
Have you tried pairing your bluetooth phone with your smart car recently? How did that go?
Usually it works fine, but sometimes it’s a bit of a chore, right? You have to go into your phone settings and figure out whether the problem is there or with your car; maybe some firmware needs updating, or maybe something’s just broken or incompatible. You don’t always know.
This is a taste of what ‘interop testing’ feels like, as well as an example of why it needs to be done.
‘Interop testing’ (it’s called ‘interop’ testing to cover both interoperability, and inter-operations testing) is how the community ensures that Internet protocols actually cooperate when needed. It can be a tricky business of trial and error. If you’ve ever carefully followed a set of instructions, yet still had frustrating problems occur, don’t feel alone; even the best of us in the Internet community have had that same experience implementing protocols.
The reason for these problems is partly due to a concept I want to explore today — the possibility that you and I could both read the same set of fairly precise instructions correctly, yet still end up doing things differently.
Interop testing is about showing a protocol can be implemented independently
Imagine you want to compete for business, or offer service in an IETF-defined protocol. One of the first things you will do is reach for the RFC that documents it.
This will serve as your set of instructions for how to implement that protocol properly.
There are several things you might expect to see:
- What the protocol is actually for
- The expected states of the systems communicating over the protocol
- How to arrange the ‘bits on the wire’ that actually form the messages of the protocol (that’s what a technical protocol is — definitions of the messages and states)
- Things you must or must not do (this is where ‘normative language‘ comes in, and the use of typeset MUST, MUST NOT, MAY and SHOULD all have narrowly defined meanings and intentions in RFCs).
The problem here is that protocols can be specified in ways that are open to interpretation. Text in the specification might be strongly normative and say you MUST send the username in at most 16 bytes of data but not be clear what to do if there is space-padding in the front or the rear.
This is a problem that troubles almost all complex instructions. You still end up having to rely on certain assumptions. Is “George ” the same as “ George” or not?
Either interpretation may be fine and not really matter, but what does matter is this — are my assumptions the same as yours?
This gets at a key point. Even when you’re explicitly told how to do things, and there’s even a diagram of the bits and bytes in messages, some details can still be unclear.
Consider the ‘states’ of the systems communicating. This is typically dealt with (when it matters) by use of a state-transition diagram, which shows the specific intended sequences of states and transitions between states that the protocol wants to operate in. See Figure 1 below for an example of what these diagrams look like.
This is basically a flow chart, with the states in boxes. It describes what a protocol will do in certain situations.
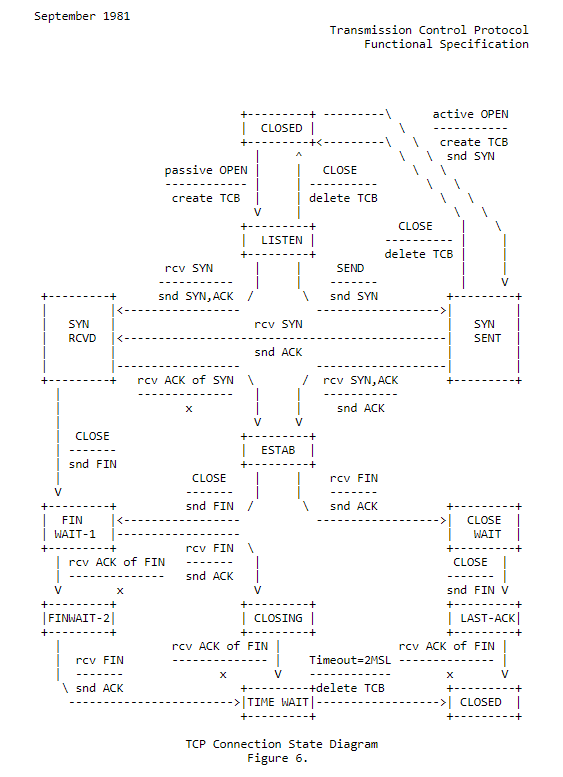
Often the problem with states and transitions between them is that you can wind up being driven into an unexpected state. What happens when something that wasn’t described in the flow chart occurs? How well does the protocol specification deal with the unexpected and what should it do?
One basic mechanism here is to try and test your code from ‘both sides’ of the communication. So unless you are only ever going to be a client in a client-server relationship, it would be normal to implement both sides of the communication and test your own code to see if it works from both those sides.
In reality, you are a client and are expected to talk to a specific server. Or, any server. Or you are a server and must behave exactly like some other person’s server, where specific settings choices have been made (this is typically when the protocol specification has MAY or SHOULD language, or has no normative drivers, and there is a single market dominant implementation that has become a de-facto basis).
This is all well and good if you test your own code from both sides, but what happens when you talk to somebody else’s code?
Typically, and I say this from experience, what happens is not what you expected because people interpret the standard in slightly different ways.
So the intention of an interop test is to show that two (or more) people reading the same standard can actually communicate functionally across the divide of how they independently read and interpreted the standard.
Interop testing is not always capable of showing all of a protocol works as expected
It would be lovely if an interop test confirmed ‘the protocol works’ but the sad reality is, it can sometimes only show that the state does what it should, under just those circumstances.
It is a bit like the formalism around bugs; you can ‘formally verify’ something, but the expense is high, and it often incurs significant performance penalty or design consequences to make it ‘provably correct’.
Interop tests tend to be more informal than that. There may be a specific set of things that are tested, and there may be some formalism about compliance and outcome, but by no means does it mean the protocol under test ‘works’ because there are always bizarre edge cases out there in the wild.
For example, BGP was extensively tested in interop, but it didn’t prevent BGP ‘ghost routes‘ coming to the fore. TCP implementations are widely tested against each other but that didn’t prevent the TCP synchronization effect that caused Van Jacobson to do work on random timing in TCP backoff.
What interop testing can do is show everyone is implementing the behaviour of the protocol in similar ways. Or, expose the variances between them.
This leads to my next point, which is that the implementation, as instructed in a standard, isn’t always what ends up defining the protocol.
There are the instructions, then there’s what people actually end up doing that works, and sometimes, they don’t always occur in the same order.
First isn’t always best, even though they often think they are
It is possible a group of people come together and say “this implementation is now the definition for what we expect on-the-wire” or say “you must implement the protocol to be compatible with…”. But this isn’t a requirement for interop, and it may well be a distortion of the process if you do it.
There is a strong first-to-file quality to the first implementation people can see, and if it’s freely available then it takes on a certain ‘moral force’ as others follow the more well-worn path. But this isn’t necessarily a good habit of ours. The first implementation is equally likely as others to have made bad, uncertain, or unexpected interpretations of the protocol and specification.
It would be a serious mistake to enshrine the first to implement as the ‘right’ way to follow the instructions, without some deliberation.
That said, there is certainly a tendency for the first on the ground to assume if the next one differs, then they are the one that has to change. I’ve seen this in action. It is understandable, but unless clearly defined coming into the room, it’s wrong.
Interop tests are not about ensuring a free implementation exists
Many people assume the IETF is for free code. This is a big, serious mistake. The IETF is for open, freely available specifications of protocols, but the implementations of those protocols is not required to be free. In fact, interop simply wouldn’t have come to the fore, if the requirement was ‘there must be a free one’ and the vendors of proprietary routing code (Cisco, Juniper, Ericsson, and Huawei) made a point of treating interop as a chance to bring their proprietary, asset-rich code into a ‘safe space’ where they can test the behaviour, without risking the intellectual property.
I like free code. I like free implementations. I note that even the ‘free’ stuff has a cost of production and maintenance and so this stuff does often wind up incurring cost, as I discussed in a recent post on validator features. The word ‘free’ takes on special meanings when we want to say ‘freely available’ or ‘unencumbered’ with licensing rights. The point here is that none of the requirements of an interop include they must be free.
Interop tests are not about public naming and shaming
As noted above, interop isn’t just an IETF thing; it actually has existed outside of the IETF and outside of public view for some time. Outside of the IETF, many telcos establish ‘bake-off rooms’ or ‘test labs’ where they invite vendors to bring equipment and show how it works in production. For years, to get regulatory compliance for deployment in Australia, you needed to let Telecom Australia (and the GPO before that, and Telstra after) test your device for its safety and compliance to get a green tick mark that indicated it was legal to connect to the regulated monopoly network. At no time in this was ‘free’ a part of the story.
The only consideration was — does it work properly and safely?
The key point for these vendors is that they can do this test to show they can succeed in deploying the product at scale. Sometimes that means accepting that there is, in fact, a problem and it’s just the first step. But if the risk of an interop is that you get publicly shamed, it’s highly likely you won’t turn up. The PR consequences outweigh being technically correct for some people (shareholders included).
So, an important quality of interop is that it’s mutual and respectful. You can’t test that everything works properly if the people bringing the protocols are too afraid to show up.
Interop tests are not testbeds or pilot deployments
It is tempting to draw a comparison between interop, and running a public pilot or testbed. And indeed, you can use a public pilot, testbed or a virtual overlay as a vehicle to do interop testing, but that’s what you are doing — you’re using a public pilot to do the interop test. It isn’t necessary, and the problem with confusing the two, is that a public pilot can imply public service, and public packet delivery consequences you didn’t mean.
Pilot projects have a habit of becoming service projects very quickly. So, a wise choice here may be to say: “We could do interop testing in that that pilot test, but we won’t unless there is some compelling strong reason to do this. We’ll do interop, and we’ll do a pilot deployment afterward.”
Interop tests work, and are worth doing
It should be obvious from this that I believe in the utility of interop testing. But it’s important to understand their role, and what they can do for you. Interop testing gives you confidence that the protocol has been seen to work between two or more independent implementations. It helps reduce confusion, identify disagreements in meaning in the specification, and can clarify conflicting normative requirements, or the lack of practicability.
It’s a high value exercise. We need more of it!
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.