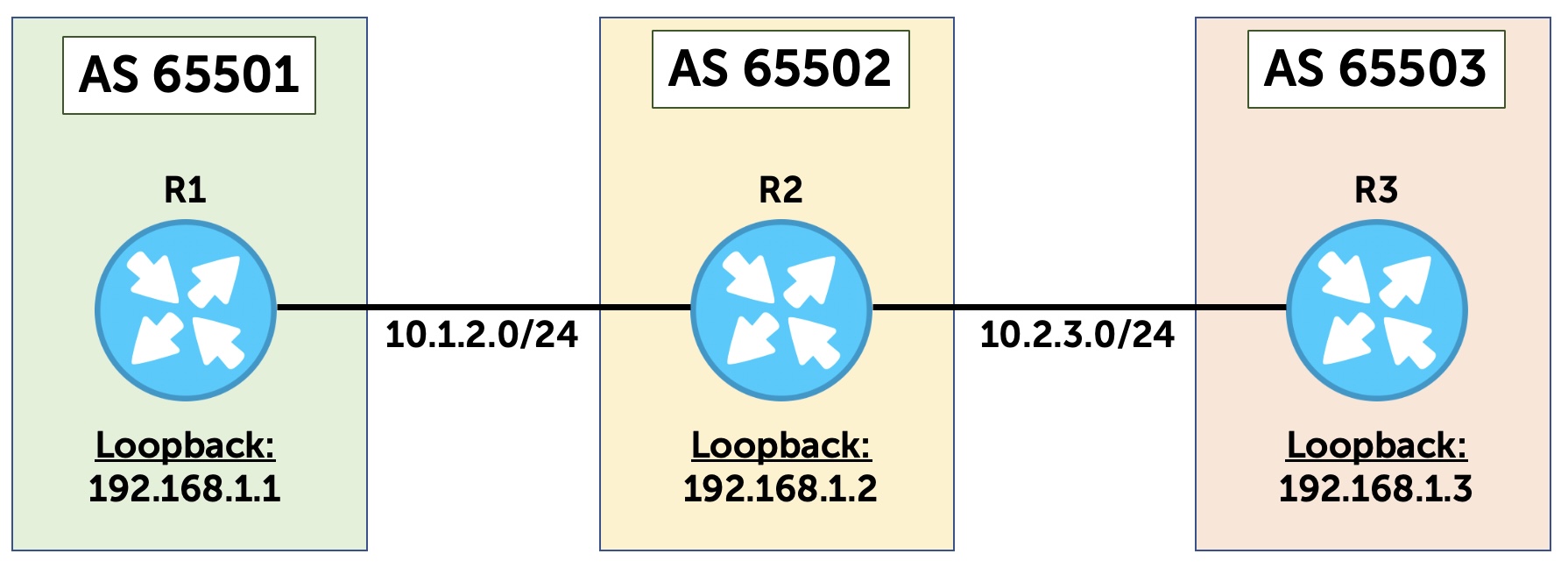
Let’s add this configuration to R1, and the equivalent on R3:
root@R1> show configuration protocols bgp group TO_R3 | display set
set protocols bgp group TO_R3 type external
set protocols bgp group TO_R3 local-address 192.168.1.1
set protocols bgp group TO_R3 peer-as 65503
set protocols bgp group TO_R3 neighbor 192.168.1.3 multihop ttl 255When our firewall filter is not applied to R1’s ge-0/0/0 interface (the physical interface facing R2), R1 has successful eBGP sessions to both R2 and R3:
root@R1> show bgp summary
Threading mode: BGP I/O
Default eBGP mode: advertise - accept, receive - accept
Groups: 2 Peers: 2 Down peers: 0
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet.0
0 0 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
10.1.2.2 65502 3 2 0 1 10 Establ
inet.0: 0/0/0/0
192.168.1.3 65503 3 2 0 1 10 Establ
inet.0: 0/0/0/0However, the story changes when we reapply our firewall filter. The session to R2 still works, because its incoming packets have a TTL of 255. However, R3’s packets have an incoming TTL of 254, and are therefore discarded:
root@R1> show bgp summary
Threading mode: BGP I/O
Default eBGP mode: advertise - accept, receive - accept
Groups: 2 Peers: 2 Down peers: 1
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet.0
0 0 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
10.1.2.2 65502 8 7 0 2 2:53 Establ
inet.0: 0/0/0/0
192.168.1.3 65503 0 0 0 2 2:56 ConnectThat’s it!
This stuff isn’t always well explained. Many places just go ‘yeah you need multihop because it’s not directly connected’, without explaining the real implications. No wonder so many new students get confused about how TTLs are processed by routers … I mean ‘Layer 3 devices’! Now you’ve read this post, you can have confidence about how this all works in your own network.
Hey, thanks very much for reading this! If you liked it, please share it with friends and colleagues. Check out my older posts if you fancy learning more cool networking and Junos stuff!
Chris Parker (Twitter, Mastodon) is a network engineer, instructor, and courseware developer for Juniper Networks with an interest in MPLS and Junos.
This post is adapted from the original at Network Fun-Times.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Wow! I think I am going to try this in the lab. Thanks for the article.
Thanks for this very well argued – and documented article. It’s true that I got the wrong end of the stick all this time as well. Thanks for enlightening me!
Cheers,
Pim