

The network is the most sensitive part of an organization’s infrastructure. That’s why it’s good practice to validate configurations before deploying new changes to the production environment.
This post provides insights on how my organization tests and validates network changes, and how this contributes to the level of trust we and our customers have in our services.
The design and implementation were in two people’s heads.
Back in 2015, we didn’t have any network automation. Instead, there were a couple of core routers (Cisco 6500 series) per data centre and plenty of rather unmanaged HP switches to provide basic L2 connectivity. It was pretty simple, with no high availability, a huge failure domain, no spare devices, and so on.
No version control existed at that time, meaning configurations were kept somewhere or at some person’s computer. How did we manage to run this network without automation, validation, and deployment? And how did we validate whether the config was good or not?
The short answer is, we didn’t. It was just some eyeballing, pushing changes directly via the command line interface (CLI), and praying. Even the config rollback feature wasn’t available. The out-of-band network did not exist. If you cut the connection, you were lost (similar to what happened at Facebook recently), and only physical access can help you bring it back.
The changes in the production network were painful and prone to human error. We had poor monitoring with basic alerting rules and a couple of traffic and errors graphs. There was no centralized logging system, but that was definitely better than nothing. It’s not an exaggeration to say that nowadays, small companies use this kind of simple method to monitor the network. If it’s working well and is good enough to function, don’t touch it.
The less you know about the state of the network, the fewer problems you have. Overall, we didn’t have any internal or external tools to do that fundamentally.
Automating our network
In 2016, we started building an IPv6-only service. Since it was being built from scratch, we began shipping automation from day 0. As soon as we noticed the good impact automation had, we started building new data centres using Cumulus Linux, automating them with Ansible, and deploying the changes using Jenkins.
The simplified workflow was:
- Do the changes.
- Commit the changes and create a Pull Request on Github.
- Wait for other people to review it.
- Merge the Pull Request.
- Wait for the changes to be deployed by Jenkins to the switches.
The drawback of this scheme is that configuration changes are automated but not validated or even tested before the deployment. That can cause substantial blast-radius failure. For instance, if a wrong loopback address or route-map is deployed, it can cause BGP sessions to flap or send the whole network into chaos.
The main reason for adding automation and validation is to save time debugging real problems in production, reduce the downtime, and make end users happier. However, you always have to ask yourself — where do you draw the line for automation? When does automating things stop adding value? How do you choose and deploy automation processes that make sense?
Since then, we have focused on how to improve this process even more. When your network is growing and you build more and more data centres, maintenance is getting harder, slowing down the process of pushing changes in production.
As always, you have to trade off between slower versus safer deployment. Because we are customer-obsessed, we prefer slower process management that leads to fewer unplanned downtimes.
Every failure gives you a new lesson on improving things and avoiding the same losses happening in the future. That’s why validation is a must for a modern network.
While most of the changes basically involve testing layers 2, 3, 4, and 7 of the OSI model, there are always requests that it should be tested by Layer 8, which is not within the scope of this blog post.
A couple of years later, we already had a few fully automated data centres. Over that time, we started using CumulusVX + Vagrant for pre-deployment testing. Now, catching bugs faster than the clients can report is the primary goal.
Pre-deployment testing
This is the real-life testing scenario where you virtually build a new data centre almost identical to what you use in production except that the hardware part (ASIC) can’t be simulated (programmed). Everything else can be tested quite well. It also saves hundreds of debugging hours in production, meaning engineers can sleep more :-).
So, when creating a Pull Request on Github, the pre-deployment phase launches a full-scale virtual data centre and runs a variety of unit tests. This includes, of course, some integration tests to see how the switches interact with each other, or simulate other real-life scenarios, for example, connecting a server to EVPN and seeing if two hosts on the same L2VNI can communicate between two separate racks. That takes around 30 minutes. While we don’t push tens of changes every day, it’s good enough.
In addition, we run tests in production devices as well during pre-deployment and in post-deployment phases. This allows us to spot the difference when production was green before the merge and when suddenly something is wrong after the changes.
Known problems can lurk in production for months, and without proper monitoring, you can’t spot them correctly. Or even worse, it can be behaving incorrectly even if you thought it was fine.

To achieve that, we use the Suzieq and PyTest framework for integrating both tools. Suzieq is an open-source multi-vendor network observability platform/application used for planning, designing, monitoring, and troubleshooting networks. It supports all the major routers and bridge vendors used in the data centre.
It has multiple uses, including a network operator-friendly CLI, GUI, REST server, and python API. We primarily leverage the Python API to write our tests. Suzieq normalizes the data across multiple vendors and presents the information in an easy, vendor-neutral format. It allows us to focus on writing tests rather than on gathering the data (and on keeping abreast of vendor-related changes to their network operating systems). We find the developers helpful and the community active, which is very important to get the fixes as fast as possible.
We currently only use Cumulus Linux, but you never know what’s going to be changed in the future, meaning that abstraction is the key.
Below are good examples of checking if EVPN fabric links are properly connected with correct MTU and link speeds.
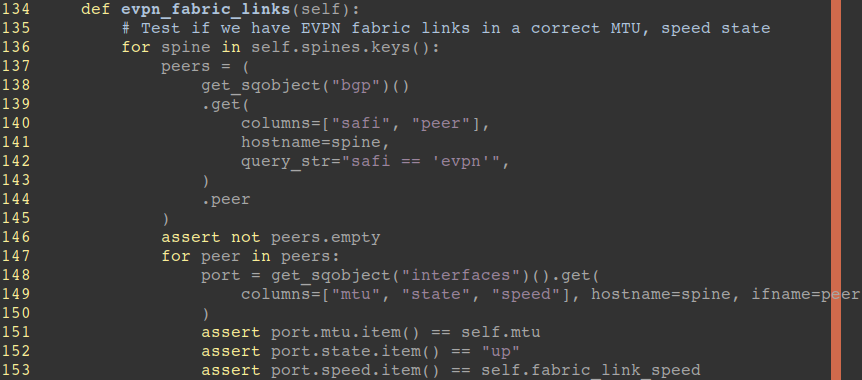
Or, check if the routing table didn’t drop to a less than expected level, and keeps a consistent state between builds. For instance, expect more than 10k routes of IPv4 and IPv6 each per spine switch. Otherwise, you’ll notice some problems in the wild, such as neighbors are down, the wrong filter is applied, or the interface is down.
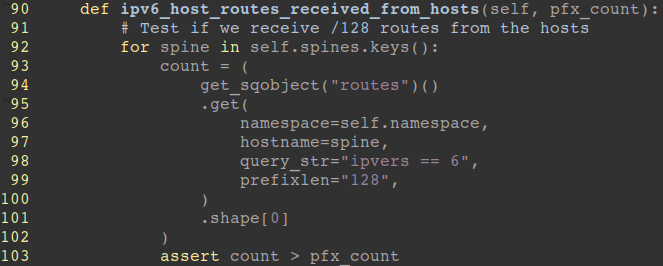
We’ve just started this kind of testing and are looking forward to extending it in the future. Additionally, we run more pre-deployment checks. We use Ansible for pushing changes to the network, and we validate Ansible playbooks, roles, and attributes carefully.
Pre-deployment is crucial, and even during the testing phase, you can realize that you are making wrong decisions, which eventually leads to over-engineering complex disasters. And fixing that later is more than awful. Fundamental things must remain fundamental, like basic arithmetic — add and subtract. You can’t have complex stuff in your head if you want to operate at scale. This is valid for any software engineering and, of course, for networks too.
It’s worth mentioning that we also evaluated Batfish for configuration analysis. But, from what we tested, it wasn’t mature enough for Cumulus Linux, and we just dropped it for better times. Therefore, we will go back to Batfish next year to double-check if everything is fine with our configuration.
Deployment
This is mostly the same as in the initial automation journey. Jenkins pushes changes to production if all pre-deployment validation is green and the Pull Request is merged in the master branch.
To speed up the deployment, we use multiple Jenkins replicas to distribute and split runs between regions to nearby devices. We use an out-of-band (OOB) network that is separated from the main control plane, which allows us to easily change even the most critical parts of the network gear. For resiliency, we keep the OOB network highly-available to avoid a single point of failure and keep it running. This network is even connected to multiple ISPs.
If we lose the OOB network and the core network reachability, that’s probably a data centre issue. Unfortunately, we don’t run console servers or console networks because it’s too expensive and kind of security-critical.
Every Pull Request checks if the Ansible inventory is correctly parsed, the syntax is correct, and runs ansible-lint to comply with standardization. We also rely a lot on Git.
Every commit is strictly validated, and we use additional tags like Deploy-Tags: cumulus_frr that says ‘only run Ansible tasks having this tag’ (Figure 4). It’s here just to explicitly tell what to run instead of everything.
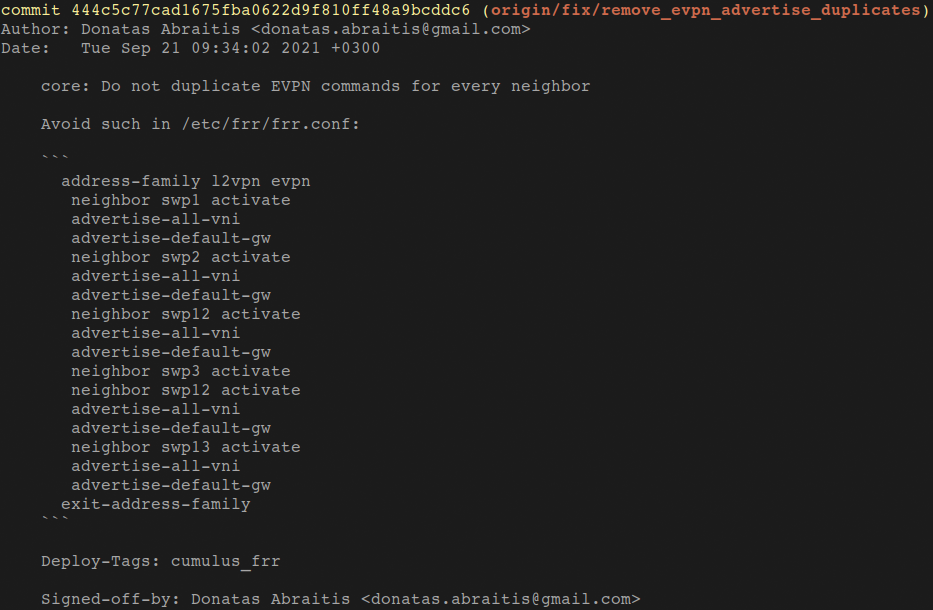
We also have the Deploy-Info: kitchen Git tag, which spawns virtual data centres in a Vagrant environment using the kitchen framework, and you can check the state in the pre-deployment stage. As I mentioned before, Git is the core for reflecting changes that do the test or run for this commit.
Post-deployment
Post-deployment validation is done after deploying changes to the network, to check if they had the intended impact. Errors can make it to the production network, but the duration of their impact is lowered. Hence, when the changes are pushed to the devices, we instantly run the same pre-deployment Suzieq tests to double-check if we have the same desired state of the network.
What did we learn?
We are still learning as it’s a never-ending process. For now, we can more safely push changes to production because we have a layer that gives a bit of trust about the changes being pushed to production.
Adapted from the original post which first appeared on the Hostinger Blog.
Donatas Abraitis is a systems engineer at Hostinger.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.