

A few years ago, I was asked to act as an ambassador of sorts — from the world of router vendors and hardware, to the world of protocol designers and software — at least, in part, because I’ve been a protocol guy in a hardware world for many years now.
My failure to come up with a plausible excuse led to a talk at the IEPG meeting held at IETF 94 and later participation in a technology deep dive at IETF 104. Recently I was asked to turn those thoughts into a blog post and zoom in on considerations related to IPv6. This is that post.
We’re going to talk mostly about forwarding hardware and its relationship with the network layer, but to get there, I want to start with a cartoon sketch of a router. We’ll consider what classes of processors and designs are used for forwarding packets, then focus on one of them, walk through its advantages and limitations in more detail, and finish with considerations for what the implications are for network-layer protocols (and IPv6 in particular).
What’s a router?
It’s a truism that in computing, the easiest way in the door is with a general-purpose computer, but when you need serious scale for solving a particular problem, you turn to purpose-built hardware. This can be for reasons of cost, performance, or both.
Examples include graphics, where the humble graphics card has grown into the GPU, data-centre servers, which strip away amenities that are needed on desktop machines but which only burden the data-centre operator with extra cost, heat, volume, points of failure, and… routers.
It’s also true that the sweet spot in the spectrum between general-purpose and purpose-built is constantly on the move.
In this post, we’re going to think about routers that use purpose-built silicon to do their forwarding, rather than using general-purpose processors.
When I started in this business, everything was forwarded using general-purpose processors (68000’s, believe it or not, and even IBM RT PCs — the phrase “4 MIP, plenty CPU!” is burned into my memory forever although the speaker shall remain nameless). Within a few years, though, we had started to see the first custom forwarding silicon, and now there’s a large ecosystem of forwarding hardware at different price points and targeted toward different network niches; some of it’s custom, although increasingly it’s merchant silicon. I have no intention of covering each variant in detail or even trying to enumerate them; what we’re going for here is a representative overview.
Let’s start with a cartoon view of what a router is.
We can think of it as a control plane and a forwarding plane, with the forwarding plane broken down into the logic used to make and execute the forwarding decision (at Juniper we call these packet forwarding engines or PFEs) and the interconnect between the several PFEs (generally referred to as the fabric).
Smaller routers might have only a single PFE or might skip the fabric part altogether, and because this is a cartoon router I’m not worrying about the all-important element of how to actually connect to the physical media. As we’ll see, these simplifications are OK because we’re going to focus on the PFE part.
But first, let’s spend a little while looking at the control plane (I can’t help it, I work on the control plane for the most part). It’s generally going to consist of a couple of general-purpose processors, or just one if the system is built without redundancy. These are labelled ‘Route Engine’, or RE, in our cartoon (as usual, different vendors call them different things, but everyone has some kind of control plane processor). They’re connected to the forwarding hardware somehow, commonly over Ethernet (this is the box labelled ‘Backplane’, which, by the way, is not the fabric that interconnects the line cards).
Over on the forwarding plane side (the stack of boxes labelled ‘Line Card’), we have one or more collections of an embedded control processor (another general-purpose processor) managing one or more PFEs.
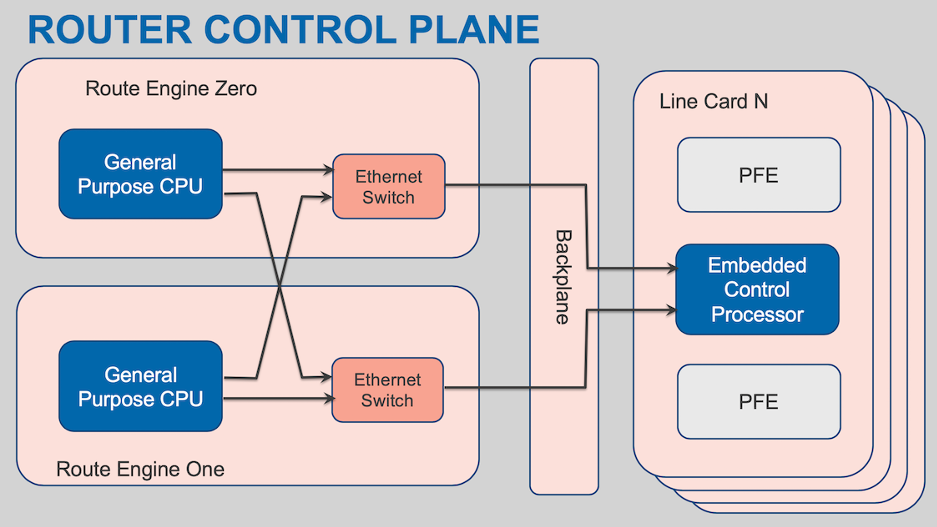
The CPUs on the REs run the routing protocols, management protocols, user interface, and so on. They’re the heftiest processors in the router. They may even be as powerful as the CPU in a typical laptop! Or not, for various reasons — laptop manufacturers don’t have the same certification requirements routers do, and besides, the job of a router is ultimately to move packets.
Protocols are a loss-leader, nobody makes money by running one. Every cubic centimetre of volume taken up in the chassis, watt of power consumed, and joule of heat dissipated by the control plane is one that’s not available for revenue-generating interfaces… and so the pressure is on for the manufacturer to provision no more than is needed. But I digress.
The main thing to know about the REs is that they aren’t going to be forwarding packets: there’s a mismatch of orders of magnitude between the interface speeds of even a small-to-middling router, and the bandwidth available in and out of the REs. We can disregard them for the rest of this post.
What’s a forwarding engine?
Let’s breeze right past the fabric, which I will shamelessly oversimplify as an interconnect of infinite speed that connects all the PFEs, and look at what PFEs do and how. At the highest level, they forward packets. This entails:
- L2 and L3 analysis and features — figure out whose packet it is, what should happen to it, where it should go.
- Packet buffering — store the packet in memory (this could be either on-chip or off-chip) until there’s room to transmit it.
- Queuing and scheduling — decide which packets should go in what order to achieve fairness and real-time delivery guarantees. When queues accumulate, the router must determine which packets to keep and which to drop (this decision should be done in a way that favours higher-priority packets).
The hardware implementation can be micro-programmable, table-driven, or hard-coded. They can be fully integrated on a single chip, or different functions can be separated onto different devices.
Let’s consider some forwarding architecture types (and, as usual, this isn’t exhaustive):
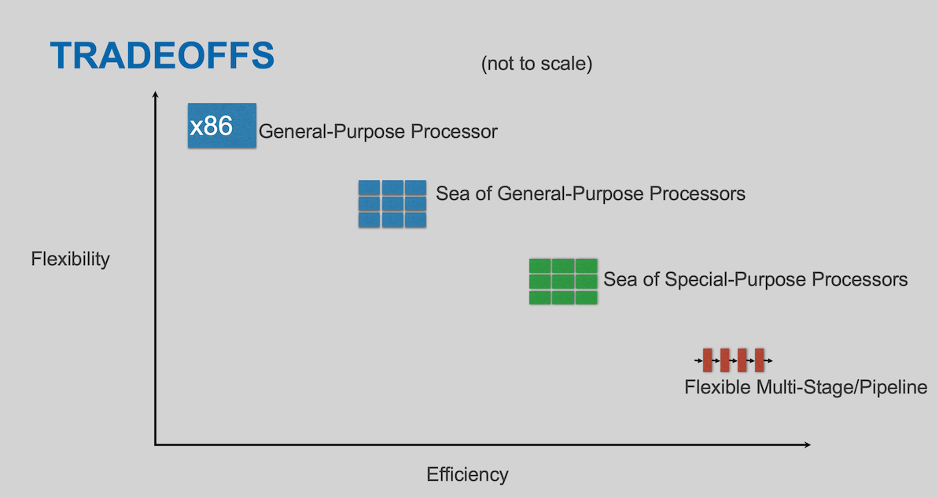
On the left, you have a general-purpose processor
On one end, most flexible but least efficient at forwarding packets, we have the general-purpose processor. It presents the most convenient programming model and is familiar to just about everyone. In low-volume and (relatively) low-performance applications, or applications where packet forwarding is just one small part of what’s being done, they have a distinct role to play. But despite remarkable advancements in both their speed at forwarding packets and the programming model available for that purpose, they can’t equal dedicated hardware when performance is at stake.
The reason for this is easy to see when you consider the iron law of TANSTAAFL: There Ain’t No Such Thing As A Free Lunch. For general-purpose processors to be useful in all applications, they have to have an instruction set and uniform memory model that caters to all applications. That costs money, space, and power. Why do you want to spend space in your router on an amazing floating-point unit, or graphics processing instructions, that will never be used? You don’t. The general-purpose processor is an amazing jack of all trades, but it’s still the master of none.
The rest of the spectrum trades away various bits of the flexibility of a general-purpose processor, in favour of performance. When the trick is done well, we trade away only flexibility we didn’t need anyway. It might be obvious to say “no, my router doesn’t need graphics processing instructions,” but mostly it’s harder and requires a crystal ball to predict the future.
To take a key (no pun intended) example, the memory model is an important difference. General-purpose processors typically are presented with a buffer that contains the entire packet; they can inspect any byte they wish. More specialized forwarding processors typically have (very) fast access to the first n bytes, but either have no access or pay a penalty, to n+1 and beyond. And so, by the time the processor tapes out, someone has had to answer, “How many bytes of key data is enough?”, even if they do feel like they’re being asked “How long is a piece of string?”.
In the middle, we have a couple of NPU variants
These have a large(ish) number of cores, likely with instruction sets specialized for packet processing. They may offer a programming model like that of a general-purpose processor, or a programming model more tailored to packet processing. They may well have a lower clock speed and fewer fancy features such as branch prediction and threading. But because they’re specialized to one kind of workload, packet processing, that’s OK — the space is better used providing more cores.
For a router, the performance that matters is not how fast you can run a single relatively large job to completion. Rather, it’s how fast you can run lots of small jobs, where each job is processing a single packet.
And at the far end of the spectrum, we have the pipeline processor
For these the processing steps are somewhat fixed: there’s a fixed number of stages; each stage has the same time allocation, and each stage passes the results of its work to the next stage. The stages may be programmable, within limits. The vocabulary with which they’re programmable is likely to be very specialized, compared to a general-purpose processor, tailored to fields and constructs found within existing packet headers.
One might think that the least flexible implementations would lack competitiveness, but the cost, energy, and performance advantages are so substantial (orders of magnitude, compared to a general-purpose processor) that in fact, they have wide application throughout the industry.
If you’re buying a router, for many applications the main questions will be: Does it do what I need now? How much does it cost? How big is it? How much power does it draw? How reliable is it? The question of “how future-proof is it” may not be anywhere near the top of the list. So, even though as a software guy I think everything should be maximally programmable, as a pragmatist I see that business realities mean that may never be the case.
Fast path vs. slow path
The forwarding that takes place in the PFE is what’s typically called the ‘fast path’. When a packet can’t be forwarded by the fast path, for whatever reason, we have two options: drop it, or punt it to the ‘slow path’ software forwarding, probably in the embedded control processor.
This seems like an attractive option for the protocol designer: the occasional exception packet can’t hurt anything, right? The problem occurs when we consider scale.
Even if it were entirely dedicated to forwarding (which it is not) the control processor is unlikely to be able to sustain even 0.1% of the forwarding rate of the hardware forwarding chips it’s paired with. Remember that the control processor is a ‘loss leader’. It’s powerful enough to get the job done of managing the forwarding hardware, bootstrapping it, downloading forwarding tables, and so on, but it’s not provisioned as a packet forwarding beast. Nor should it be — that’s the job of the forwarding hardware. (Similar considerations apply when packets are punted to the RE.)
Implications for protocols
Clearly, this doesn’t mean — can’t mean, would be unacceptable for it to mean — that protocols can never change and evolve. But what does it mean?
The good news is that even the most basic forwarders are quite programmable — within limits. The trick is to appreciate what those limits are and to not cross them accidentally.
Crossing them on purpose, because you must, is another matter — sometimes you just can’t make an omelette without breaking some eggs. But if my protocol requires punting packets to the slow path, and yours gets the same job done but can stay on the fast path, I think I know whose protocol will win in the market, and it isn’t mine.
There is no one-size-fits-all flowchart for a protocol designer, but the following are some principles that protocol designers would do well to take to heart.
The forwarding decision must fit in the key data
One of the limits we spoke of is key data size. This is the data made available to the forwarding processor in fast memory, while the rest of the packet is buffered in relatively slow memory that’s either inaccessible to the processor, or at a substantial penalty. Thus, to sustain throughput, everything necessary for the forwarding decision must fit in the key data — the L2 header(s), L3 header(s) including any extension headers, tunnel headers, and so on, and also any higher-layer headers needed for load balancing entropy. If the key data for a particular processor is, say, 256 bytes, then everything is fine until the header chain hits byte 257.
Fixed header lengths make parsing easier
Despite what ‘everyone knows’, it’s not crucial for fields to be sized to a power-of-two, or even to be word-aligned.
Fixed locations for fields is important though, and it’s helpful for the overall header length to be a multiple of 32 bits. One implication of this is that TLVs in headers that must be parsed hop-by-hop are costly.
It’s very tempting for protocol designers to throw an optional TLV field into everything — who couldn’t love future-proofing? The answer is, people who have to check for TLV presence in the fast path, and potentially parse an indeterminate number of TLVs, that’s who!
One more cardinal sin for a protocol is one in which a header doesn’t explicitly specify the type of the subsequent header. This is a problem because pipeline processors typically parse the packet before starting any lookup, and any additional indirection inserted into this parsing process can be costly.
Especially in a pipeline processor, it’s a problem if headers are processed in some sequence other than how they appear in the packet, or if processing a given header requires referring to a different header. Headers should be self-contained. As a rule, each header should either provide the information needed to route the current packet, or it should provide the context in which the subsequent header should be interpreted.
Use an established header in a novel way instead of inventing a new one
Since there’s likely to be hardware support for existing headers, it’s desirable when possible to use an established header in a novel way instead of inventing a new one. There’s a caveat, though — the novelty must fit with the semantics of the header; you can’t take a field that was previously used as (say) a checksum and say “oh, that’s an address now” and expect a happy outcome. But taking an existing address and choosing to interpret it in a new way, may well work out. SR-MPLS (RFC 8660) is a good example of this.
Manage header size
Equal Cost Multipath (ECMP) and Link Aggregation Groups (LAG) are in wide use; in order to assign flows to an ECMP or LAG member, a router must be able to identify the flow using some source of entropy. It’s important that it be possible to easily find these entropy sources, and that they occur within the key data — if the headers grow so large that the entropy (say, from the transport header) is pushed into packet body buffering, that’s a problem. Keeping the sources of entropy close to the top of the packet and close together (both from a literal number of bits and in terms of the protocol stack) is helpful.
Other considerations
To consider a few real-world examples that deviate from these guidelines, Multiprotocol Label Switching (MPLS) doesn’t specify what type of header lies beyond the MPLS stack, it must be inferred based on information delivered by the control plane along with the label value. BIER (RFC 8279) can produce headers of up to 524 bytes. The IPv6 Segment Routing Header (RFC 8754) carries optional TLVs that the processor must be prepared to parse, though at least it’s polite enough to put them at the end of the header. SRv6 (RFC 8402) also embeds ‘instructions’ in IPv6 addresses; the parsing of these instructions is affected by control plane information and affects the handling of subsequent headers.
The MPLS illustration should also serve to demonstrate that even if a protocol design isn’t ideal for the silicon, it can still be a smashing success!
Context is everything
The analysis above is from one viewpoint, that of a high-performance router in or near the core of a network, that’s moving lots of packets, at scale. Of course, that’s not what the whole world is, but as the old ditty goes,
A host is a host From coast to coast And nobody talks to a host that’s close Unless the host That isn’t close Is busy, hung, or dead.
The point here being unless there’s some reason a protocol or extension is guaranteed to be deployed only in limited, local environments, it’s wise to assume it will be run across the big-I Internet. And when that happens, its packets will be handled by those high-performance routers we’re talking about.
On the other hand, not every router is a core router, and routers in other roles may be able to spend more resources providing features (tunnel termination, for example, or encryption). This is fine, as long as the features in question are architected such that they only incur a cost at the point where they’re provided.
Bringing it home to IPv6
Let’s think about IPv6 now in the context of the information above.
In some ways, IPv6 was designed as a more processor-friendly protocol than IPv4; in particular, the IPv4 header is variable-length and the IPv6 header is fixed-length. That’s very helpful. It also organizes its options such that a transit router need not even attempt to parse options of relevance only to the destination node.
In other ways, IPv6 presents greater challenges than IPv4: because of its greater extensibility, IPv6 has more options. An IPv6 header chain can potentially grow rather large, conceivably large enough to trigger some of the problems described above when the headers exceed the capacity of fast memory to store them for the forwarding engine.
For some older devices that didn’t include IPv6 as a first-class citizen in their silicon design, extension headers of any sort are problematic, moving the packet off the fast path or otherwise reducing the packet rate through the forwarder.
Newer devices (made in the last few years) have the potential to remedy this issue but even though the silicon is capable, the microcode that runs on it may lag; for this reason, throughput for IPv6 packets with extension headers continues to be chancy.
This leads to another question — suppose we introduce an extension to the protocol. How long will it take for the silicon to catch up?
The answer is a bit tricky, but the oversimplified guesstimate is “a couple of years, maybe?”.
A number of factors play into why this is an oversimplification, including the fact that the existing silicon may already be flexible enough to support our extension with new microcode, and also the chicken-and-egg consideration that your extension may need silicon support to become popular, but silicon may not want to support it unless it becomes popular. It’s for this latter reason that the guidelines in the earlier section ought to be considered carefully.
In conclusion, we still have work to do
As we’ve seen, once silicon is baked, although a router’s abilities aren’t necessarily set in stone, they’re set in some pretty firm mud at least, so the introduction of a radically new network layer protocol is a daunting prospect.
The good news for IPv6 is that the design is sound: there aren’t fundamental obstacles to processing it at line speed.
The ongoing challenges we face are implementing and deploying microcode to take advantage of the hardware’s capabilities. I hope to explore this further in a follow-on blog post.
Acknowledgements
Thanks to Brian Petersen, on whose earlier work this blog is based. Thanks also to Frank Brockners and Toerless Eckert, my co-panellists at IETF 104. Finally, thanks to my Juniper colleagues, Jeff Libby and Ron Bonica, who kept me honest. All errors are, of course, my own.
John Scudder is a Distinguished Engineer at Juniper Networks, where he focuses on routing protocol design and standardization.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.