
Last year, the summer after my sophomore year of high school, I was in quarantine with some time on my hands and wanted to learn something new. I had been interested in networking for a while and was curious about how content delivery worked at scale; especially this concept of anycast, which seems to be a topic of debate. So, in August of 2020, I decided to build my own anycast Content Delivery Network (CDN) from scratch.
My primary goal was to learn new things, but at the same time, I wanted to build a system that I could actually use in production to demonstrate that it works as intended. To meet that goal I decided to start with DNS due to its relative simplicity and that (most of the time) it uses User Datagram Protocol (UDP) so state synchronization isn’t a problem.
I knew from the start that I wanted to play with anycast. I already had an ASN (AS34553) and a few IP address blocks from other projects, so I chose a /24 and /48 to use for the CDN. The first step was to set up a few Virtual Machines (VMs) to act as DNS servers and try announcing the same prefixes from all of them. I set up three Debian VMs (each in a different physical location), installed BIRD for BGP and BIND for DNS, and in a few hours of work and a couple of hundred lines of Ansible playbooks, had a little anycast DNS cluster up and running. It was neat to see anycast working firsthand, and I had fun withdrawing routes on one of the nodes to see how fast routers would converge and fail over to the other nodes in the network. I wrote about this first step in the project in a blog post.
While the network was a great first test, DNS updates were made by manually editing a zone file and it certainly wasn’t very scalable; so it was time for a real control plane. The design was based around a Flask API, MongoDB database, and BeanstalkD as a message queue. Updates come in through the API and are stored in the database, then a message is added to Beanstalk that signals a second Python process to deploy the new zone file to each anycast node over SCP and SSH for control signals. Originally the anycast nodes ran their own RPC API, but I ended up switching to JSON blobs over SSH to keep the controller-to-node interaction as simple as possible. I also added user authentication to the API and opened it up to a few friends to host their personal domains on the network. I wrote a second blog post that covered the new control plane.
At this point, I had a functional CDN, but with the obvious limitation of being a CDN that only does DNS, so I felt it was time to add a new service — HTTP caching. DNS isn’t exactly a simple protocol, but it is certainly a whole lot simpler to manage than HTTP(s). One of the biggest challenges was dealing with Transport Layer Security (TLS) certificates for HTTPS (an expectation rather than a feature like it used to be). Because the network is anycast, there was no guarantee that the node originating the certificate request would be the same one answering the validation challenge. My first implementation of an automated TLS certificate process was using the HTTP-01 ACME challenge with Let’s Encrypt. It would first initiate the certificate request from the control plane, then receive the challenge, deploy the answer, wait for it to be deployed on all edge nodes, let Let’s Encrypt know that the challenge is ready, wait for a response, and then clean everything up. This was not a simple process and required repeated bidirectional communication between the control plane, anycast nodes, and Let’s Encrypt, resulting in a bit of a complicated mess.
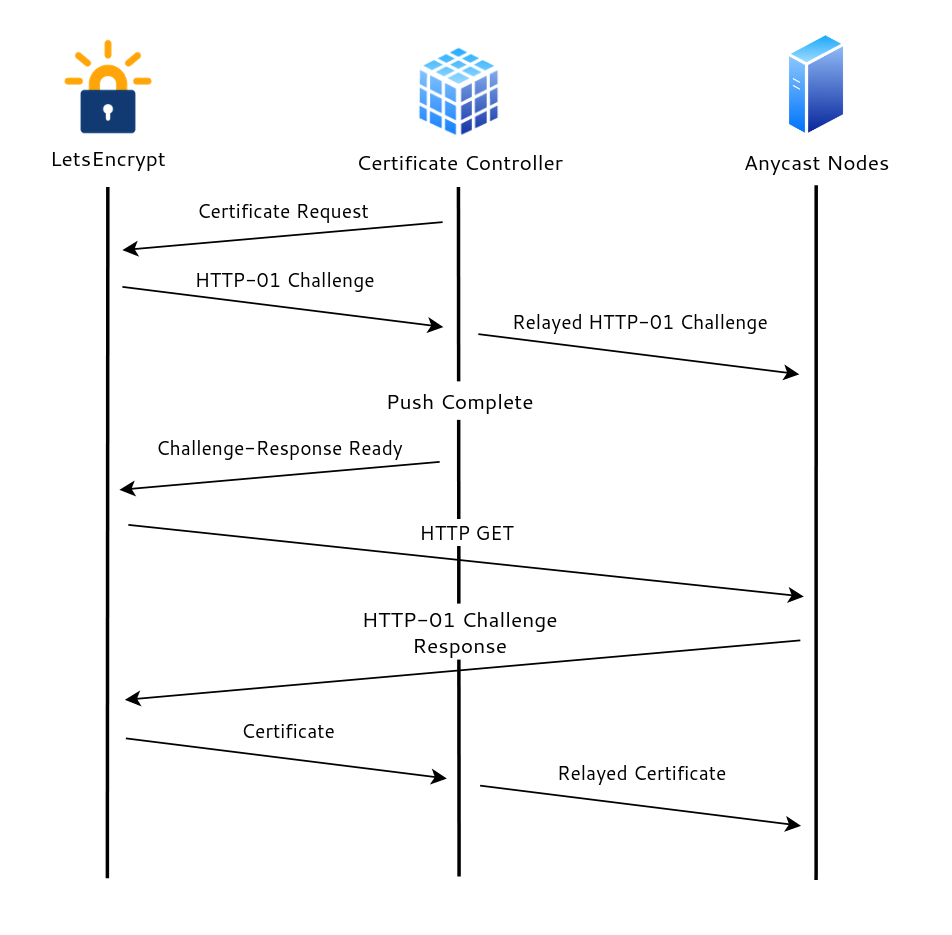
I was reading the Let’s Encrypt documentation one night when I realized that there was a DNS-based ACME challenge as well, so I promptly threw away all this code and wrote a few lines to call my own DNS API endpoints to handle certificate interactions.
The HTTP caches were built with Varnish for caching and Caddy as a proxy and communicated with the same control plane that managed DNS. I also built a dashboard with Svelte to manage DNS records and HTTP caching proxy settings for your domains. The project was really starting to take shape!
My next focus was on the infrastructure side. Most of the PoPs were either a single bare metal server or a VM. This worked fine, but I really wanted to experiment with designing a larger PoP. For this, I spun up four VMs on a hypervisor with a pair of BGP sessions (v4 and v6) on each, peered with that site’s core router. I then enabled ECMP on the received routes and, just like that, had a simple stateless load balancer that worked quite well to distribute queries among the VMs:
~ ▴ for i in {1..10}; do dig +short TXT id.server CHAOS @ns1.packetframe.com ; done | xargs
fmt fmt4 fmt fmt fmt2 fmt3 fmt3 fmt2 fmt3 fmt4
Load balancing with Anycast+ECMP in action.
As the network grew so did the number of BGP sessions. I had been using the same Ansible playbook for automating BIRD configs from the very start, and it was starting to become tedious to handle all the different peering environments while maintaining strict filters on all sessions. To solve my BGP automation problem, I wrote a utility in Go called the ‘BIRD Configuration Generator’ or ‘BCG’ for short. BCG reads a simple config file (YAML, TOML, or JSON) and outputs BIRD configuration files with filters for RPKI, IRR, and max-prefix limits, all pulled automatically from the network’s PeeringDB page. The project is open source on GitHub if you’d like to try it out yourself.
As in any network, it’s important to understand how the system is operating. For monitoring I used a combination of three tools:
- A route collector with multihop iBGP feeds from every anycast node to provide a central interface to examine which routes are being received at each location, as well as looking at attributes like communities for traffic engineering.
- Prometheus and Grafana polling metrics from each node such as resource/bandwidth usage, BGP session status, as well as stats from BIND, Caddy, and Varnish to get an idea of what level of traffic the nodes are actually serving.
- Community tools such as the NLNOG RING and RIPE Atlas made tuning anycast announcements much easier because I could quickly run queries from all over the world to see where there might be ‘scenic routes’ taking users to a faraway anycast node.
Tuning the anycast network was mostly a matter of prepending and export control through upstream communities, as well as carefully selecting which routes to send to IXP peers. I also wrote a utility to ping from multiple source IPs and display the results in an easy-to-read table, which helped when optimizing routes from multiple upstream providers based on latency and packet loss. This is also open source on GitHub.
~ » sudo stping -s "2001:xxx:x:xxx::2,2a04:xxxx:x:xxxx::4" -t "example.com"
Resolving example.com...2606:2800:220:1:248:1893:25c8:1946, 93.184.216.34
STPING example.com (2606:2800:220:1:248:1893:25c8:1946) from 2 sources:
Source Sent Loss Min Max Avg Dev
2001:xxx:x:xxx::2 1 0.00% 952µs 952µs 952µs 0s
2a04:xxxx:x:xxxx::4 1 0.00% 1.055ms 1.055ms 1.055ms 0s
2001:xxx:x:xxx::2 2 0.00% 910µs 952µs 931µs 21µs
2a04:xxxx:x:xxxx::4 2 0.00% 1.019ms 1.055ms 1.037ms 18µs
2001:xxx:x:xxx::2 3 0.00% 860µs 952µs 907µs 37µs 2a04:xxxx:x:xxxx::4 3 0.00% 1.007ms 1.055ms 1.027ms 20µs
^C
--- 2606:2800:220:1:248:1893:25c8:1946 stping statistics source 2001:xxx:x:xxx::2 ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max/stddev = 860.441µs/936.173µs/1.020808ms/58.819µs
--- 2606:2800:220:1:248:1893:25c8:1946 stping statistics source 2a04:xxxx:x:xxxx::4 ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max/stddev = 925.494µs/1.00201ms/1.055702ms/47.595µs
Output from stping showing latency and packet loss from multiple transit providers.
Currently, I’m working on a complete rewrite of the control plane, this time using Go and adding new features such as DNSSEC support and custom caching policy. It will also be deployed in a HA configuration on an anycast container service that I also built for the network.
If you’re interested in my CDN or anycast in general, check out my talk at NANOG 81 where I discussed this project in more detail, or watch the embedded video below. You can also find me on GitHub.
Nate Sales is a student and software developer with a focus on infrastructure and security.
Discuss on Hacker NewsThe views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Hi, which is the minimum amounts of ips that u need for this project, and for example where you buy it? THX very useful info.