

The journey of an HTTP message is arduous.
Every request may traverse massive content delivery networks, cloud platforms, packet inspectors, load balancers, and countless other proxies sprinkled along the path to their destination. On the way back, web caches store suitable responses for serving subsequent requests, short-cutting the journey. This complex ecosystem of proxies and web caches is key to enabling scalable communications over the Internet.
Components of this system need to parse, understand, and sometimes transform HTTP messages before they pass the packet along. However, such distributed technologies developed and deployed by diffused parties can’t easily operate within identical HTTP processing semantics. Trivial discrepancies in the interpretation of a message can quickly snowball into security issues, often exposing web cache vulnerabilities.
In an effort to further our understanding of the impact of such vulnerabilities, in particular Web Cache Deception (WCD), my team and I from Akamai, Northeastern University and the University of Trento, conducted a study into web cache deception in the wild, which we recently presented at the Usenix Security Symposium 2020. The following is a summary of our key findings and discussion as a means to mitigate against such vulnerabilities that apply to not just WCD but all cache attacks.
Recreating web cache deception
WCD put web cache attacks back in the spotlight when originally disclosed in 2017 — it’s a compelling example of how a seemingly innocuous confusion between a web application and a cache leads to data leakage.
Consider the scenario depicted below, where the web server hosts a banking application.
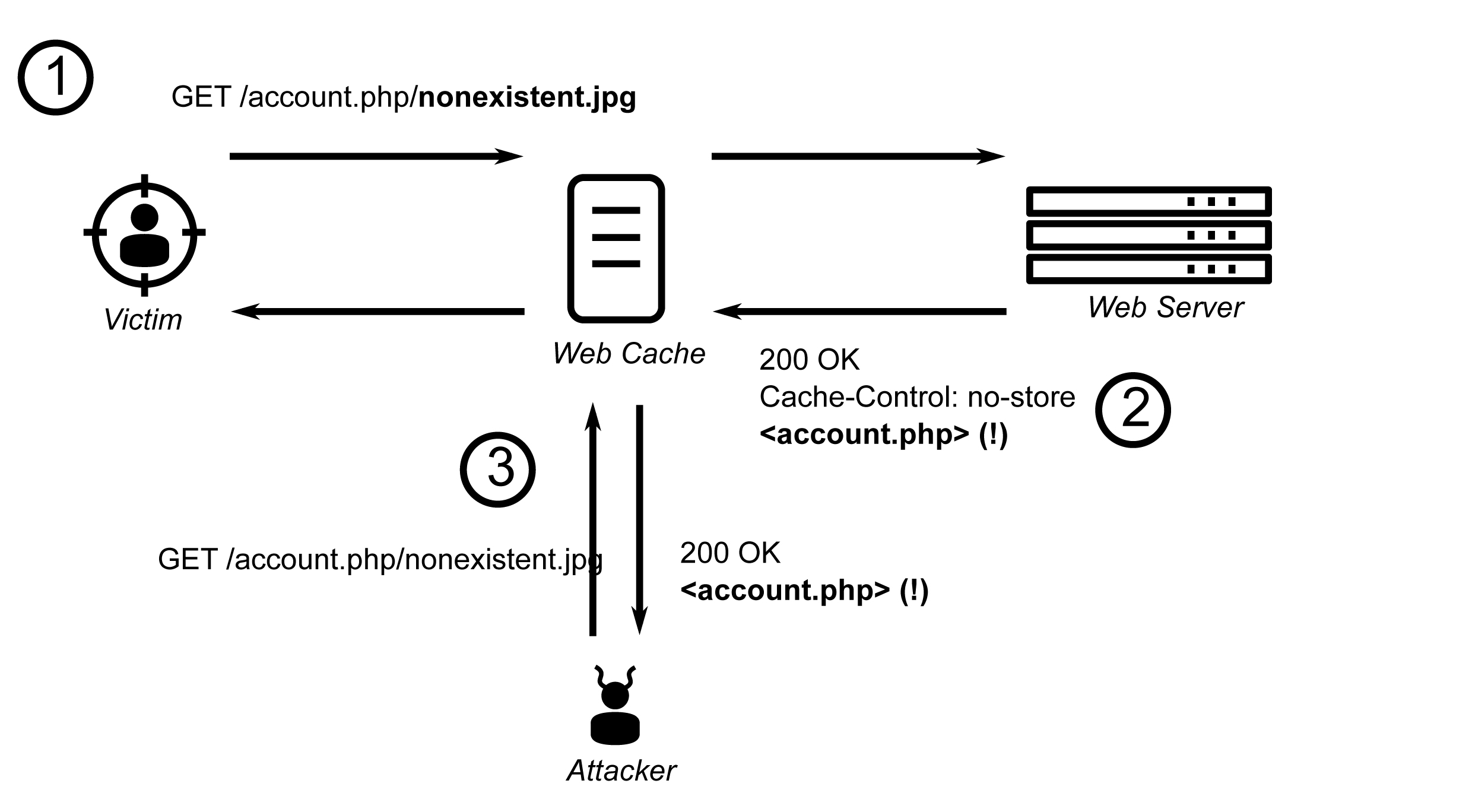
An attacker takes the URL for the account details page, but appends to it a non-existent path component disguised as an image (/account.php/nonexistent.jpg). Web applications are often configured to ignore such invalid objects and trim the path; in our example, the server simply responds with the account details (/account.php). However, the caching proxy fronting the bank remains unaware of this processing, and stores the response deciding that it’s a cacheable image based on the file extension. When victims visit this link, their account details will be cached, becoming publicly accessible on the Internet.
In our research, we built on this basic example, exploring tweaks to the technique to improve its efficacy, and performing a large-scale experiment showing that many websites are vulnerable.
It’s important to note that web cache attacks cannot be isolated to single faulty components. Recall from our example; neither the banking application nor the web cache is broken; instead, a discrepancy between how they process the URL leads to a vulnerability. This parallels safety engineering principles that predate cybersecurity: hazardous interactions between individually correct components can still lead to accidents.
The takeaway is that islands of secure components don’t make an overall secure system. Hardening HTTP processors only in isolation may even give a false sense of security. That might not be a particularly surprising conclusion, as the benefits of systems-centric security analyses are well established today. However, web cache attacks mark a significant expansion of scope: we need visibility into interactions between distributed technologies spanning the Internet.
Ethical hacking is hard, but defence is harder
Performing an Internet-wide sweep for web cache vulnerabilities is quick, easy, and lucrative. Doing it ethically is hard.
One miscalculated scanning decision can poison caches on the traffic path, inadvertently exposing confidential information or breaking websites until the caches are purged. Therefore, a big challenge for the security community exploring this domain is designing a safe experiment methodology that doesn’t put system owners or Internet users in harm’s way. In contrast, miscreants can freely explore without such hindrances.
Readers may be disappointed that I paint a grim picture, but propose no solution. There’s extensive literature on analysing the TCP/IP stack through intelligent fuzzing, taint propagation, and symbolic execution. Unfortunately, applying those analyses to distributed systems (let alone the entire Internet) remains an open research problem.
Systematically investigating the discrepancies between combinations of HTTP processors and publishing guidance on configuring specific setups is a direction that many research groups, including my own, have begun exploring. However, mature tools to test a network and get an actionable report are still far-off.
In the meantime, we need to operate in a reactive mode, and awareness of the issue is a good start. Let’s conclude by revisiting our earlier insights, and discussing how we can act on them.
Mitigation remains a cross-functional responsibility
Web cache attacks are systems’ safety problems. The implication is that change management and testing activities, typically performed by immediate component owners, should encompass all other related systems, too. If every small change triggering a full-fledged security review sounds scary, that’s all the more reason to invest in documentation and an asset register, so that relevant interactions can be identified and scope kept in check.
This concern equally applies to external interactions, and therefore to vendor management. Requiring proxy service providers to be solely responsible for guaranteeing security isn’t realistic. Reviewing how vendor configurations pair with internal systems necessitates a joint investigation.
Web cache attacks are easy to mount, and testers should take advantage of that. Equipped with staging environments and whitebox visibility into networks, internal test teams are well-positioned to experiment without risking collateral damage. Following the growing cache exploitation literature, and incorporating those into dynamic testing exercises is paramount.
Until we have streamlined methods that enable secure distributed system design, mitigating web cache attacks will remain a cross-functional responsibility, with a strong process component.
To learn more about our study read our full paper for a breakdown of our findings.
Kaan Onarlioglu is an Architect with Akamai’s Security Intelligence team.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.