

Today, networking infrastructure is designed to deliver software ‘quickly’, ranging from a few seconds to hours.
Ideally, every developer would like to update their infrastructure instantaneously: a developer snaps their fingers, Thanos-style, and the infrastructure gets magically updated with the new code binaries and configurations. Unfortunately, the complex nature of today’s production environment makes this a highly challenging task, that is, unless the developer has the Infinity Gauntlet lying around in their garage!
The infrastructure of online service providers like Facebook consists of millions of application and edge servers. To deploy updates (new binaries or configurations), restarting these globally distributed components is required.
However, restarting these components can lead to breaking user connections and losing their corresponding application state. Given the high frequency and continuous release of updates — up to tens of times a day for Facebook’s application servers — you start to understand the size and challenge of this task.
A recent SIGCOMM paper from Facebook, in collaboration with Brown University, demystifies how Facebook addresses this challenge and tackles the question of “how to frequently update the globally-distributed infrastructure in a manner that doesn’t disrupt user connections and has no associated downtime?”
In this post, I’ll discuss a framework and mechanism we proposed as part of the study and how these fared in testing.
Zero Downtime Release
The ‘Zero Downtime Release’ framework we proposed in our paper ensures infrastructure robustness and disruption-free experience for the diverse services and protocols (HTTP, QUIC, MQTT) during software updates.
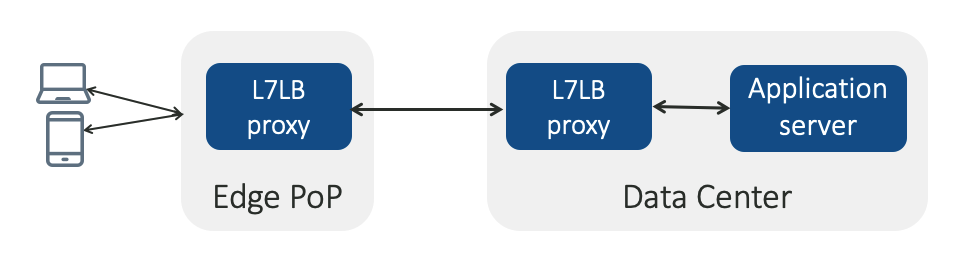
Facebook’s infrastructure employs two-tiers of layer-7 load-balancing proxies, called Proxygen. Each tier load balances the user requests across its upstream (as shown in Figure 1): proxies at an Edge PoP (point-of-presence) terminate user connections and forward the request to the upstream data centre, while proxies at data centres forward the requests to the corresponding application servers.
Read: When the Internet goes down: improving the detection of disruptions
Leveraging the layered architecture and the end-to-end control, the Zero Downtime Release framework introduces novel signalling and connection hand-off mechanisms through which a restarting component can shield the users from disruptions while maximizing their ability to keep serving traffic to ensure zero downtime.
At a high level, infrastructure must possess the following fundamental properties to ensure seamless updates:
- First, a machine that hosts a proxy/server application must keep serving traffic when the application is restarting; otherwise, the machine will be unable to process any new traffic during the restart and ‘downtime’ will be observed.
- Second, restarting a proxy/server instance should be able to migrate its connection or application state to another healthy instance, otherwise the state would be lost and would require the user to retry, thereby falling short of achieving ‘no disruption’.
Eliminating proxy downtime
A ‘socket takeover’ mechanism, through which a parallel proxy instance (with the updated code/configurations) is spawned and assumes the control of serving new connections, can assist with achieving these. The older instance keeps serving existing connections, and shuts down when an operator-specified duration is elapsed.
While the high-level procedure may appear straightforward, the support for seamless socket takeover in diverse protocols like TCP, UDP, and QUIC at Facebook’s scale, makes it challenging.
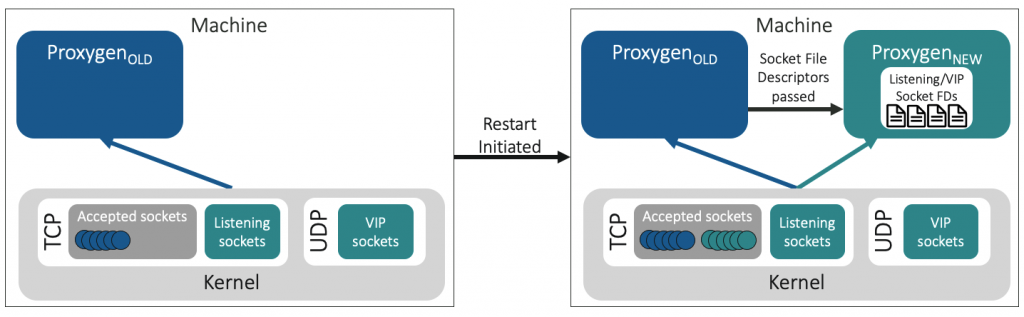
While TCP provides the construct of ‘listening sockets’ that the new instance can take over, thereby taking over the job of serving new connections, UDP-based protocols lack any such notion due to their ‘connection-less’ nature. The application itself is responsible for setting up sockets for receiving UDP packets, as well as keeping their connection state.
Similar to the TCP case, a direct solution is to just take over these UDP sockets, however, this leads to conflicts with respect to the connection state.
For TCP, the kernel maintains the connection state and can distinguish between packets for new versus older connections (based on the proxy instance that accepted the connections).
For UDP/QUIC, packets for both new and older connections make their way to the updated instance (that now owns the sockets) and, since this instance lacks the state for older connections, leads to terminating these misrouted connections. To remedy this problem, the ‘socket takeover’ mechanism employs user-space packet forwarding to route the packets to the instance with the right connection state.
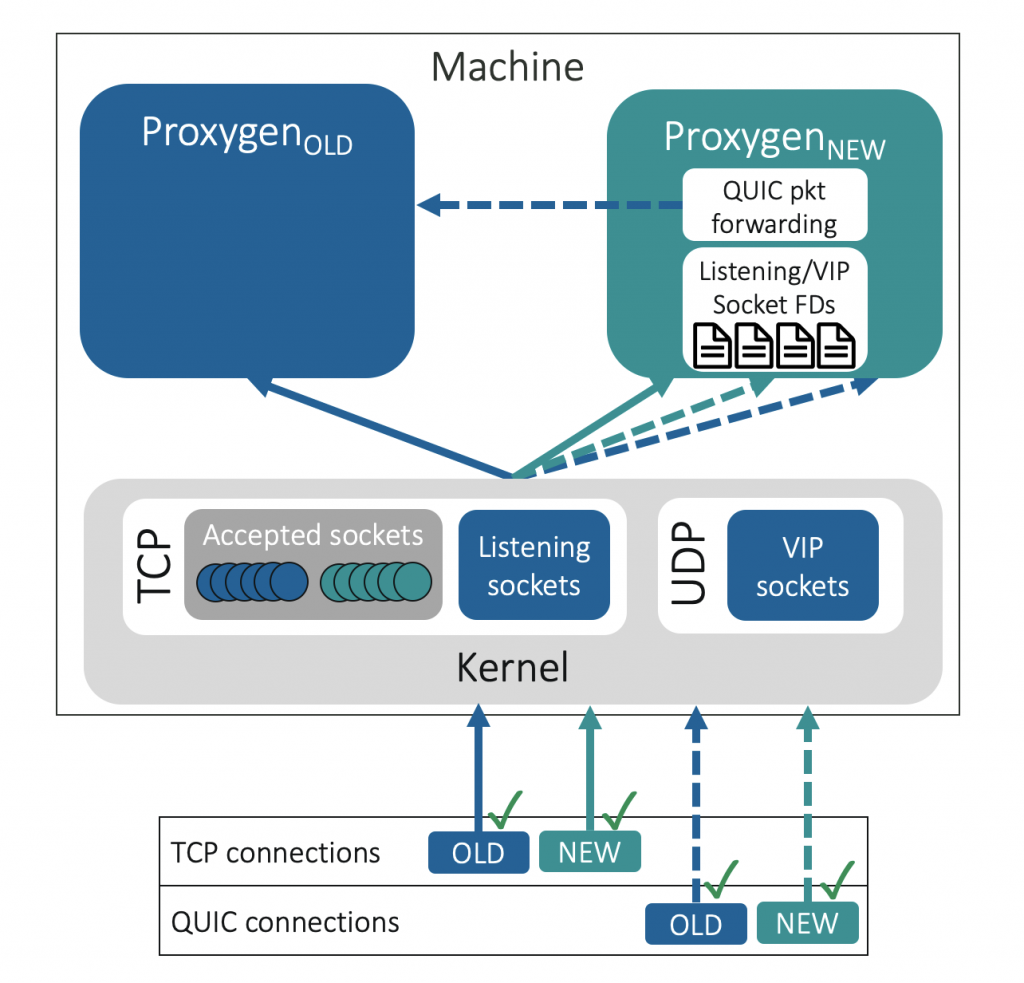
In our paper, we further discussed a number of technical contributions in the kernel and application space that make a seamless takeover possible at scale.
Ensuring zero disruptions for long-lived connections
Though socket takeover ensures zero downtime and no disruption for short-lived connections (by concluding or gracefully closing them during the draining period), long-lived connections may outlive the draining period and terminate when the older instance terminates. This is critical for certain classes of services, like Facebook Messenger, that keep long-lived, persistent connections to the backends using the MQTT protocol.
On the application server side, the restarts are similarly critical to long-lived transactions, like uploads. Our paper introduces the following two mechanisms to address these disruptions:
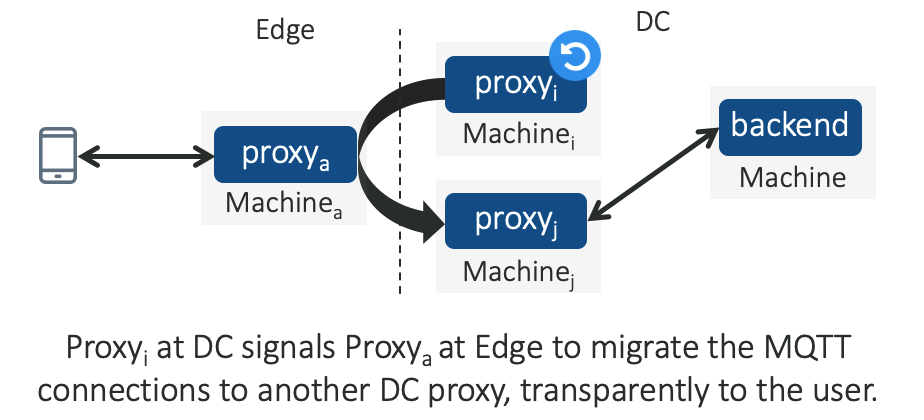
- Downstream Connection Reuse allows a restarting proxy to hand over the MQTT connections to another healthy proxy in the cluster. The restarting proxy signals its intent to restart to a downstream proxy, that in turn, looks up another healthy upstream proxy and migrates the connection.
- Partial Post Replay, allows a restarting server to migrate the upload request’s state to another healthy server. The server replays the incomplete state to a downstream proxy, and the proxy, in turn, recreates the original request using the received state and replays the request to another upstream server.
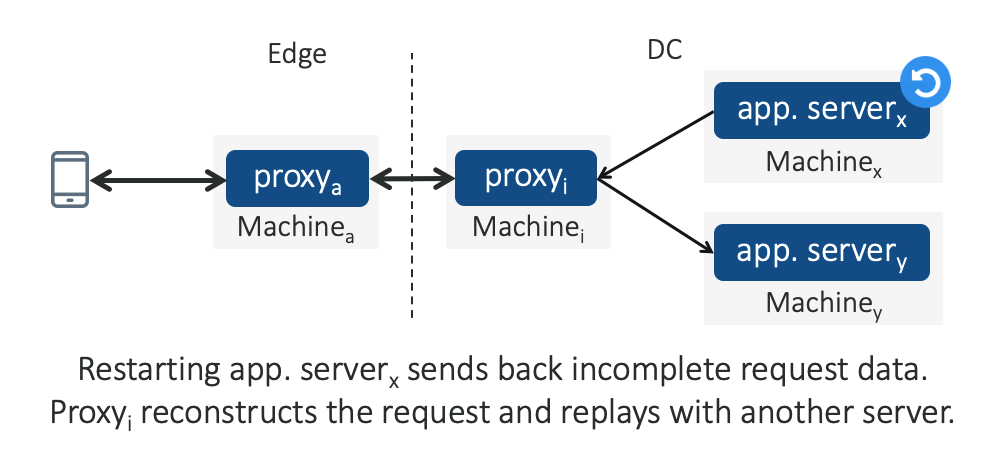
Both the connection and state hand over are completely transparent to the end users and save the users from constant re-tries over high-RTT WAN.
Impact at scale and operational aspects of these mechanisms
The Zero Downtime Release framework has proven to be indispensable at Facebook for maintaining quick rollouts throughout the day, any day of the week, without any scheduling constraints. Our paper further discusses a number of best practices learnt through experience over the years, and multiple war stories where Zero Downtime Release led to counterintuitive scenarios.
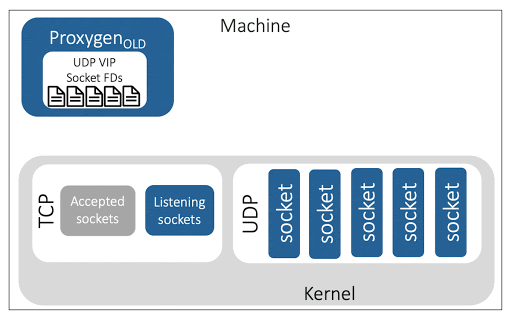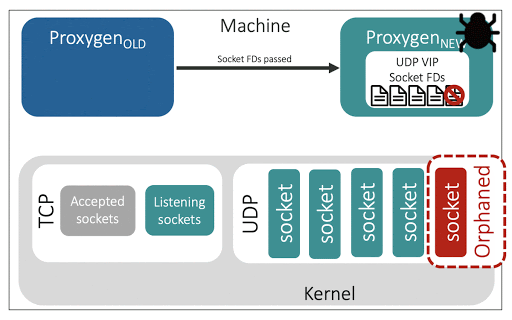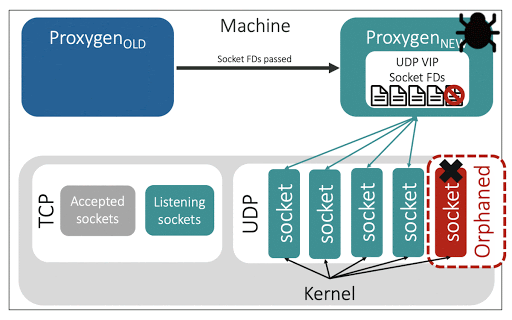
A pitfall of socket takeover is that it introduces the possibility of leaking sockets and their associated resources.
In one instance, a faulty release led to compatibility issues between the two proxy instances at socket takeover, and the updated instance was expecting a smaller number of sockets than the one owned by the older instance. The updated instance ignored these excess sockets and led to a scenario where a set of ‘orphaned sockets’ were functioning in the kernel’s view but the proxy application was no longer reading from them. This led to timeouts for the orphaned connections, and the situation was hard to debug due to the non-determinism aspect — only connections for the orphaned sockets faced timeouts while the rest worked as normal.
One recommendation to tackle these issues involves strictly monitoring the sockets within the system and identifying a set of key metrics to inspect.
A number of components discussed in the paper are open-source — L7 load-balancer (Proxygen), L4 load-balancer (Katran), Facebook QUIC (mvfast), application server (HHVM), and Partial Post Replay (IETF draft). Please refer to our paper and a video recording of a presentation we gave at SIGCOMM 2020 for more details.
Usama Naseer is a PhD candidate at Brown University. His research interests lie in improving web performance, network configuration tuning and Internet measurements. You can reach him at usama_naseer@brown.edu.
This is a joint work with Luca Niccolini, Udip Pant, Alan Frindell and Ranjeeth Dasineni from Facebook, and Theophilus A. Benson from Brown University.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.