

IPv6 has had two versions of private addressing – deprecated site-local addressing and the current Unique Local Unicast Addresses (ULAs).
Having had some involvement in the site-local deprecation discussions and the subsequent ULA discussions in the IETF, starting in 2002, I’ve since seen several examples of ULAs being incorrectly treated as though they were the exact IPv6 equivalent of IPv4’s RFC 1918 private addresses.
In this post, I will explain why site-local addressing was deprecated, and how to get IPv6 ULA addressing right.
First attempt
Site-local addresses have an Internet Assigned Number Authority (IANA) allocation of fec0::/10. The site-local prefix had been defined in RFC 4291, “IP Version 6 Addressing Architecture” and its ancestors, going back as far as its first ancestor, RFC 1884, from 1995.

In around 2002, two main questions came up in the IPv6 IETF Working Group:
- What is a site?
- How can two sites using the site-local prefix be merged, without renumbering or resorting to Network Address Translation (NAT)?
These two main questions triggered the eventual deprecation of IPv6 site-local addresses and the invention of their replacement.
What is a site?
The main drawback of the ‘site’ terminology when used with site-local IPv6 addressing is that the word ‘site’ is really too fixed and geographical. A site is typically a building, campus or office.
Private, local addressing can also have applications in wide area networks, spanning more than a site, and in moving or mobile networks, such as networks in planes, boats and cars.
This means that the use of the term ‘site’ to describe IPv6 private addressing was not accurate.
Site-local networking issues
Another issue with site-local addressing comes up when two independent networks using the site-local prefix need to be merged.
Humans being humans, there is a good chance that these two formerly independent networks will have duplicate subnets, within their own instance of the site-local prefix.
When these two networks are merged, it would mean that the duplicate site-local network in the remote network will be unreachable from the local network, as IPv6 packet forwarding normally sends packets to the closest instance of a destination.
This problem has come up before in IPv4, and the method that has been used to overcome it has typically been IPv4 NAT. IPv4 NAT has been used to make the duplicate destination in the remote network unique within the local network so that it can then be reached.
There are several drawbacks with the use of NAT, as I have discussed in a previous series on the APNIC Blog. Fundamentally, NAT in IPv4 has been used to overcome the limited size of the 32-bit IPv4 address space. As the IPv6 address space is massively larger than IPv4’s (2^96 or about 73 billion billion times larger), there should be no need to use NAT in IPv6 (RFC 5902).
Deprecating site-locals
These issues and others lead to IPv6 site-local addresses being formally deprecated in RFC 3879, “Deprecating Site Local Addresses”.
Many of the issues discussed in the site-local deprecation RFC are not unique to IPv6 and have appeared many times with the use of IPv4 RFC 1918 private addresses. The issues with non-unique IPv4 addresses were already recognized when IPv4 private addresses were being defined back in the early-to-mid 1990s, as described in RFC 1627.
Prevention is better than cure
The other alternative to NAT is renumbering the duplicate subnets such that they become unique across the two different networks that are being merged. However, renumbering can be a reasonably significant effort (RFC 4192).
Both renumbering and NAT could be considered ‘cures’, and as our friend, Erasmus said, “Prevention is better than cure.”.
So, how do we ‘prevent’ needing to deploy IPv6 NAT or subnet renumbering?
We prevent this issue by making the private IPv6 subnets (and therefore IPv6 addresses) globally unique in the first place, even though functionally, they only really need to be unique within the networks in which they’re going to be used.
The idea of making identifiers and addresses globally unique, even though they only need to be locally unique within a local context, is not new. We’ve seen it before with Ethernet MAC addresses, which are designed to be globally unique, even though as a link-layer address they only need to be unique within the link they’re attached to.
IPv6 private addressing: Unique local unicast addresses
A new type of IPv6 private address was introduced with RFC 4193, Unique Local IPv6 Unicast Addresses (ULAs), with the main difference from site-local addresses being the inclusion of a 40-bit Global ID field.
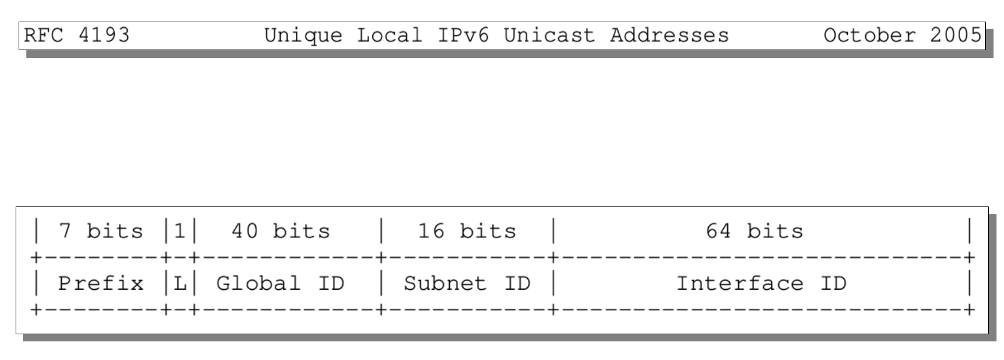
Global ID
The Global ID field is the part of the address that makes the ULA prefix globally unique.
RFC 4193 specifies some requirements for the Global ID field:
- “The allocation of Global IDs is pseudo-random.”
- “They MUST NOT be assigned sequentially or with well-known numbers.”
RFC 4193 also describes an algorithm to generate a Global ID value that meets these requirements.
The Global ID easily allows two or more networks with different ULA prefixes to be interconnected without having to resort to network renumbering or IPv6 NAT, as the IPv6 subnets within each network will now be globally unique.
The L-bit
A single bit appears before the Global ID part of the ULA prefix and indicates that the ULA prefix has been generated by the local network. This means that the Global ID isn’t assured to be unique, even though it has been allocated pseudo-randomly.
There was a possibility of a central authority who would allocate ULA prefixes to assure global uniqueness. However, this has never eventuated. In that case, the L-bit value would be zero.
This means that the L-bit is always 1 in all current ULA prefixes, so all valid ULAs start with the 8-bit prefix fd00::/8.
ULA /48s
Combining the 8-bit fd00::/8 with the 40-bit Global ID provides an IPv6 /48 ULA prefix for use in the local network. With 16 bits for subnets, this /48 ULA provides 65,536 /64 subnets.
If 65,536 /64 subnets aren’t enough for the local network, or there needs to be route aggregation or summarization boundaries within the local network at a higher level than the subnet field, multiple /48 ULA prefixes can be generated and used with their own different Global ID values. Note, this set of ULA /48s must not have Global ID values that are in sequence, as this would violate the RFC 4193 Global ID requirements.
ULA generators
To generate a likely globally unique /48 ULA prefix that complies with RFC 4193 requirements, several ULA generator applications and websites are commonly available, and can easily be found via an Internet search, or by looking in the smartphone application stores.
Another location for a ULA generator is within RFC 7084, “Basic Requirements for IPv6 Customer Edge Routers” compliant routers. This generates a new /48 ULA prefix whenever the device is factory reset and stores the ULA prefix for continued use. This ULA prefix is automatically generated to provide local internal connectivity on the downstream LAN interfaces of the router that is independent of the router’s WAN Internet connectivity. This, for example, allows the local network to be set up and used while waiting for the Internet to be connected, or when there might be a long Internet outage.
ULA or GUA? Why not both?
When IPv4 RFC 1918 private addressing has been used within a network, and that network is then connected to the Internet, IPv4 NAT has been used to translate between the inside private addresses and the outside public Internet address or addresses.
So, should private ULA addressing be used in the same way? It isn’t intended to be.
As mentioned before, one of the main reasons for IPv4 NAT has been to expand the limited IPv4 address space, a problem that doesn’t exist in IPv6. Using NAT with IPv6 defeats the purpose of IPv6.
One of the significant differences between IPv6 and IPv4 is that IPv6 formally supports multiple addresses being assigned to a single network interface.
IPv4 has supported multiple addresses assigned to a single network interface, however, it has been a bit of a hack – the IPv4 route table in a device treats the multiple addresses as though they were assigned to different network interfaces. Traffic between hosts on different subnets on the same link must go via a router, even though the hosts are attached to the same link. DHCPv4 doesn’t support assigning multiple IPv4 addresses to the same network interface.
In IPv6 we don’t have an exclusive choice between assigning a network interface an internal private address or an external public Internet address – known as an IPv6 Global Unicast Addresses (GUA) (RFC 4291). We can assign a network interface both ULA and GUA addresses concurrently, or even multiple ULA addresses from the same or different ULA prefixes and multiple GUA addresses from the same or different GUA prefixes all at the same time.
ULAs are preferred over GUAs, so when a host is presented with both a ULA and GUA as possible ways to reach a destination, the host will select the ULA. Once the ULA destination address is chosen, the host will then choose its ULA as a source address to reach the ULA destination. This preference of ULA addressing over GUA addressing is the mechanism that provides internal network connectivity independence from concurrent external Internet connectivity.
IPv6 address selection (RFC 6724) is more complicated than I’ve just described; for example, native IPv4 is preferred over tunnelled IPv6. However, a simple rule to remember is that more local or smaller scope addresses are preferred over more global or larger scope addresses (with the IPv6 loopback address, ::1/128, having the smallest scope and therefore being the most preferred address over all others).
Incorrect ULAs
I’ve seen several examples of where ULAs have been treated as though they’re the exact, IPv6 equivalent to IPv4’s RFC 1918 private addresses, and where RFC 4193 requirements haven’t been met.
The main example I’ve seen is Global ID values that are quite obviously unlikely to be globally unique and not likely to be random, suggesting they’ve been have chosen by a human. fd00:0000:0000::/48 and similar is a common example.
On one occasion, the L bit wasn’t set, meaning the prefix started with fc00::/8, so the ULA prefix was implying it was assigned by a non-existent central authority.
In another case, where the same entity was using several ULA /48s, while it appeared that the first had been chosen using the RFC 4193 ULA algorithm, the subsequent /48s had sequential Global ID values.
Another example is where it appeared that a solution integrator with multiple customers for the same solution within a region had generated a single, likely globally unique /48 ULA prefix, and then used longer prefixes within the single /48 ULA for the different customers. Different /48 ULAs for the different customers would have been the correct way to use ULA addressing in this case, as these were separate customers’ networks.
Make sure your ULA /48 prefixes are globally unique
Hopefully, you’re now fully across what IPv6 ULA addressing is, why it is different from IPv6 site-local addressing and why site-local addressing was deprecated.
You should also have an idea of how to use IPv6 ULAs in conjunction with IPv6 public Internet GUA addressing.
The key thing to take away from this article is to make sure your ULA /48 prefixes are globally unique. The best and easiest way to achieve this is to use a commonly available ULA generator website or smartphone application that implements the RFC 4193 algorithm.
This blog post is based on my AusNOG 2019 and NZNOG 2020 presentations.
Mark Smith is a network engineer having worked at several organizations since the early 1990s, including several residential and corporate ISPs.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Why not both? Because Application Developers don’t understand networking well enough to write code that doesn’t lose its mind when presented with that situation.
ULA is a waste of space and serves no purpose not better suited to GUA. It’s only real advantage is a slight annual cost savings. This does not outweigh its numerous disadvantages.
Owen, the getaddrinfo() Sockets API call hides address selection from application developers.
If I recall correctly, you don’t agree with ULAs because you have and are willing to pay for RIR PI /48 space for home. I think you’ve also said you think everybody should have PI like you do so people can have IPv6 address space at home that is independent of their ISP, negating the need for a private, local, unique network address space.
That is not practical for normal, non-technical end users, who just want things to work without having to understand technical details like what an RIR is or what a /48 is. Nor would most people be will be willing to pay many hundreds of dollars per annum for RIR membership to get a PI /48 (e.g., APNIC is $500AUD sign-up, $1180 AUD annual minimum when holding any IPv6 address space).
Everybody having their own PI /48 won’t allow Internet routing to scale either.
I very much see it that large organisations should get PI space, small and medium organisations use PA and ULA, and non-technical home users just use the PA space from their ISP.
As Mark said, if every organisation with local resources used PI space to avoid internal resource numbering being tied to choice of ISP – the routing tables will become hideous.
Perhaps cloud migrations will overtake all of this and there won’t be the on-prem resources to worry about?
(Laughs) “The Cloud” has been dragging on IPv6 migration. 2020, and Docker/Podman still struggles with it; I think Hadoop & some other clustering setups too.
Any newer home ISP setup + OpenWRT setup does ULA out-of-box. It’s not going anywhere. Opnsense tries to implement something Cisco was backing for NATing public v6 to ULA.
https://docs.opnsense.org/manual/nptv6.html
Does it still prefer ULA over GUA when the destination address is GUA? or it just prefer ULA over GUA when the destination address is ULA?
Anyone struggling with implementing this stuff, I used Netbox at my last few jobs to sort out the IP addressing.
1. Generate /48 ULA
2. Setup https://github.com/netbox-community/netbox/
3. If public IPv6 is available, use its lowest sized site allocation as guidance for the sites (i.e. if given a /56 or /60, use that as guidance to build up on). Each VLAN (or default wired LAN) should be a /64.
4. Take into account geography, cloud services, and other possibilities. This is where you can leverage /52 allocations.
Obviously, it will use GUA to talk to GUA destination.
But what if it has multiple GUA addresses? Which one will be chosen? That`s the question.
i preffered IPV6 Nat.
With all the dump people out there it will be same as 20y ago, lots of unprotected pc’s/server just because people find firewalls anoying.
at least a natted connections stops the direct access to a unprotected pc.
I need a ULA that can browse internet thru NAT so my FortiAnalzyer can logged the traffic statistics for all network usage by all nodes/hosts in my network. This requires static address for IPv6 or IPv4.