
Over the last 50 years, we’ve made a lot of progress in developing the Internet from a tiny interconnection of a handful of computers to a worldwide fabric with billions of nodes. During that journey, we’ve learned an enormous amount about how to build networks and the routers that interconnect them. The mistakes that we all made generated some important lessons along the way, for those who chose to learn them.
In the beginning, routers were simply generic computers, with Network Interface Cards (NICs) attached to a bus.

This works to a point. In this architecture, packets enter a NIC and are transferred by the CPU from the NIC into memory. The CPU makes a forwarding decision and then pushes the packet out to the outbound NIC. The CPU and memory are centralized resources, bound by what they can support. The bus is an additional limitation: the bandwidth of the bus must be able to support the bandwidth of all of the NICs simultaneously.
If you want to scale this up, problems quickly become apparent. You can buy a faster CPU, but how do you scale up the bus? If you double the speed of the bus, then you must double the speed of the bus interface on every NIC and the CPU card. That makes all of the cards more expensive, even if an individual NIC isn’t somehow more capable.
Lesson 1: The costs of a router should scale linearly with capacity
Despite this lesson, the expedient solution to scaling was to add another bus and another processor:
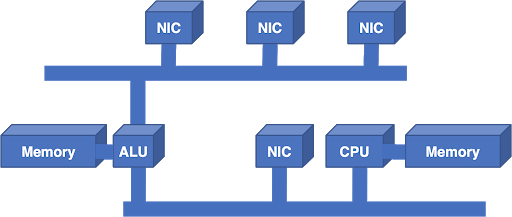
The additional Arithmetic Logic Unit (ALU) was a Digital Signal Processing (DSP) chip, chosen because of its excellent price-performance ratio. The additional bus added bandwidth, but the architecture still didn’t scale. In other words, you couldn’t keep adding more ALUs and more buses to get more performance.
Since the ALU was still a significant limitation, the next step was to add a Field Programmable Gate Array (FPGA) to the architecture to offload the Longest Prefix Match (LPM) lookup.
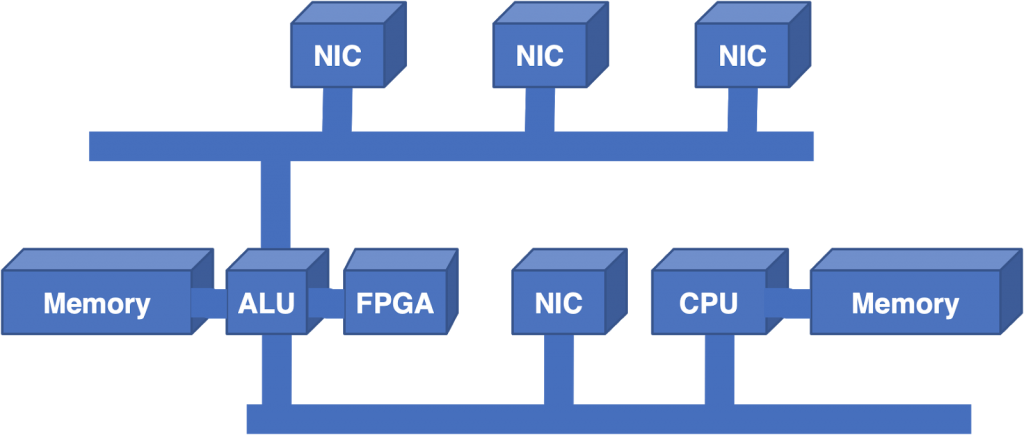
While this helped, it was surprising that it didn’t help more. The ALU was still saturated. LPM was a big portion of the workload, but the centralized architecture still didn’t scale if you took away that part of the problem.
Lesson 2: LPM can be implemented in custom silicon and is not a roadblock for performance
Despite this lesson, the next step was to go in the other direction: replace the ALU and FPGA with a generic processor. Try to scale by adding more CPUs and more buses. This required a great deal of effort for a small incremental gain and was still limited by the centralized bus bandwidth.
At this point in the evolution of the Internet, bigger forces came into play. As the web took off in popular imagination, the vast potential of the Internet became increasingly apparent. Telcos acquired the NSFnet regional networks and began deploying commercial backbones. Application-Specific Integrated Circuits (ASICs) became credible technologies, allowing more functionality to be implemented directly in silicon. Demand for routers skyrocketed, and the demand for drastic scalability improvements finally overwhelmed engineering conservatism. Numerous startups sprang forth to meet this demand, with a variety of potential solutions.
One alternative was a scheduled crossbar:
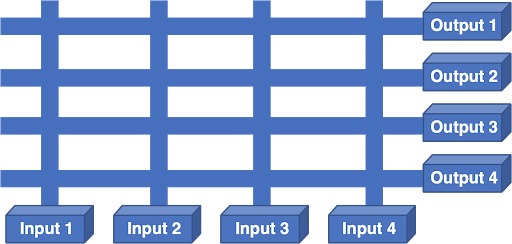
In this architecture, each NIC is an input and an output. A processor on the NIC made the forwarding decision, selected the output NIC and sent a scheduling request for the crossbar. The scheduler took all of the requests from the NICs, tried to figure out an optimal solution, programmed the crossbar with its solution, and cued the inputs to transmit.
The problem with this is that each output could only listen to a single input at a time and Internet traffic is bursty. If two packets needed to go to the same output, one of them had to wait. If the packet that has to wait causes other packets on that same input to wait, then the system will suffer from Head Of Line Blocking (HOLB), resulting in very poor router performance.
Lesson 3: A router’s internal fabric needs to be non-blocking even under stressful conditions
The migration to custom silicon also encouraged designers to migrate to cell-based internal fabrics, as implementing switching of small, fixed-size cells was much easier than dealing with variable length, sometimes large packets. But switching cells also means the scheduler had to run at a higher, per-cell rate, making scheduling that much harder.
Another innovative approach was to arrange the NICs in a torus:
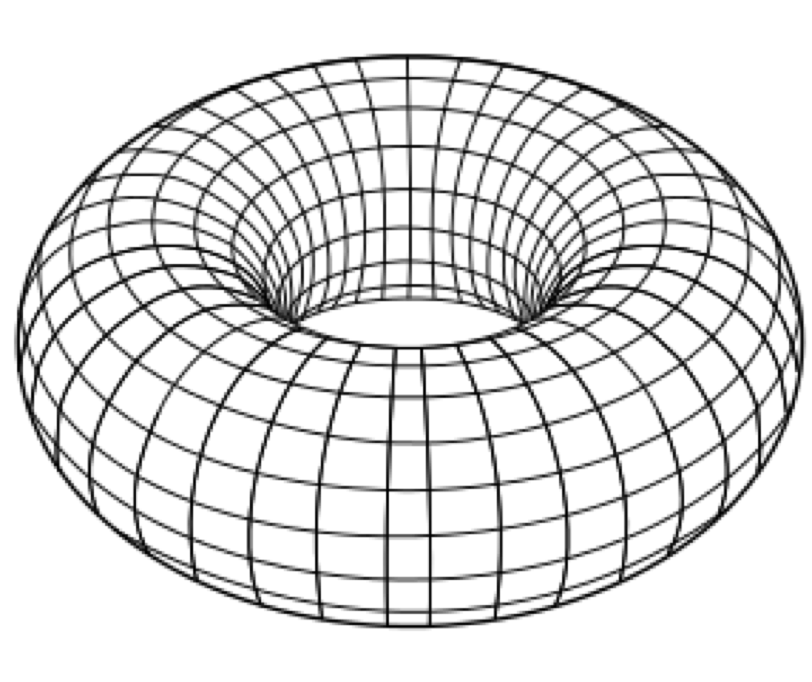
Here, each NIC had links to four neighbours, and the input NIC had to compute a path across the fabric to reach the output line card. This had issues — the bandwidth was not uniform. There was more bandwidth in the north-south direction than there was in the east-west direction. If the input traffic pattern needed to go east-west, congestion ensued.
Lesson 4: A router’s internal fabric must have uniform bandwidth distribution because we can’t anticipate the distribution of traffic
A very different approach was to create a full-mesh of NIC to NIC links and distribute cells across all of the NICs:
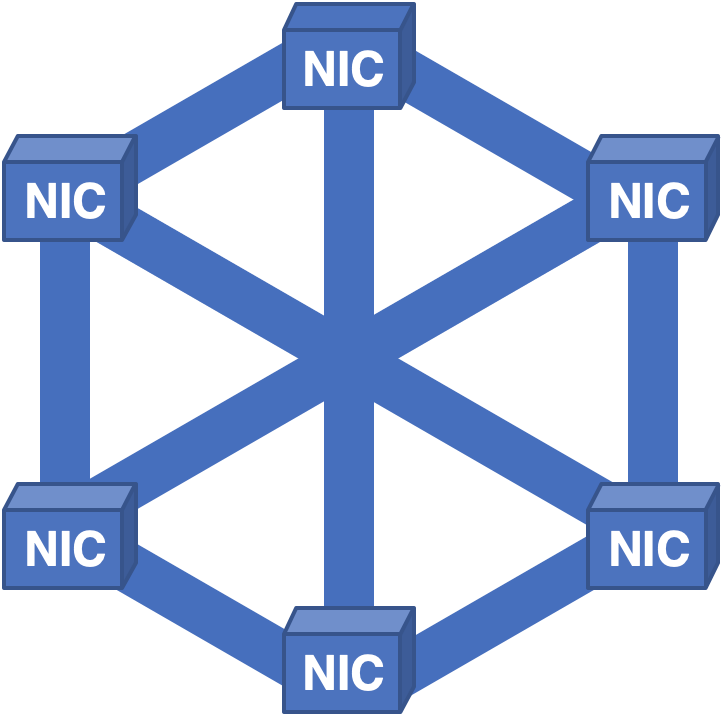
Despite previous lessons learned, new issues came to light. In this architecture, everything worked reasonably well until someone needed to replace a card for repair. Since each NIC held cells for all of the packets in the system, when a card was pulled, none of the packets could be reconstructed, resulting in a brief but painful outage.
Lesson 5: Routers must not have a single point of failure
We even took this architecture and stood it on its head:
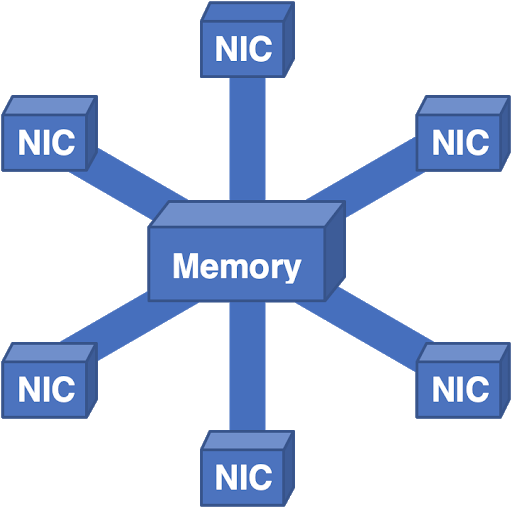
Here, all packets flow into a central memory and then flow out to the output NIC. This worked fairly well, but scaling the memory is a challenge. You can add multiple memory controllers and memory banks, but at some point, the aggregate bandwidth is simply too much to physically engineer. Running into the practical physical limits forced us to think in other directions.
We found inspiration in the telephone network. Charles Clos long ago realized that scalable switches could be built by constructing networks of smaller switches. It turns out that all of the wonderful properties that we needed were all present in a Clos network:
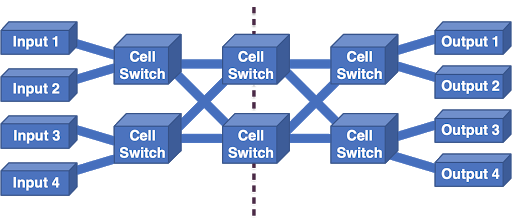
A Clos network:
- Scales nicely with capacity.
- Has no single point of failure.
- Supports enough redundancy that we have resilience against failures.
- Handles bursts of congestion by distributing the load across the entire fabric.
We always implement inputs and outputs together, so we normally fold this picture on the dotted line. This produces the folded Clos network, which is what we use in multi-chassis routers today, with some chassis full of NICs and a layer of switches, and more chassis with additional layers of switches.
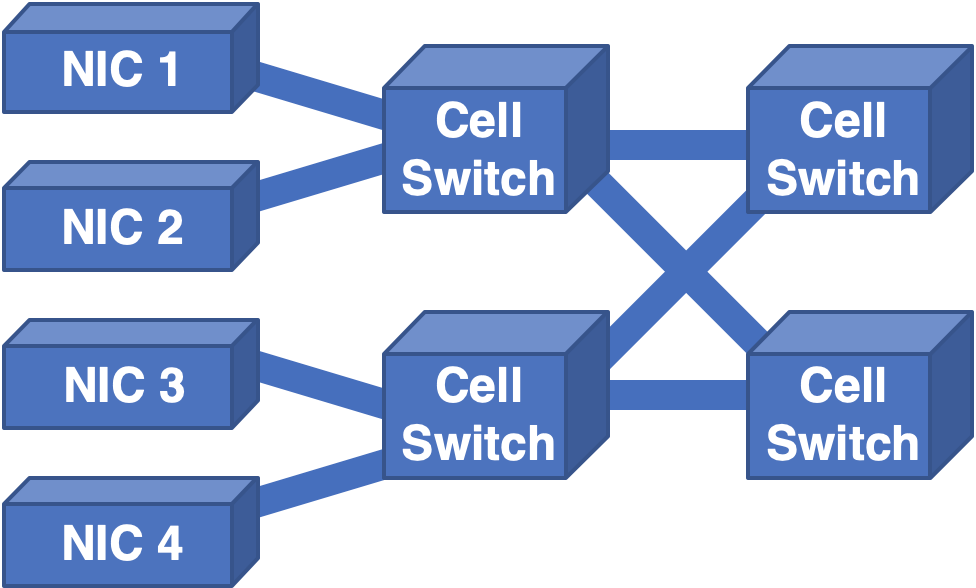
Unfortunately, even this architecture is not without issues. The cell format used between the switches is proprietary to the chip vendor, resulting in chipset lock-in. Being tied to a chip vendor is no better than being tied to a single router vendor, with similar issues of single-source pricing and availability. Hardware upgrades are challenging since a new cell switch must simultaneously support the legacy links and cell format to interoperate as well as any upgrade link speeds and cell formats.
Each cell must have addressing that indicates the output NIC to which it should flow. That addressing is necessarily finite, resulting in an upper bound on scalability. Control and management of a multi-chassis have, to date, been completely proprietary, creating another single-vendor issue for the software stack.
Fortunately, we can address these issues by changing our architectural philosophy. For the last 50 years, we have been striving to scale up our routers. What we have learned from our experiences in building large clouds is that the scale-out philosophy is frequently more successful.
In a scale-out architecture, instead of trying to build a gigantic, extremely fast single server, why not divide and conquer? A rack full of smaller servers can do the same job, while also being more resilient, flexible, and economical.
When applied to routers, the thinking is similar. Can we take some smaller routers and arrange them in a Clos topology so that we have similar architectural benefits, but avoid the cell-based issues? It turns out to be not overly difficult:
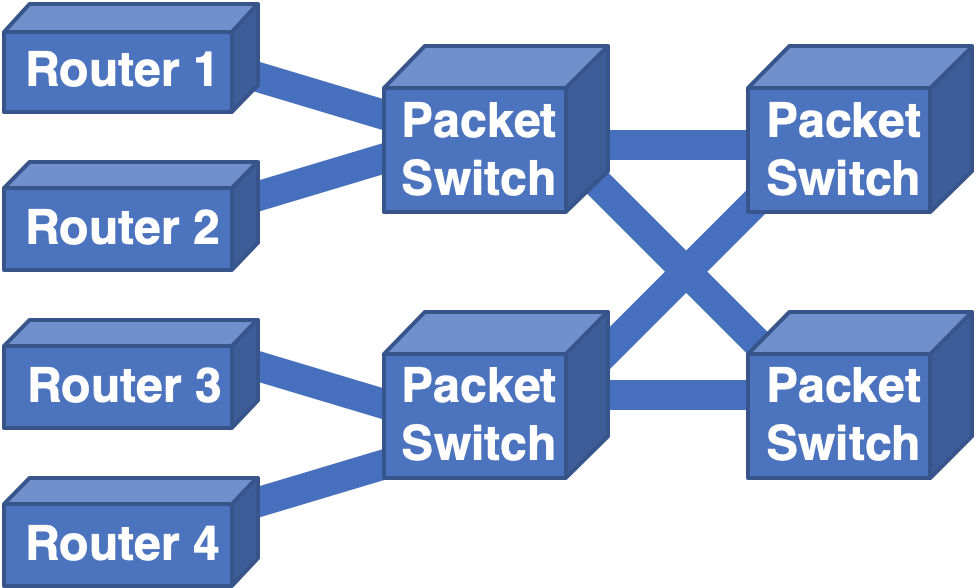
By replacing cell switches with packet switches, such as routers, and retaining the Clos topology, we ensure that we have easy scalability.
We can scale in two dimensions: either by adding more entry routers and packet switches in parallel with the existing layers or by adding additional layers of switches. Since the individual routers are now relatively generic, vendor-lock is avoided. The links are all standard Ethernet, so there is no issue with interoperability.
Upgrades are direct and straightforward: if more links are needed on a switch, then swap in a bigger switch. If a given link needs to be upgraded and both ends of the link are capable, then it’s a matter of simply upgrading the optics. Running heterogeneous link speeds within the fabric is a non-issue as each router acts as a speed-matching device.
This architecture is common already in the data centre world, and is known as a leaf-spine or super-spine architecture, depending on the number of layers of switches. It has proven to be very robust, stable, and flexible.
From a forwarding plane perspective, it’s clear that this is a viable alternative architecture. The issues that remain are for the control plane and management plane. Scaling out the control plane requires an order of magnitude improvement in the scale of our control protocols. We seek to achieve that by improving our abstraction mechanisms by creating a proxy representation of the architecture, representing the entire topology as a single node.
Similarly, we are working on developing management plane abstractions that allow us to control the entire Clos fabric as a single router. This work is being done as an open standard, so none of the technology involved is proprietary.
Over the last 50 years, router architectures have evolved in fits and starts, with many missteps, as we navigated the trade-offs between technologies. It is clear that our evolution is not yet complete. With each iteration, we have addressed the issues of the previous generation and discovered a new set of concerns.
Hopefully, by careful consideration of our past and present experiences, we can move forward with a more flexible and robust architecture, and make future improvements without forklift upgrades.
Tony Li has been a pioneer in Internet routing for 30 years, helping to scale the Internet architecture and leading the deployment of BGP and CIDR.
Discuss on Hacker NewsThe views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
figure 6 is not a full mesh
Hi Tony,
I think APNIC picked well when choosing an author for this subject. Akin to the BBC choosing Sir David Attenborough to cover natural history 🙂
It would be great if you could plot a rough timeline or even better your own personal journey along this path?
Or you could always write a book, which I would happily pay for.
Mark
P.s. Include the SW innovations and you’ve got an Attenborough level best seller, at least from the Natural Networking History community 😉
Nice project
Very good
Thanks
excellent
Good
Good
Super