
This is the third and final post in our SRv6 series. Read the first two ‘Introduction to SRv6 network programming’ and ‘Deployed SRv6 use-cases’.
Network programming is seminal to the Segment Routing over IPv6 data plane (SRv6) solution. It allows for expressing any end-to-end service in a stateless manner as a set of 16-byte instructions (Segment ID, or SID) encoded in the packet header.
The network instructions may express traffic-engineering behaviours (go to this node via the Best-Effort Slice, go to this node via the Low-Latency Slice), fast-reroute behaviours (upon the sudden loss of a link, reroute the traffic via an optimum backup path), VPN behaviours (egress the network via a specified Virtual Private Network (VPN) table of a specified Provider Edge (PE) router) but, as well, any application behaviour (container, virtual machine or physical service appliance).
In this post, we introduce a straightforward extension to the SRv6 network program: each 16-byte instruction may contain up to six micro-instructions . The SRv6 Segment Routing Extension Header (SRH) data plane (RFC 8754) and the SRv6 control plane are leveraged without any change.
Intuition
A computer program generally comprises several instructions. An instruction, in turn, can itself be a micro-program composed of several micro-instructions.
Similarly, in SRv6, any network instruction (in the destination address (DA) or the SRH) can “contain” a micro-program of up to six micro-instructions.
A micro-instruction is referred to as a uSID.
A micro-program contained in an SRv6 SID
A 16-byte SRv6 instruction that contains a micro-program is called a container instruction and has the following structure:
BBBB:BBBB:<uSID1>:<uSID2>:<uSID3>:<uSID4>:<uSID5>:<uSID6>
Within the SR domain, the operator allocates a /32 prefix represented as BBBB:BBBB::/32, where each ‘B’ is a nibble (4 bits). The /32 prefix can be allocated from a public or private range. Any SRv6 instruction that starts with these 32 bits is then known to contain a micro-program of up to six 16-bit micro-instructions, each represented as <uSIDx>.
The solution supports any prefix length, specifically we equally support /16 and /48 prefixes. A /32 is used in this example as it is expected to be the most frequently used.
In the case where a micro-program contains less than 6 uSIDs, any unused micro-instruction is set to the value 0x0000 known as “End-of-Container”. We use the prefix ‘0x’ to denote hexadecimal numbers.
For example, a micro-program of three micro-instructions has the following structure:
BBBB:BBBB:<uSID1>:<uSID2>:<uSID3>:0000:0000:0000
The active uSID, that is the one currently being executed, in the above program is identified by BBBB:BBBB:<uSID1>/48.
Once this active uSID is completed, the micro-program becomes:
BBBB:BBBB :<uSID2>:<uSID3>:0000:0000:0000:0000
This updated micro-program is the result of the following operations:
- The completed uSID is popped.
- The remaining micro-program is shifted left by 16 bits.
- An End-of-Container (0x0000) is inserted in the last 16 bits of the DA.
The most basic type of micro-instruction is called “uN”. It specifies going via the shortest path to a node followed by the activation of the next uSID in the micro-program.
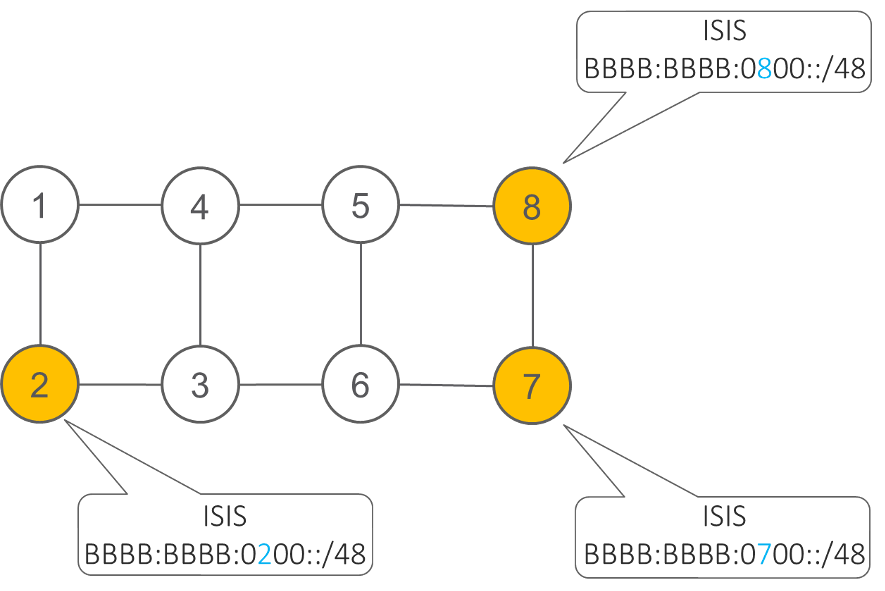
For example, if node 8 is configured with the uN uSID BBBB:BBBB:0800::/48 then, without any new control-plane extension, node 8 simply advertises in IS-IS the IPv6 route BBBB:BBBB:0800::/48. Any IPv6 router will route a packet whose DA starts with BBBB:BBBB:0800::/48 along the shortest path to node 8. Once the packet reaches node 8, node 8 activates the next uSID as described above.
Illustration
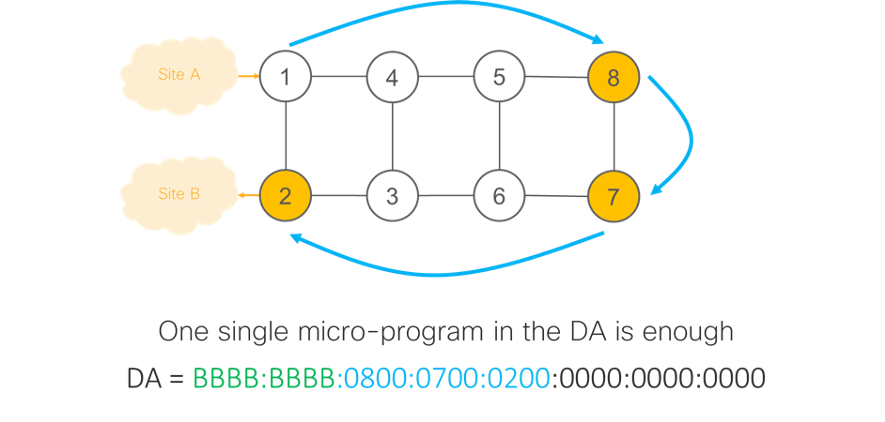
Let’s assume customer packets need to be transported over an SRv6 network, as illustrated in the figure below, from Site A (connected to node 1) to Site B (connected to node 2) along the shortest path through 8, then 7, then 2.
This can be implemented with an SRv6 micro-program comprising the following ordered micro-instructions:
- uN(8): “go via shortest path to node 8”, identified by 0x0800 for human readability
- uN(7): “go via shortest path to node 7”, identified by 0x0700 for human readability
- uN(2): “go via shortest path to node 2”, identified by 0x0200 for human readability
- End of Container, identified by 0x0000
- End of Container, identified by 0x0000
- End of Container, identified by 0x0000
In this simple example, the entire network program (shortest path to node 8 then to node 7 then to node 2) can be expressed in only three micro-instructions and hence the entire network program fits in the DA. There is thus no SRH.
When a network program requires more than 2 instructions, an SRH is leveraged. For example, an ultra-scale inter-domain 5G use-case allowing for 18 micro-instructions would leverage an SRH of two SIDs: six micro-instructions in the DA, six in the first SID of the SRH and six in the last SID of the SRH. The SRv6 micro-program capability fully leverages the SRH data plane encapsulation without any change.
Coming back to our simple example, the Ingress PE of the SR domain will encapsulate the customer packet in an outer IPv6 header whose DA is set to BBBB:BBBB:0800:0700:0200:0000:0000:0000.
Nodes 1, 4 and 5 do plain IPv6 forwarding of this packet. They do an IP longest prefix match of the DA and find that it matches prefix BBBB:BBBB:0800::/48 as advertised by node 8. As such, they forward the packet to node 8.
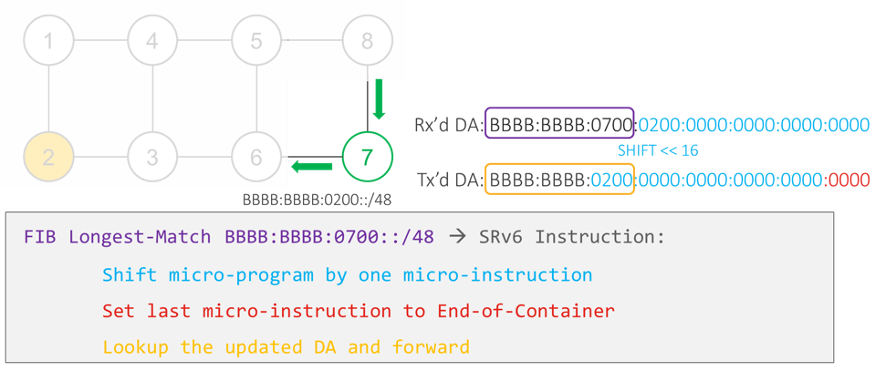
Node 8 looks up the DA of the received packet and finds that it matches a local SRv6 micro-instruction which expresses a shortest path to node 8 along the Best-Effort Slice. As the packet reaches its destination, the micro-instruction is completed. Hence, node 8 will activate the next micro-instruction. To do so, node 8 shifts the micro-program (that is, the IPv6 DA) 16 bits to the left and sets the exposed 16 rightmost bits to zero. This operation results in an updated DA:
BBBB:BBBB:0700:0200:0000:0000:0000:0000.
Node 8 then does a longest prefix match on this new DA and forwards the packet on the shortest path to the matched prefix BBBB:BBBB:0700::/48, as advertised by node 7.
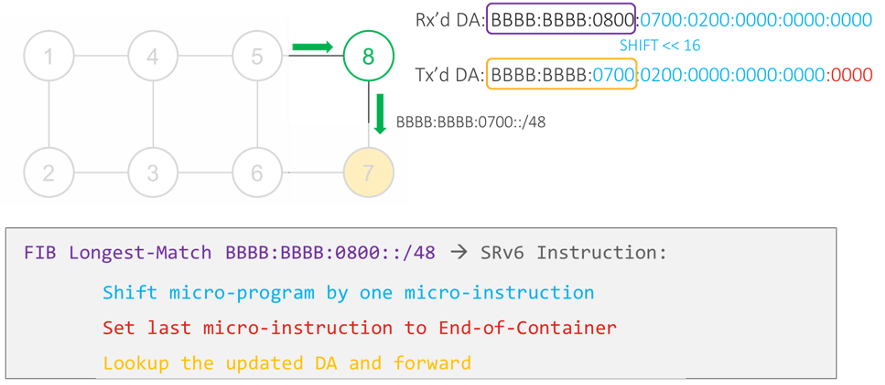
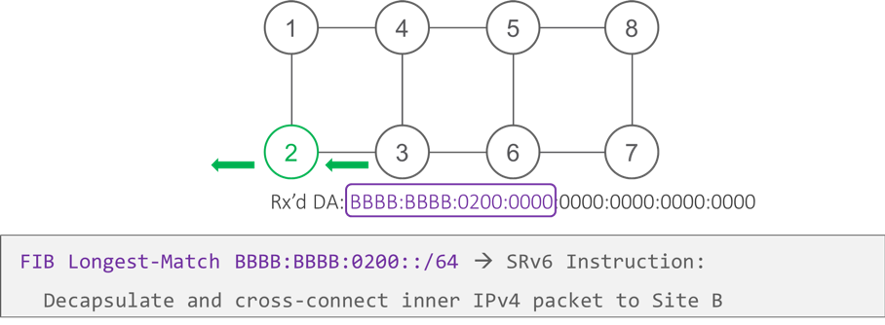
Node 7 does the same shift and forward as Node 8 to load the next-micro-instruction, which leads the packet to node 2.
When the packet arrives at node 2 — the Egress PE — the micro-program is terminated and the inner packet is sent to customer Site B.
In this example, we chose a use-case that needed less than six instructions. For use-cases that require more than six micro-instructions, the remaining micro-instructions will be placed in container instructions in an SRH.
Benefits of SRv6 micro-programs
Without any change to the SRv6 data plane nor control-plane, the SRv6 micro-instructions allow expressions of any behaviour (Traffic Engineering, Fast Re-Route (FRR), VPN, Service) with minimum overhead (16 bits per micro-instruction). This is very powerful to address ultra-scale multi-domain 5G and web scale data centre deployments.
Let’s consider a network program with 18 micro-instructions. This would require three containers of six micro-instructions each. One container is placed in the IPv6 DA and two containers are placed in an SRH. This SRH would be 40 bytes long (8 bytes fixed plus 2 x 128-bits (= 2 x 16 bytes)). So, with only 40 bytes of overhead, we can use up to 18 micro-instructions. This is mathematically the best SRv6 compression solution. This is also a noticeable improvement over Multiprotocol Label Switching (MPLS) where an Ingress PE is typically limited to less than 10 pushed labels.
This simplicity and low overhead of SRv6 micro-instructions allow for forwarding implementations at line-rate across several hardware platforms, including multi-Tbps hardware, both with custom and merchant silicon.
Moreover, micro-instructions are seamlessly deployable in IPv6 hosts. It simply requires IP-in-IP encapsulation since the outer IPv6 DA is opaque to the host — a container of six micro-instructions is just seen as a 16-byte opaque DA.
Deployment use-cases
Alibaba
In February 2020, Dennis Cai from Alibaba communicated on his co-development with Cisco Systems and the successful testing of the SRv6 micro-program at line-rate across a range of Cisco platforms: Cisco 8000 (based on Cisco Silicon One), NCS 5500 and ASR 9000. Dennis illustrated a clear SRv6 use-case for a provider such as Alibaba, which has IPv6 enabled across all its infrastructure and its applications.
Bell Canada
In February 2020, Dan Voyer from Bell Canada communicated on his co-development with Cisco Systems and the successful testing of the SRv6 micro-program at line-rate across a range of Cisco platforms: Cisco 8000 (based on Cisco Silicon One), NCS 5500, ASR 9000 and CRS-X.
Dan illustrated a clear SRv6 use-case for a provider such as Bell Canada: integrated 5G service creation (TE, FRR, VPN, NFV) at ultra-scale on an end-to-end basis across several domains. He also pointed out the ability to reuse legacy platforms thanks to the simplicity of the SRv6 micro-instruction concept.
SRv6 micro-instruction interop report
As of February 2020, SRv6 micro-instructions recorded a very successful milestone with an interop report that included implementations in custom and merchant silicon as well as open-source stacks: Cisco 8000, Cisco ASR9000, Cisco NCS5500, and Cisco XRv9K series, Barefoot Tofino, Arrcus with Jericho2, Marvell Falcon, Linux kernel and FD.IO VPP.
More updates on SRv6 technology, deployments and ecosystem are available at the links below.
- http://www.segment-routing.net/srv6-status/
- https://www.rfc-editor.org/rfc/rfc8754.html
- https://datatracker.ietf.org/doc/draft-filsfils-spring-net-pgm-extension-srv6-usid/
- https://tools.ietf.org/html/draft-filsfils-spring-net-pgm-srv6-usid-illus-00
Clarence Filsfils is a Cisco Systems Fellow, with 25-years experience leading innovation, productization, marketing and deployment for Cisco Systems.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Micro-SIDs has the potential to generalize the use of SRv6 in much more lightweight systems such as linux-based User Equipment. It could be used for Service Function Chaining, advantageously replacing NSH.
Thank you so much for great Explanations of Srv6