

The de facto web security protocol, Hypertext Transfer Protocol Secure (HTTPS), has seen tremendous growth over the past decade, with the majority of websites visited by users now provided over the secure extension (Figure 1).
Read: HTTPS — How it protects browser users on the Internet today
So, how far are we from a web with HTTPS everywhere? Where browsers could upgrade all requests over HTTPS and/or could rely on HTTPS for requests with unknown protocols (that is, when a user types a hostname in the address bar).

To answer this question, we need to understand how HTTPS is deployed on the Internet.
A simple approach, used in prior work, is to load a single webpage (for example, a landing page) for large numbers of popular websites to see if they support HTTPS. Here, the assumption is that if one page on a website supports HTTPS, they all do. Another assumption is that if a server supports both HTTP and HTTPS, the content served over the insecure and secure protocols will be the same.
Read: Scanning .nz for HTTPS support
These assumptions may seem reasonable. After all, HTTPS is often referred to as SSL/TLS over HTTP, with the implication that the only difference between the two protocols is in the content delivery mechanism. However, as my colleagues and I from Northeastern University, Max Planck Institute for Informatics and the University of Maryland, College Park, found in our recent study, presented at TMA 2020, these assumptions do not hold universally.

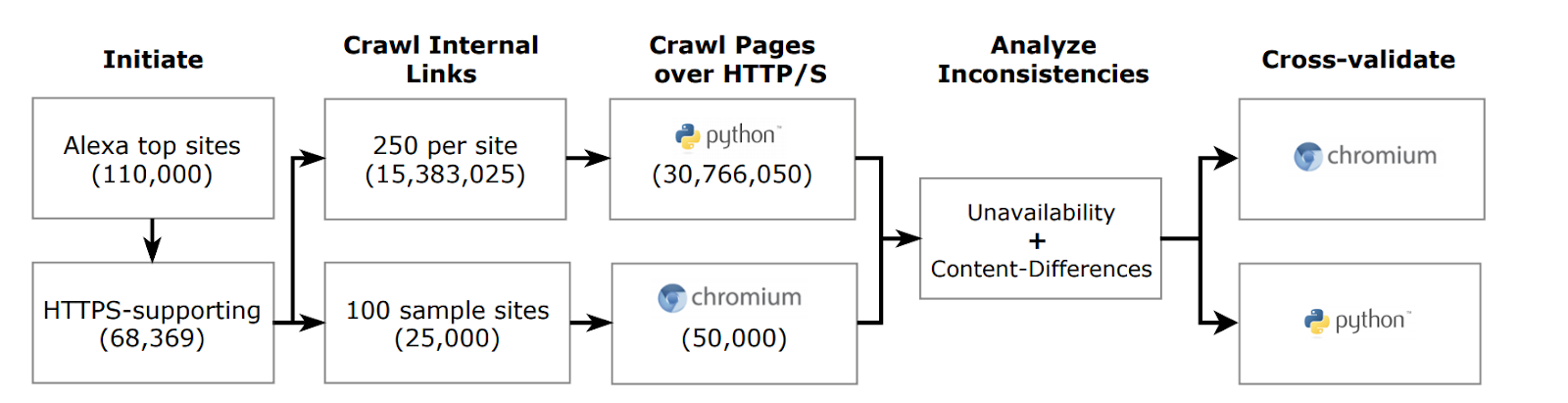
Having conducted deep crawls with content inconsistency checks for more than 100K popular websites from the Alexa list, we found that 1.5% of the HTTPS-supporting websites have at least one page available via HTTP but not HTTPS. Surprisingly, we also found 3.7% of websites with at least one Uniform Resource Identifier (URI) where a server returns substantially different content over HTTP compared to HTTPS.
Conducting deep crawls
During our study, we encountered various challenges that were particular to the nature of deep crawling.
To reveal the HTTP/S inconsistency issues, we checked for HTTPS support beyond a website’s landing page (“/”) — considering a maximum of 250 internal links for a site. We obtained these links through a depth-first recursive search of links referenced in HTML <a> tags. Such links are representative of links visited by real users in web browsers, and hence were suitable for the purposes of our study.
We considered a total of 110K websites in our work. Because of the sheer number of links involved, our crawls had to be time efficient. We found that using a Python-based crawler is considerably faster than a headless Chromium browser, as it does not attempt to render a page (that is, by executing Javascript and/or loading third-party resources).
It is important to mention that such deep crawls can put undue load over websites. We followed community norms for ethical scanning by:
- Respecting robots.txt directives.
- Using a custom user-agent with a link to study purposes.
- Allowing sites to opt-out from the study.
- Amortizing crawl load over all destinations.
Comparing HTTP/S content
Our content inconsistency checks explored: (i) whether a link can be accessed over both HTTP/S, and if it can; (ii) whether the content presented at the two differs ‘significantly’. While it is tempting to rely on byte-wise comparisons to check for content differences, this does not work because many webpages are dynamic (for example, a product catalogue page may deliver different content over multiple HTTP accesses). Thus, the key challenge we faced here was identifying meaningful differences.
Our approach relies on heuristics that capture visual differences across two pages (that is, visible-text differences and page-structure differences, based on HTML tags). For the purpose of our study, we assumed that the greater the visual differences across pages, the greater the probability of a user also finding them different. Further, we ensured that the differences between HTTP/S versions of a URI are greater than the differences between the same page fetched twice over HTTP, to handle content dynamicity while checking for inconsistencies.
We found that the majority of content differences were due to server misconfiguration of a particular type — misconfigured redirections — where the same URI is redirected to different URIs when accessed over HTTP vs HTTPS. For example, we noticed a website that had set HTTPS as a default protocol for all visitors, but in a way that any request over HTTP was redirected to the site homepage over HTTPS.
Admins, do your part to make sure HTTPS is deployed everywhere!
We propose that deep crawls are necessary to guarantee that a website can be successfully loaded over HTTPS and that more work needs to be done to evaluate the usability impact for when different content is presented over HTTP vs HTTPS, before a switch to HTTPS everywhere can be considered.
We also recommend website administrators use similar content-inspection techniques to verify the proper deployment of HTTPS. During our crawls, we had to limit the number of pages scanned to keep the crawl duration at an acceptable length. But for an individual site, an admin may use a list of all known resources and then test for HTTP/S consistency.
Talha Paracha is a Computer Science PhD student at Northeastern University. His research interests include Internet security and privacy.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.