

Over several months leading up to May 2021, Comcast deployed Resource Public Key Infrastructure (RPKI) on its network to defend against BGP route hijacks and leaks. Given the size and technical diversity of our network, deploying RPKI represented a significant effort, yet we were able to implement this security improvement without disrupting performance for our customers.
In this post, I want to share some of the lessons we learned from deploying RPKI to help others in their own deployment.
Why did Comcast start to deploy RPKI?
RPKI has matured greatly in the last few years with many network operators, including some of the largest connectivity and content providers, starting to both cryptographically sign their route information by issuing Route Origin Authorizations (ROAs) and validate the cryptographic signatures of other networks’ route information via Route Origin Validation (ROV).
Keep in mind that ROV essentially has two functions:
- ‘Writing’ (issuing ROAs to cover the address blocks you have been assigned)
- ‘Reading’ (using ROAs that others have issued to validate BGP routes you receive)
Note that both functions are not required and there’s no requirement to do them sequentially in a particular order if you do perform both.
Furthermore, it’s not all-or-nothing on either front; each can be deployed incrementally, though the most benefits accrue as the coverage widens.
Our decision to ‘sign’ our routes and validate other networks’ routing information means we and our customers are less likely to be impacted by a hijack of our IP addresses, and in turn, are helping reduce the overall impact of hijacking on the Internet.
Other important considerations, as with any project, are the time associated with making the updates and the risk of adverse customer effects along the way. Deploying RPKI doesn’t require any new equipment apart from a few virtual machines running open-source software and risks can be mitigated through incremental rollouts (both topics are addressed below).
One of the most important parts of the project was presenting it to senior management to get their buy-in. You can’t just say ‘well, there’s this new cool technology called RPKI that we should deploy because it’s awesome and just take my word for it’. Like all things it takes time and education, but briefing them on different routing security incidents and deployment case studies helps make the case.
Choose the RPKI model right for you: Hosted, delegated, or hybrid
Before you start signing your ROAs, an important decision you’ll have to make is how will you publish them. Currently, there are three ways you can do this:
- Hosted RPKI model — Your Regional Internet Registry (RIR) runs the Certificate Authority (CA), the publication server, and the repository. This model is the least expensive because the ISP has the least responsibility as well as the least control.
- Delegated RPKI model — The ISP runs everything, including the CA, the publication server, and the repository. This model is the most expensive because the ISP has all the responsibility as well as all the control.
- Hybrid RPKI model — The ISP runs the CA, but the RIR runs the publication server and the repository. This model is balanced, giving the ISP only some of the control and responsibility.
We chose the hosted RPKI model, as it’s easy to use and has plenty of support. For example, some RIRs make it easy to look at the global BGP table for the announcements matching for your address space and just say publish ROAs that match those current announcements, assuming that you agree those are all correct.
If you go down the road of either of the other two models (each of which has merit) it’s important to keep in mind that to fetch all ROAs published by all validating caches on the Internet, your publication point needs to be globally reachable.
Start from the bottom of your network and work your way up
Of course, rolling out any new network-wide project has its risks. But with the growing impact of hijacks, and the reputational impact they can have, the operational risks — in this case from misconfigured ROAs — far outweighed the risk of doing nothing.
Importantly, RPKI can be rolled out gradually, so this allows you to test for and mitigate a lot of the risks along the way. We had a backout plan for every step and sub-step of the overall project.
As such, we took a very bottom-up approach when rolling it out. Issuing a ROA for large blocks makes routes for all the prefixes underneath invalid, which will lead to reachability problems for a whole bunch of your networks.
Our approach was to start at the bottom and sign a few specific and non-intrusive prefixes before issuing ROAs for our top-level blocks. Even though we have over 100 address blocks spread over two dozen internal Autonomous System Numbers (ASNs), we ended up having to create several thousand ROAs, mostly because of IPv6 — even though there are fewer top-level blocks there’s so much more fragmentation you could do potentially with those.
We chose two validators for diversity and resilience
Best current practice suggests that you run two validators, not just for redundancy, but also because validation states change to NOT FOUND for all routes when RPKI-enabled routers lose connection with the validators.
We had the idea to run the validators in two geographically diverse data centres, in case one data centre has a transient issue. Also, we wanted to use two different software implementations in case one of those had some problem.
This was a particularly useful approach given that one of our initial validators, the RIPE RPKI Validator, ceased to offer maintenance support from 1 July 2021. As such, we ended up switching over to a different validator called rpki-client. This does validation and has a separate component called StayRTR, which is an implementation of the RPKI to Router (RTR) protocol (RFC 6810) and publishes RPKI prefix origin data from a trusted cache to BGP routers.
The other validator we use is Routinator, which is maintained by NLnet Labs and is written in the Rust programming language. It’s an all-in-one validator and RTR server.
Thus, we had two different software packages running in two different data centres for a total of four. Each router doing ROV is configured with RTR connections to all four instances.
Both rpki-client and Routinator have packages for RedHat and Debian distribution, so they’re easy to install and keep updated. They can also produce metrics for monitoring and reporting (for rpki-client, there’s a wrapper called rpki-client-web that produces the metrics).
We found that the best team to look after and maintain this project was our DNS team. This was because they had experience with managing servers and software with high availability, whereas the networking department manages routers.
How it works
Figure 2 provides an overview of RPKI ROV infrastructure design.
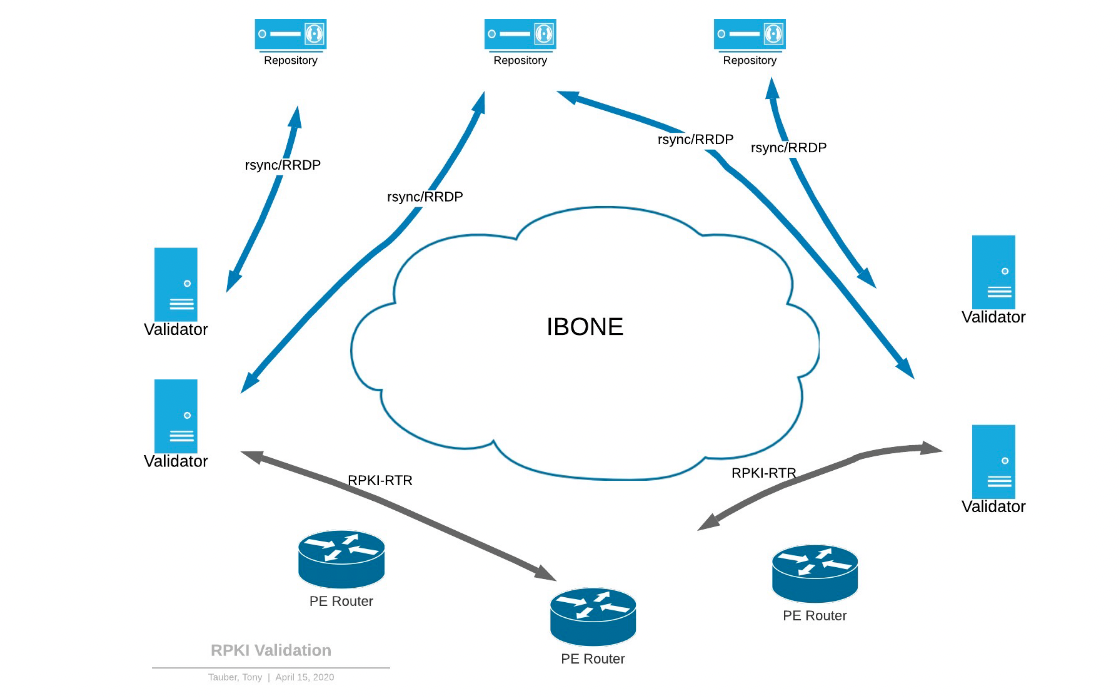
On the left and right we’ve got a pair of validators, in our ‘East’ and ‘West’ data centres.
At the top are several different repositories that exist out on the Internet — the validating cache servers fetch data from these repositories using rsync and/or RPKI Repository Delta Protocol (RRDP).
At the bottom are our edge routers, which our validators use to validate traffic with via the RTR protocol.
We hope by sharing our experience it will give you a better understanding of the process of deploying RPKI and show that it is manageable with proper planning.
Tony Tauber is a Distinguished Engineer at Comcast.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.