

How does the largest cloud provider worldwide perform traffic engineering? What are the implications for the geo-distributed applications running in the cloud? We explored these and more questions through a comprehensive set of measurements across the Amazon Web Services (AWS) cloud network.
Cloud provider networks are an indispensable component of today’s Internet, with over 94% of today’s enterprises relying on cloud infrastructures to deploy (some of) their services. Yet, very little is known about how cloud networks perform traffic engineering (TE), that is, the task of optimizing the flow of traffic in a network. The largest cloud providers have long replaced traditional TE (such as MPLS AutoBandwidth) with Software-Defined-Networking (SDN) solutions. SDN allows cloud operators to make efficient use of their resources. For instance, Google reported 100% network utilization in 2013.
The goal of this work is to study the largest cloud provider worldwide, Amazon Web Services (AWS). Our measurement results show that: (1) traffic flows along different paths and frequently moves between paths; and (2) traffic flows may experience unfair treatment in terms of both their experienced latency and the frequency of path changes. We assume that these changes in paths are due to TE and that the observed latencies are due to the properties of a given path through the network.
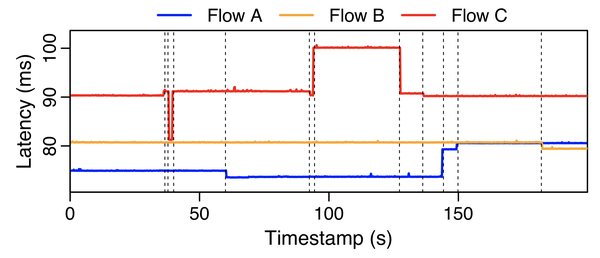
A simple experiment revealing traffic engineering performs at the level of seconds
We ran a simple measurement that established three TCP connections between two virtual machines (VMs) located in two different AWS regions — namely Oregon and Virginia. We assign a different TCP source port to each connection and use ping messages to measure the Round Trip Time (RTT). Figure 1 shows the RTTs over a 200-second experiment. We can immediately note that all flows experience sharp changes in latency followed by relatively stable periods. This simple experiment illustrates the presence of three main patterns:
- TE operates at a frequency of seconds (or tens of seconds).
- Flows may experience a variety of latencies not due to congestion.
- Some flows may experience higher latencies (Flow C) while other flows may experience more RTT changes (Flows A and C).
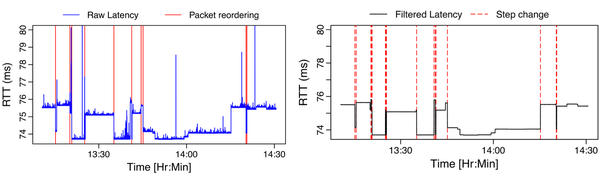
Therefore, we initiated a systematic study on fairness and RTT latency changes in the AWS network. A first natural question to ask is whether the latency ‘jumps’ observed in Figure 1 are the result of frequent TE re-optimization or whether there are some other causes (for example, network obfuscation or congestion). We used a simple yet effective assumption to unravel this puzzle; when a flow is moved from a high-latency path to a low-latency path, the receiver may observe packets being reordered. This happens because the packets routed on the low-latency path will arrive before the ones on the high-latency path.
Figure 2(a) shows an RTT latency measurement (blue line) of a single TCP flow as well as the packet reordering events observed at the receiver side (vertical red lines). We can observe a clear correlation between sharp downward latency changes (followed by stable patterns) and packet reordering events. To detect path changes we rely on a simple sliding-window that performs a mode-based filtering of the observed latencies. Whenever the smoothed latency quickly increases beyond a predefined threshold, we denote this event as a ‘path change’.
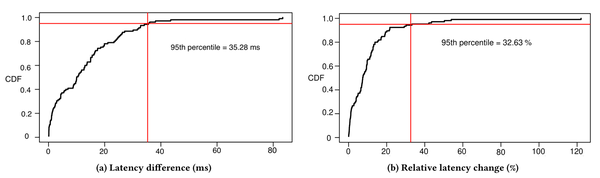
Flows may experience unfair latencies
We used our path-change detector to measure the latency differences across each pair of the 16 AWS regions. We generated 512 distinct flows between each region. Each flow is a TCP connection established on a specific TCP source port. We ran our measurements over two one-week time periods in December 2017 and February 2018. Figure 3(a) and Figure 3(b) shows a cumulative distribution function (CDF) of the absolute and relative differences between the minimum and maximum observed latencies (respectively) for all the region pairs. We observe that in 5% of the regions, flows of traffic may experience a latency unfairness higher than 35ms (this is 32.63% higher than the minimum latency path). These results also show that the actual latency experienced by a flow depends on the source port used to open the connection, thus creating incentives for cloud tenants to probe source ports that are mapped to the shortest paths in the network.
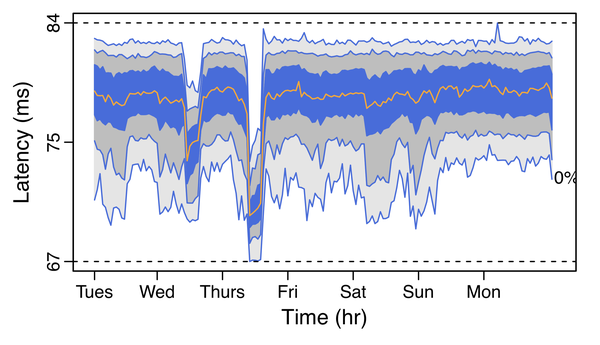
We now zoom into one specific pair of AWS regions, namely Oregon and Virginia, to better understand how the flow latency unfairness manifests itself over time. We can see in Figure 4 the distribution of the minimum, 5th, 25th, 50th, 75th, and 95th percentiles and maximum latencies observed during each 1-hour time interval. We first note that the available paths vary over time. For instance, on Thursday, we can see a new low-latency path appearing and disappearing within hours. For the rest of the time, the distribution of the latencies appears to be more stable. Yet, such stability does not necessarily mean that flows experience the same latency for their entire duration.
Flows experience frequent latency variations
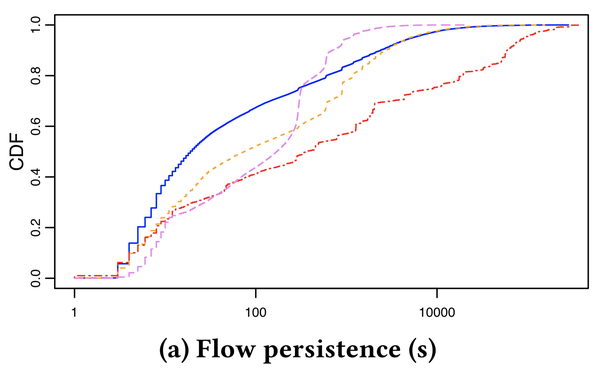
We continue our analysis of the Oregon-Virginia case to find out how long a flow stays on a path after it has been moved to the new path. Figure 5 shows the persistence of a flow, that is, the amount of time before a flow is moved to a different path, for four different regions, with Oregon-Virginia drawn with a dashed pink line. We note the flow persistence is at most 10 seconds for roughly 20% of the flow rerouting events, denoting high levels of instability of flow-to-path assignments between these two critical regions in the US.
Some flows experience prolonged periods of unfairness
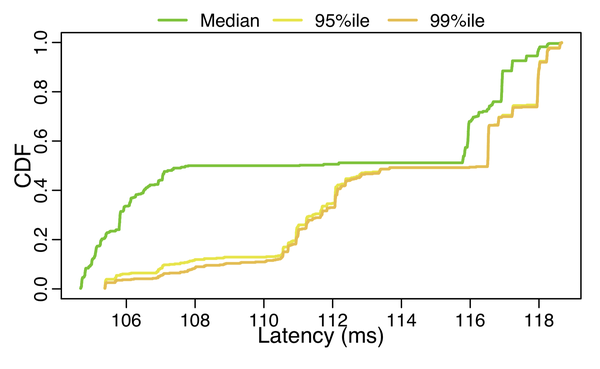
Our last analysis highlights the importance of choosing a ‘good’ TCP source port when opening a connection. Figure 6 shows a CDF of the median, 95th, and 99th percentile latencies experienced by each individual flow (each different TCP source port). Our results show that, at the median, some flows may experience more than 12% of latency unfairness over a one-week period.
The ‘tragedy of the commons’ in the cloud era
There are two interesting implications that arise from the above results. First, cloud tenants may have incentives to probe the latencies obtainable with different TCP source ports and send traffic on the lowest-latency paths. This behaviour may conflict with the TE operation of a cloud network. A cloud operator may actively move flows to less congested paths by altering the TE traffic splitting ratios across the available paths. With regard to the first implementation, we note that existing multi-path transport protocols (such as MPTCP) already perform an exploration of the flow space in order to send traffic on the lowest-latency paths. We leave the study of incentive-compatibility for the future.
Finally, we note that frequent path changes due to cloud TE tools may lead to severe problems with the tenants’ congestion control mechanisms. As an example, during a rerouting event, TCP New Reno interprets packet reordering as a signal of congestion. This ultimately leads to an unnecessary throughput degradation for the cloud tenants. We leave the study of TE and congestion control mechanisms as future work.
This is a joint work by Waleed Reda, Kirill Bogdanov, Alexandros Milolidakis, Marco Chiesa, Gerald Q. Maguire Jr., and Dejan Kostic.
Adapted from original post which appeared on RIPE Labs.
Marco Chiesa is an Assistant Professor at KTH Royal Institute of Technology in Stockholm, Sweden.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.