

In the first post in this series, we looked at how to connect your devices directly to each other, no matter what’s standing between them. This post looks at navigating the network.
We can think of Network Address Translation (NAT) devices as stateful firewalls with one more really annoying feature; in addition to all the stateful firewalling stuff, they also alter packets as they go through.
A NAT device is anything that does any kind of network address translation, that is, altering the source or destination IP address or port. However, when talking about connectivity problems and NAT traversal, all the problems come from Source NAT (SNAT). As you might expect, there is also Destination NAT (DNAT), and it’s very useful but not relevant to NAT traversal.
The most common use of SNAT is to connect many devices to the Internet, using fewer IP addresses than the number of devices. In the case of consumer-grade routers, we map all devices onto a single public-facing IP address. This is desirable because it turns out that there are many more devices in the world that want Internet access, than IP addresses to give them (at least in IPv4 — we’ll come to IPv6 in a little bit). NATs let us have many devices sharing a single IP address, so despite the global depletion of the available IPv4 address pool, we can scale the Internet further with the addresses at hand.
Navigating a NATty network
Let’s look at what happens when your laptop is connected to your home Wi-Fi and talks to a server on the Internet.
Your laptop sends UDP packets from 192.168.0.20:1234 to 7.7.7.7:5678. This is exactly the same as if the laptop had a public IP. But that won’t work on the Internet: 192.168.0.20 is a private IP address, which appears on many different peoples’ private networks. The Internet won’t know how to get responses back to us.
Enter the home router. The laptop’s packets flow through the home router on their way to the Internet, and the router sees that this is a new session that it’s never seen before.
It knows that 192.168.0.20 won’t fly on the Internet, but it can work around that; it picks some unused UDP port on its own public IP address — we’ll use 2.2.2.2:4242 — and creates a NAT mapping that establishes an equivalence: 192.168.0.20:1234 on the LAN side is the same as 2.2.2.2:4242 on the Internet side.
From now on, whenever it sees packets that match that mapping, it will rewrite the IPs and ports in the packet appropriately.
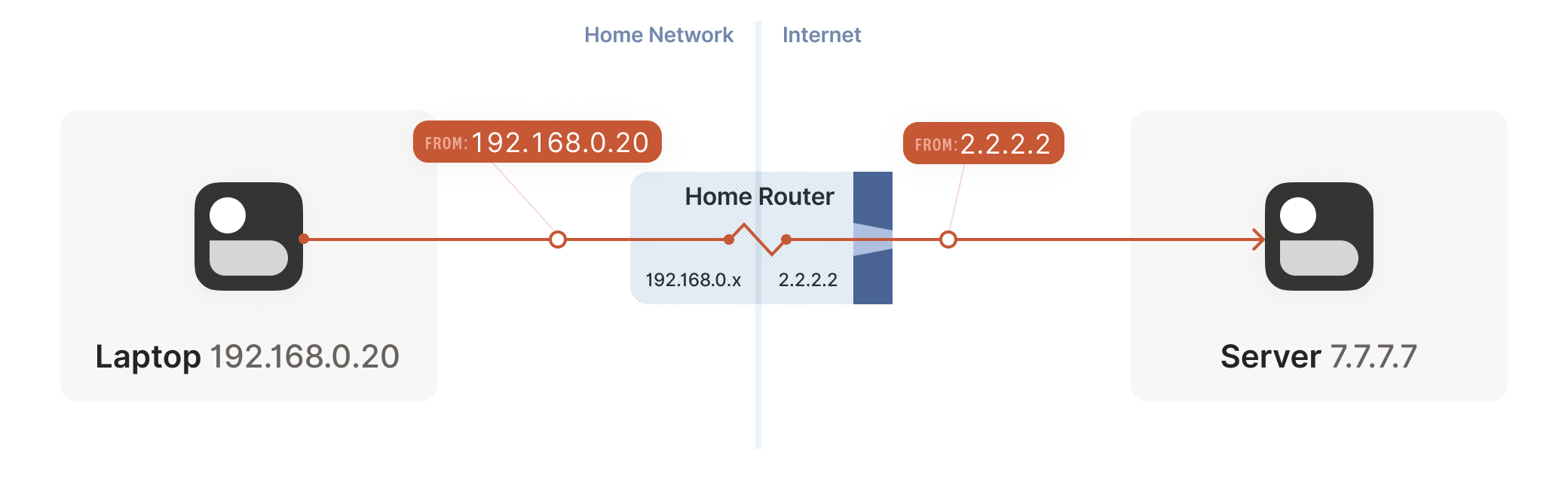
Resuming our packet’s journey, the home router applies the NAT mapping it just created and sends the packet onwards to the Internet. Only now, the packet is from 2.2.2.2:4242, not 192.168.0.20:1234. It goes on to the server, which is none the wiser. It’s communicating with 2.2.2.2:4242, like in our previous examples without NAT.
Responses from the server flow back the other way as you’d expect, with the home router rewriting 2.2.2.2:4242 back to 192.168.0.20:1234. The laptop is also none the wiser; from its perspective, the Internet magically figured out what to do with its private IP address.
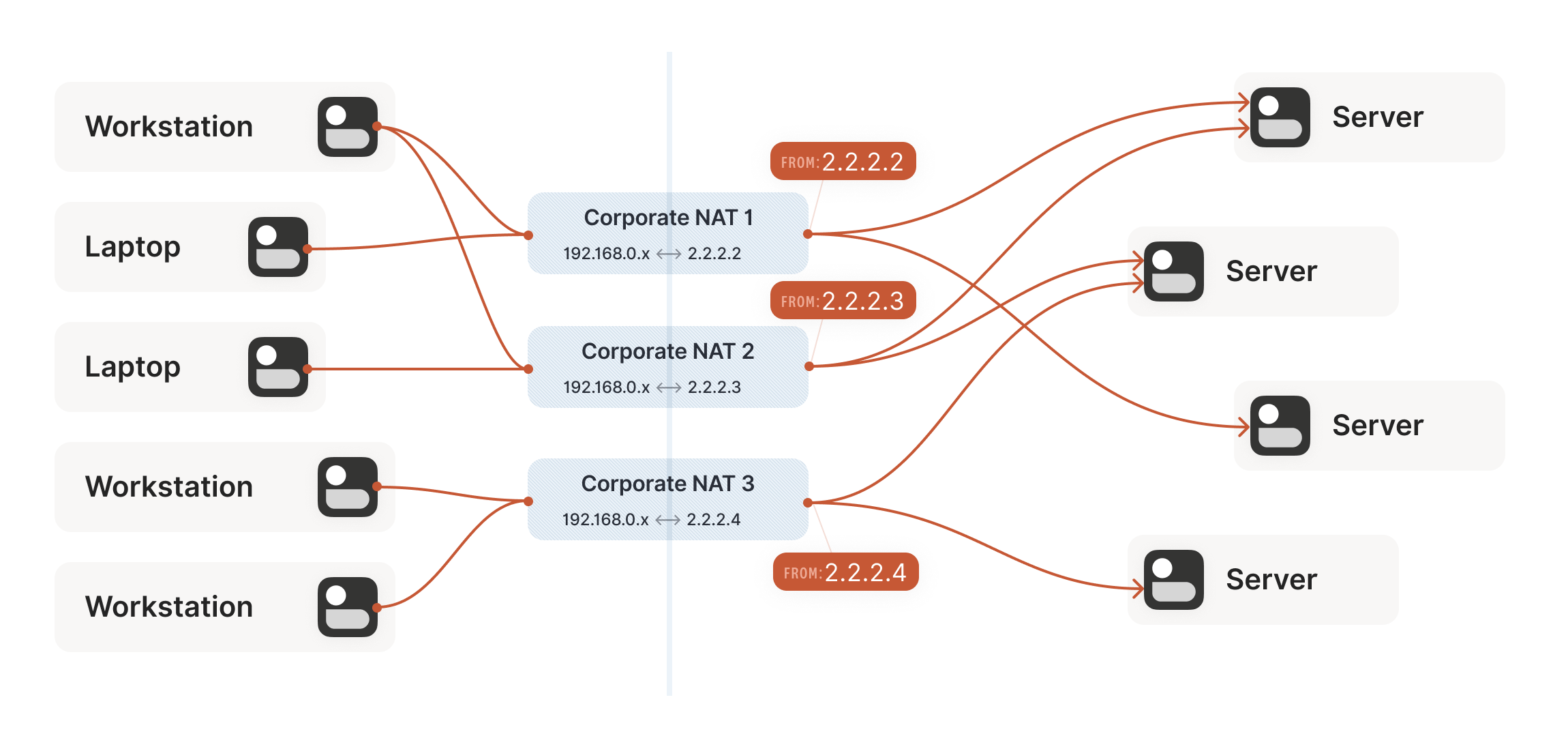
Our example here was with a home router, but the same principle applies on corporate networks. The usual difference there is that the NAT layer consists of multiple machines (for high availability or capacity reasons), and they can have more than one public IP address, so that they have more public ip:port combinations to choose from and can sustain more active clients at once.
A study in STUN
We now have a problem that looks like our earlier scenario with stateful firewalls, but with NAT devices:
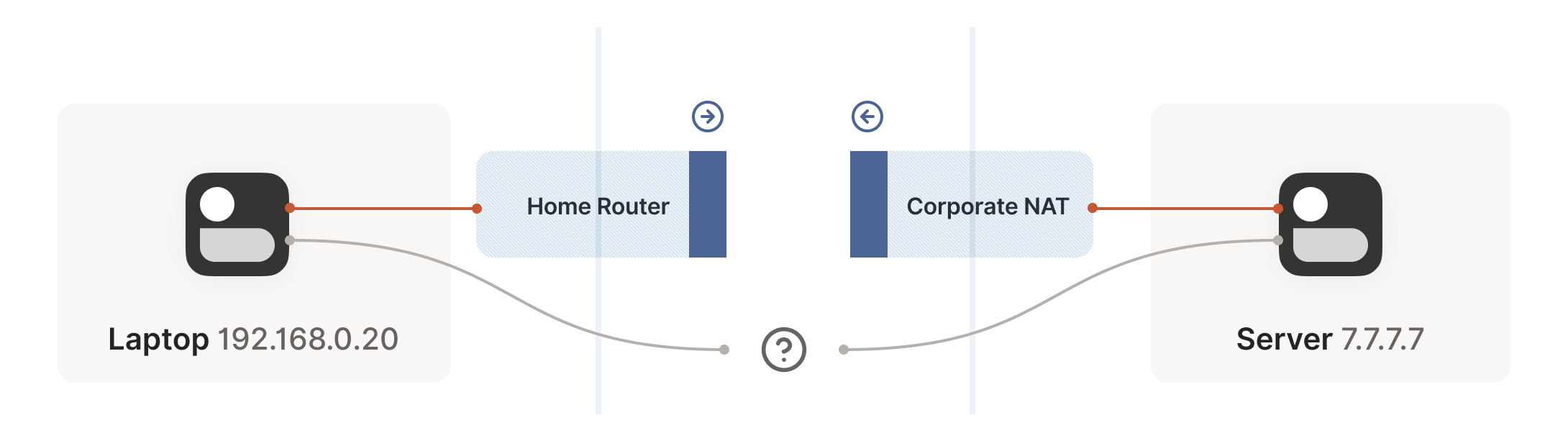
Our problem is that our two peers don’t know what the ip:port of their peer is. Worse, strictly speaking there is no ip:port until the other peer sends packets, since NAT mappings only get created when outbound traffic towards the Internet requires it. We’re back to our stateful firewall problem, only worse. Both sides have to speak first, but neither side knows to whom to speak, and can’t know until the other side speaks first.
How do we break the deadlock? That’s where STUN comes in. STUN is both a set of studies of the detailed behaviour of NAT devices, and a protocol that aids in NAT traversal. The main thing we care about for now is the network protocol.
STUN relies on a simple observation. When you talk to a server on the Internet from a NATed client, the server sees the public ip:port that your NAT device created for you, not your LAN ip:port. So, the server can tell you what ip:port it saw. That way, you know what traffic from your LAN ip:port looks like on the Internet, you can tell your peers about that mapping, and now they know where to send packets! We’re back to our ‘simple’ case of firewall traversal.
That’s fundamentally all that the STUN protocol is — your machine sends a ‘what’s my endpoint from your point of view?’ request to a STUN server, and the server replies with ‘here’s the ip:port that I saw your UDP packet coming from.’
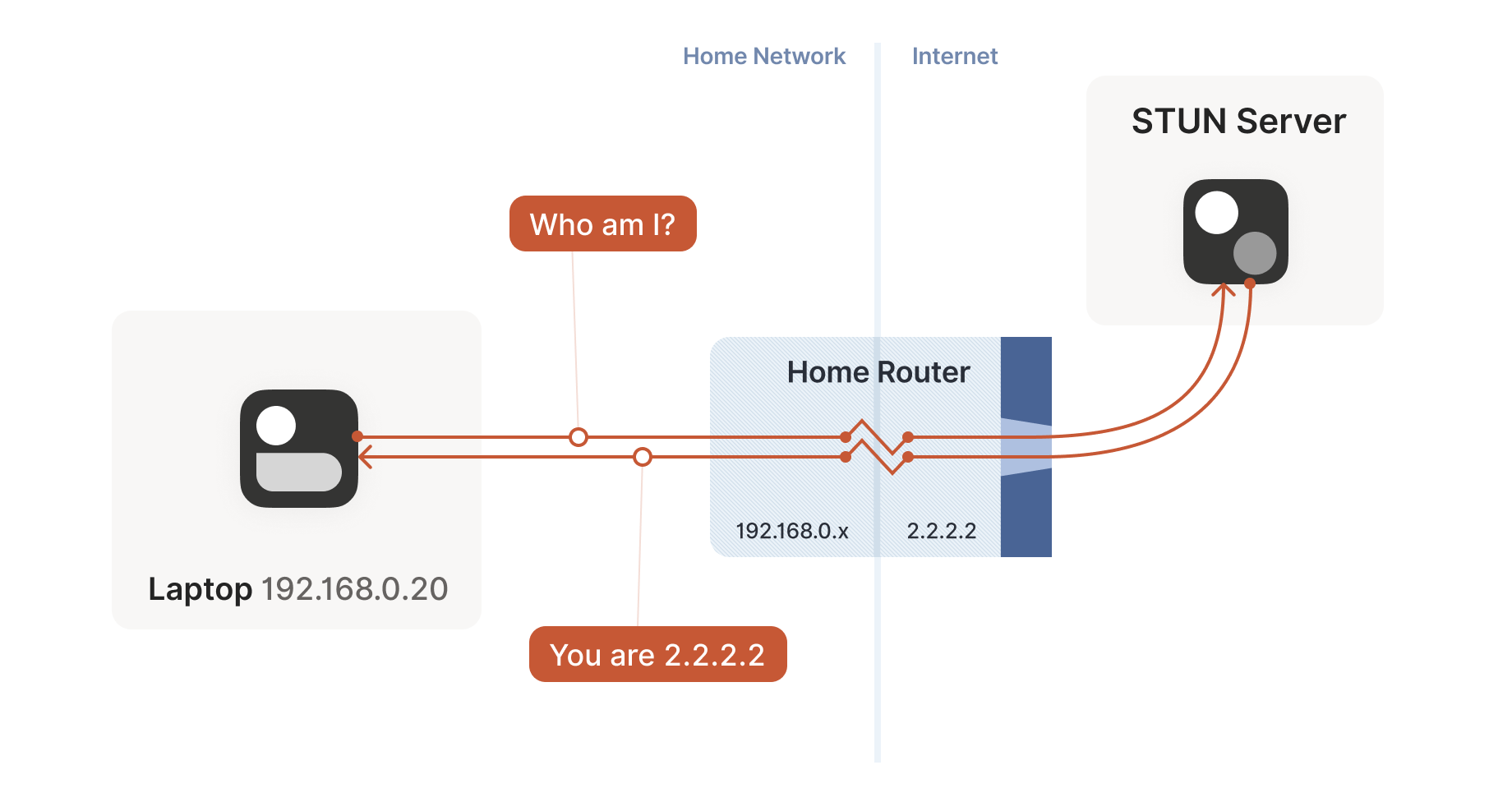
The STUN protocol has a bunch more stuff in it — there’s a way of obfuscating the ip:port in the response to stop really broken NATs from mangling the packet’s payload, and a whole authentication mechanism that only really gets used by TURN and ICE, sibling protocols to STUN that we’ll talk about in a bit. We can ignore all that stuff for address discovery.
Incidentally, this is why we said at the beginning of the series that if you want to implement this yourself, the NAT traversal logic and your main protocol have to share a network socket. Each socket gets a different mapping on the NAT device, so in order to discover your public ip:port, you have to send and receive STUN packets from the socket that you intend to use for communication, otherwise you’ll get a useless answer.
How this helps
Given STUN as a tool, it seems like we’re close to done. Each machine can do STUN to discover the public-facing ip:port for its local socket, tell its peers what that is, everyone does the firewall traversal stuff, and we’re all set… Right?
Well, it’s a mixed bag. This will work in some cases, but not others. Generally speaking, this will work with most home routers, and will fail with some corporate NAT gateways. The probability of failure increases the more the NAT device’s brochure mentions that it’s a security device (NATs do not enhance security in any meaningful way, but that’s a rant for another time).
The problem is an assumption we made earlier. When the STUN server told us that we’re 2.2.2.2:4242 from its perspective, we assumed that meant that we’re 2.2.2.2:4242 from the entire Internet’s perspective and that therefore anyone can reach us by talking to 2.2.2.2:4242.
As it turns out, that’s not always true. Some NAT devices behave exactly in line with our assumptions. Their stateful firewall component still wants to see packets flowing in the right order, but we can reliably figure out the correct ip:port to give to our peer and do our simultaneous transmission trick to get through. Those NATs are great, and our combination of STUN and the simultaneous packet sending will work fine with those.
In theory, there are also NAT devices that are super relaxed and don’t ship with stateful firewall stuff at all. In those, you don’t even need simultaneous transmission, the STUN request gives you an Internet ip:port that anyone can connect to with no further ceremony. If such devices do still exist, they’re increasingly rare.
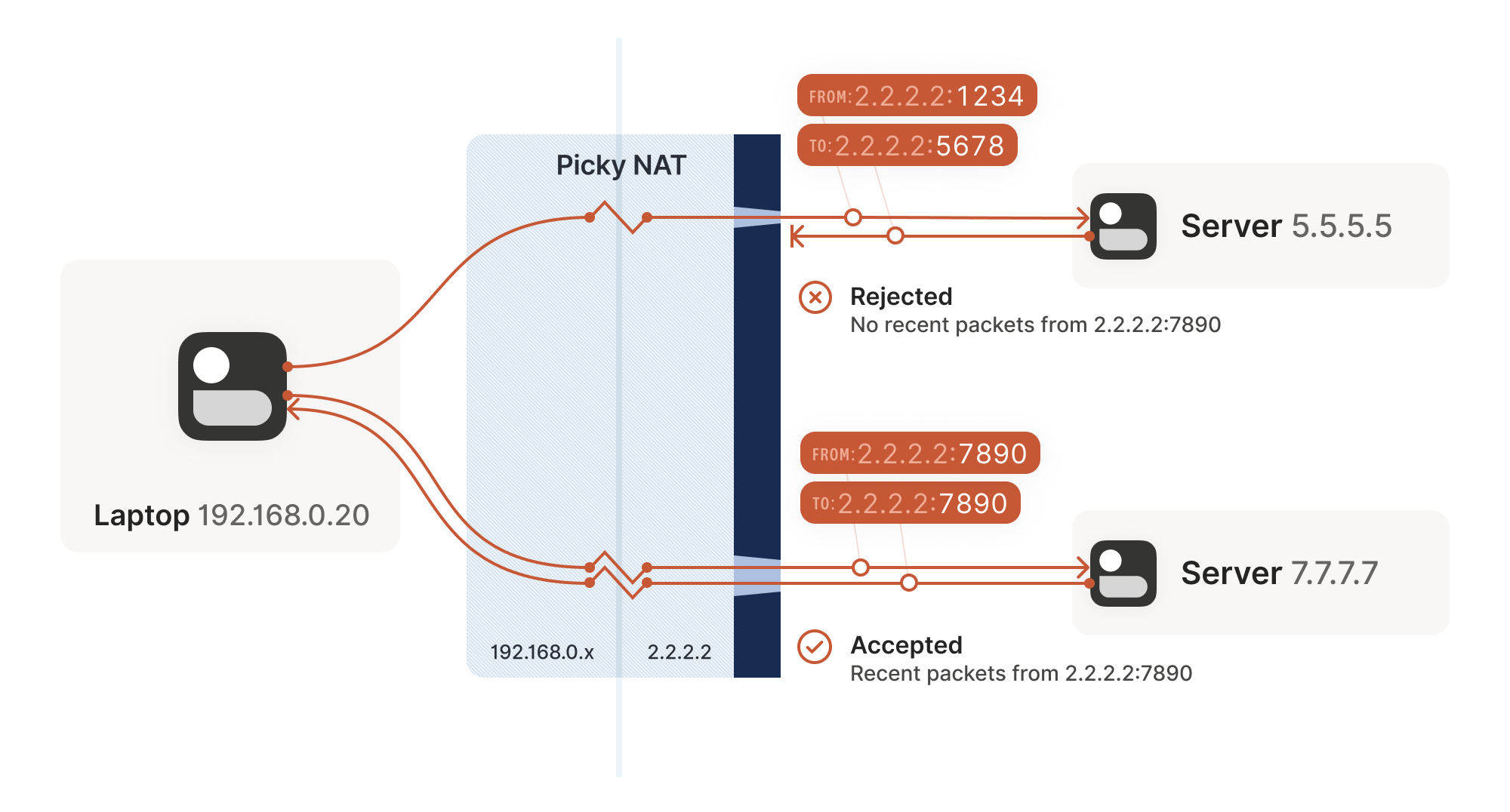
Other NAT devices are more difficult and create a completely different NAT mapping for every different destination that you talk to. On such a device, if we use the same socket to send to 5.5.5.5:1234 and 7.7.7.7:2345, we’ll end up with two different ports on 2.2.2.2, one for each destination. If you use the wrong port to talk back, you don’t get through.
Naming our NATs
Now that we’ve discovered that not all NAT devices behave in the same way, we should talk terminology. If you’ve done anything related to NAT traversal before, you might have heard of ‘Full Cone’, ‘Restricted Cone’, ‘Port-Restricted Cone’ and ‘Symmetric’ NATs. These are terms that come from early research into NAT traversal.
That terminology is honestly quite confusing. I always look up what a Restricted Cone NAT is supposed to be. Empirically, I’m not alone in this, because most of the Internet calls ‘easy’ NATs Full Cone, when these days they’re much more likely to be Port-Restricted Cone.
More recent research and RFCs have come up with a much better taxonomy. First of all, they recognize that there are many more varying dimensions of behaviour than the single ‘cone’ dimension of earlier research, so focusing on the cone-ness of your NAT isn’t necessarily helpful. Second, they came up with words that more plainly convey what the NAT is doing.
The ‘easy’ and ‘hard’ NATs above differ in a single dimension, whether their NAT mappings depend on what the destination is, or not. RFC 4787 calls the easy variant Endpoint-Independent Mapping (EIM), and the hard variant Endpoint-Dependent Mapping (EDM). There’s a subcategory of EDM that specifies whether the mapping varies only on the destination IP, or on both the destination IP and port. For NAT traversal, the distinction doesn’t matter. Both kinds of EDM NATs are equally bad news for us.
In the grand tradition of naming things being hard, endpoint-independent NATs still depend on an endpoint. Each source ip:port gets a different mapping, because otherwise your packets would get mixed up with someone else’s packets, and that would be chaos. Strictly speaking, we should say ‘Destination Endpoint Independent Mapping’ (DEIM?), but that’s a mouthful, and since ‘Source Endpoint Independent Mapping’ would be another way to say broken, we don’t specify. Endpoint always means ‘Destination Endpoint’.
You might be wondering how two kinds of endpoint dependence maps into four kinds of cone-ness. The answer is that cone-ness encompasses two orthogonal dimensions of NAT behaviour. One is NAT mapping behaviour, which we looked at above, and the other is stateful firewall behaviour. Like NAT mapping behaviour, the firewalls can be Endpoint-Independent or a couple of variants of Endpoint-Dependent. If you throw all of these into a matrix, you can reconstruct the cone-ness of a NAT from its more fundamental properties, as shown in Table 1.
| Endpoint-Independent NAT mapping | Endpoint-Dependent NAT mapping (all types) | |
| Endpoint-Independent firewall | Full Cone NAT | N/A* |
| Endpoint-Dependent firewall (destination IP only) | Restricted Cone NAT | N/A* |
| Endpoint-Dependent firewall (destination IP + port) | Port-Restricted Cone NAT | Symmetric NAT |
Table 1 — NAT cone types. *Can theoretically exist, but don’t show up in the wild.
Once broken down like this, we can see that cone-ness isn’t terribly useful to us. The major distinction we care about is Symmetric versus anything else — in other words, we care about whether a NAT device is EIM or EDM.
While it’s neat to know exactly how your firewall behaves, we don’t care from the point of view of writing NAT traversal code. Our simultaneous transmission trick will get through all three variants of firewalls. In the wild, we’re overwhelmingly dealing only with IP-and-port endpoint-dependent firewalls. So, for practical code, we can simplify the table down to:
| Endpoint-Independent NAT mapping | Endpoint-Dependent NAT mapping (dest. IP only) | |
| Firewall is yes | Easy NAT | Hard NAT |
Table 2 — Simplified for on IP-and-port endpoint-dependent firewalls.
If you’d like to read more about the newer taxonomies of NATs, you can get the full details in RFC 4787 (NAT Behavioral Requirements for UDP), RFC 5382 (for TCP) and RFC 5508 (for ICMP). If you’re implementing a NAT device, these RFCs are also your guide to what behaviours you should implement, to make them well-behaved devices that play well with others and don’t generate complaints about Halo multiplayer not working.
Back to our NAT traversal. We were doing well with STUN and firewall traversal, but these hard NATs are a big problem. It only takes one of them in the whole path to break our current traversal plans.
But wait, this post is titled ‘how NAT traversal works, not ‘how NAT traversal doesn’t work’. So presumably, I have a trick up my sleeve to get out of this, right?
Have you considered giving up?
This is a good time to have the awkward part of our chat; what happens when we empty our entire bag of tricks, and we still can’t get through? A lot of NAT traversal code out there gives up and declares connectivity impossible. That’s obviously not acceptable for us; Tailscale is nothing without the connectivity.
We could use a relay that both sides can talk to unimpeded, and have it shuffle packets back and forth. But wait, isn’t that terrible?
Sort of. It’s certainly not as good as a direct connection, but if the relay is ‘near enough’ to the network path your direct connection would have taken, and has enough bandwidth, the impact on your connection quality isn’t huge. There will be a bit more latency, maybe less bandwidth. That’s still much better than no connection at all, which is where we were heading.
And keep in mind that we only resort to this in cases where direct connections fail. We can still establish direct connections through a lot of different networks. Having relays to handle the long tail isn’t that bad.
Additionally, some networks can break our connectivity much more directly than by having a difficult NAT. For example, we’ve observed that the UC Berkeley guest Wi-Fi blocks all outbound UDP except for DNS traffic. No amount of clever NAT tricks is going to get around the firewall eating your packets. So, we need some kind of reliable fallback no matter what.
You could implement relays in a variety of ways. The classic way is a protocol called Traversal Using Relays around NAT (TURN). We’ll skip the protocol details, but the idea is that you authenticate yourself to a TURN server on the Internet, and it tells you ‘okay, I’ve allocated ip:port, and will relay packets for you.’ You tell your peer the TURN ip:port, and we’re back to a completely trivial client/server communication scenario.
For Tailscale, we didn’t use TURN for our relays. It’s not a particularly pleasant protocol to work with, and unlike STUN, there’s no real interoperability benefit since there are no open TURN servers on the Internet.
Instead, we created Detoured Encrypted Routing Protocol (DERP), which is a general-purpose packet relaying protocol. It runs over HTTP, which is handy on networks with strict outbound rules, and relays encrypted payloads based on the destination’s public key.
As we briefly touched on earlier, we use this communication path both as a data relay when NAT traversal fails (in the same role as TURN in other systems) and as the side channel to help with NAT traversal. DERP is both our fallback of last resort to get connectivity, and our helper to upgrade to a peer-to-peer connection, when that’s possible.
Now that we have a relay, in addition to the traversal tricks we’ve discussed so far, we’re in pretty good shape. We can’t get through everything, but we can get through quite a lot, and we have a backup for when we fail. If you stopped reading now and implemented just the above, I’d estimate you could get a direct connection over 90% of the time, and your relays guarantee some connectivity all the time.
However, in the next post in this series we’ll look at what more can be done if you’re not satisfied with ‘good enough’.
David Anderson is a software engineer at Tailscale, interested in distributed systems and cluster management, electronics, and writing write open-source software.
This post is adapted from the original at Tailscale Blog.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
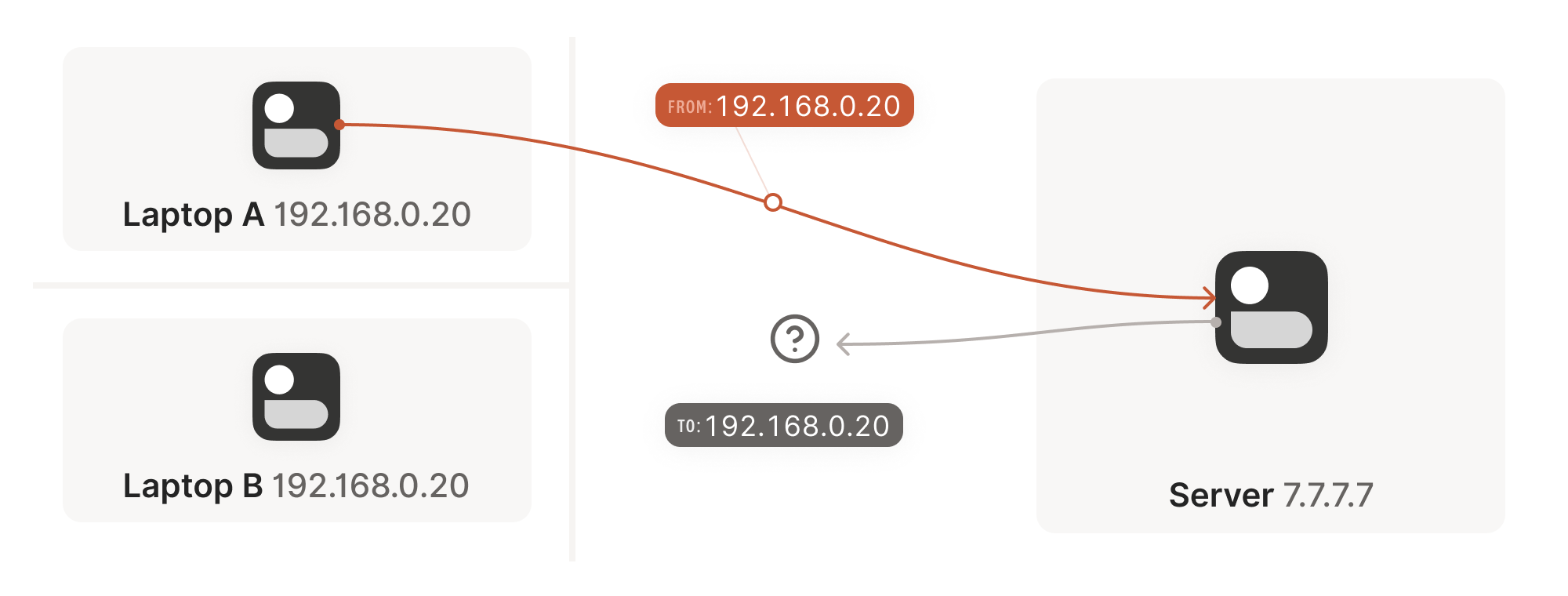
I’m very appreciative of your articles. I noticed in Figure 1 of “The nature of NATs” that Laptop A and Laptop B are both shown with the same 192.168.0.20. Correcting that would maintain the excellent standard your articles provide. Thanks
I believe that is intentional?
I assumed it is telling us that there can be another device in another network which has the same IP.
Which is why in the next part he introduces our Router
This content is so helpful, the pictures really helps to understand how packets flow during the traversal. And it helps me A LOT during my colllege essay.
I sincerely appreciate Mr.David Anderson for writing this article, and I hope everyone will benefit while reading this article.