
Networking algorithms are often evaluated by running A/B tests. In an A/B test, we randomly allocate a small fraction of traffic (say 1% or 5%) to a ‘treatment group’ running the new algorithm, and compare its performance against the control group running the old algorithm. If the treatment group outperforms the control group in the various metrics we care about, we treat this as evidence that the new algorithm would perform well if deployed.
My colleagues and I at Stanford University and Netflix, recently published a paper at the Internet Measurement Conference 2021 (and which was one of the recipients of this year’s Applied Networking Research Prize) that showed how A/B tests can have extremely biased results when run over congested networks. We showed experiments where even the direction of the result is switched — a treatment that performs poorly in an A/B test could perform well when deployed, and vice versa.
The problem with networking A/B tests is interference
It is well known in causal inference that interference — when units in the treatment group change the behaviour of units in the control group — can bias experiment results. When this bias occurs, the estimates from a small-scale A/B test may not match the behaviour when deployed.
For example, imagine running an experiment in a social network as this paper describes. If the treatment makes a user more likely to message their friends, and their friends are allocated to the control group, then the treatment will increase usage for both treatment and control groups. This interference will bias the result of the experiment, and might even prevent us from measuring this increase in usage. There are many other published examples of interference in online marketplaces, education and disease.
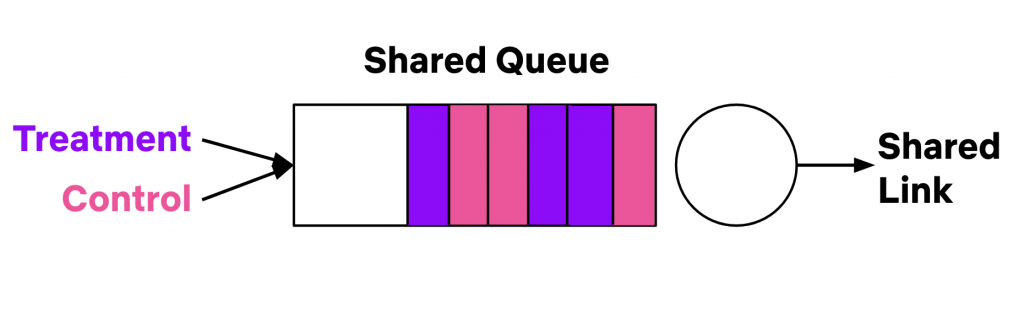
If we stop and think about experiments in computer networks, there is no question that interference exists! If we randomly assign traffic to treatment/control groups, both groups can use the same networks, and traverse the same links and same queues as in Figure 1. If the treatment algorithm used less bandwidth (for instance, by reducing the size of HTTP responses), there would be more bandwidth available for the control algorithm. If the treatment algorithm caused shorter queue lengths (for example, by changing the way we do congestion control), this would also decrease the queue lengths for the control algorithm.
There have been decades of research on the fairness of networking algorithms (see our related work section for a summary), all giving examples of how interference can occur between treatment and control.
The fact that interference exists led us to ask and answer two questions:
- We know interference exists, but does it matter? Does interference bias the outcome of A/B tests? Or worse, cause us to make bad decisions based on the results of A/B tests?
- If the interference matters, what can we do about it?
Measuring interference in a production experiment
We designed and ran an experiment showing that A/B tests run on congested networks can have biased outcomes.
Our experiment tested bitrate capping, and specifically whether it could reduce network congestion for Netflix. Netflix, and other major streaming services, worked with governments around the world to introduce bitrate capping in response to COVID-19. Services lowered the video quality they offered, which reduced overall load on the Internet and improved congestion.
However, in an A/B test we ran, bitrate capping didn’t appear to reduce congestion at all! In fact, it appeared to make things worse: Capped traffic experienced 5% lower throughput and 5-15% higher round trip times.
We then designed an experiment that was robust to interference. The experiment used a unique situation in Netflix’s production CDN — there was a pair of congested peering links, with well-balanced traffic between the two links. We could apply some treatment to only the traffic using one link, and compare the two links. This let us observe how capping would reduce the congestion on one link, relative to not capping on the other link. For more details about this experiment, please see our paper.
We found that bitrate capping did reduce congestion in a way that was not measurable by A/B tests. For instance, A/B tests measured a 5-15% worse round trip time, but bitrate capping actually improved round trip time by 25%.

What can we do about interference?
We use A/B tests extensively to evaluate new networking algorithms, so this experiment is concerning. But it also shows that we can use alternate experiment designs to measure interference and give unbiased estimates of treatment effects despite interference.
Some alternate experiment designs include time-based experiments where traffic is switched from control to treatment, for example event studies and switchback experiments. Figure 2 shows these designs. In an event study, we switch from all traffic using control to all traffic using treatment, and estimate the treatment effect by comparing before and after this event. In a switchback, we switch back and forth between control and treatment and estimate treatment effects by comparing the behaviour of treatment days to control days.

In our study we used data from our paired link experiment to simulate both event studies and switchbacks, and show that they give materially similar results and avoid the bias of A/B tests. In the paper, we also discuss how these experiment designs can be integrated into development processes for networking algorithms.
What’s next
Interference can bias the results of networking A/B tests, and it is our responsibility as a community to be aware of this phenomenon. We would love to see more work in networking evaluated with congestion interference in mind, especially high consequence proposals such as new Internet standards.
On the research side, there is much more work to be done on evaluating algorithms at scale in congested networks. We encourage further studies to measure bias in different networks and using different algorithms. We think it would be valuable to design new experiments and analyses specifically for congested networks.
Please leave a comment or email bspang@stanford.edu if you have any questions.
Contributors: Veronica Hannan, Shravya Kunamalla, Te-Yuan Huang, Nick McKeown, Ramesh Johari.
Bruce Spang is a fifth-year PhD candidate at Stanford University, where he researches computer networking.
Discuss on Hacker NewsThe views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.