

Broadcast storms are a major headache for ISPs. They are especially common in developing economies, such as Bangladesh, where large parts of many networks consist of switches instead of routers. Best current practices recommend to keep the switching portion of a network as minimal as possible. However, when very high throughput is required, the cost difference between a router and switch becomes significant.
In our managed switching network at NovoCom Limited, we run Rapid Spanning Tree Protocol (RSTP) to mitigate again broadcast storms. However, we have found this does not necessarily help when we are compelled to connect to our clients or partners at their switches rather than their routers.
When broadcast storms take place, one or many of our switches will have almost 100% CPU utilization, management IPs become unreachable, and clients face up to 100% packet loss.
With 100% CPU utilization, it is not possible to check logs and interface traffic to isolate what traffic is causing this outage. We have to manually or physically shut down clients and partners to determine which network we need to disconnect to make things normal again. This process is very time-consuming and frustrating; especially seeing our network being affected even after having employed loop prevention mechanisms.
Interestingly, we’ve learned that several service provider networks in our region are facing the exact same problem at exactly the same time. Figure 1 illustrates our early prediction of what we thought was happening.
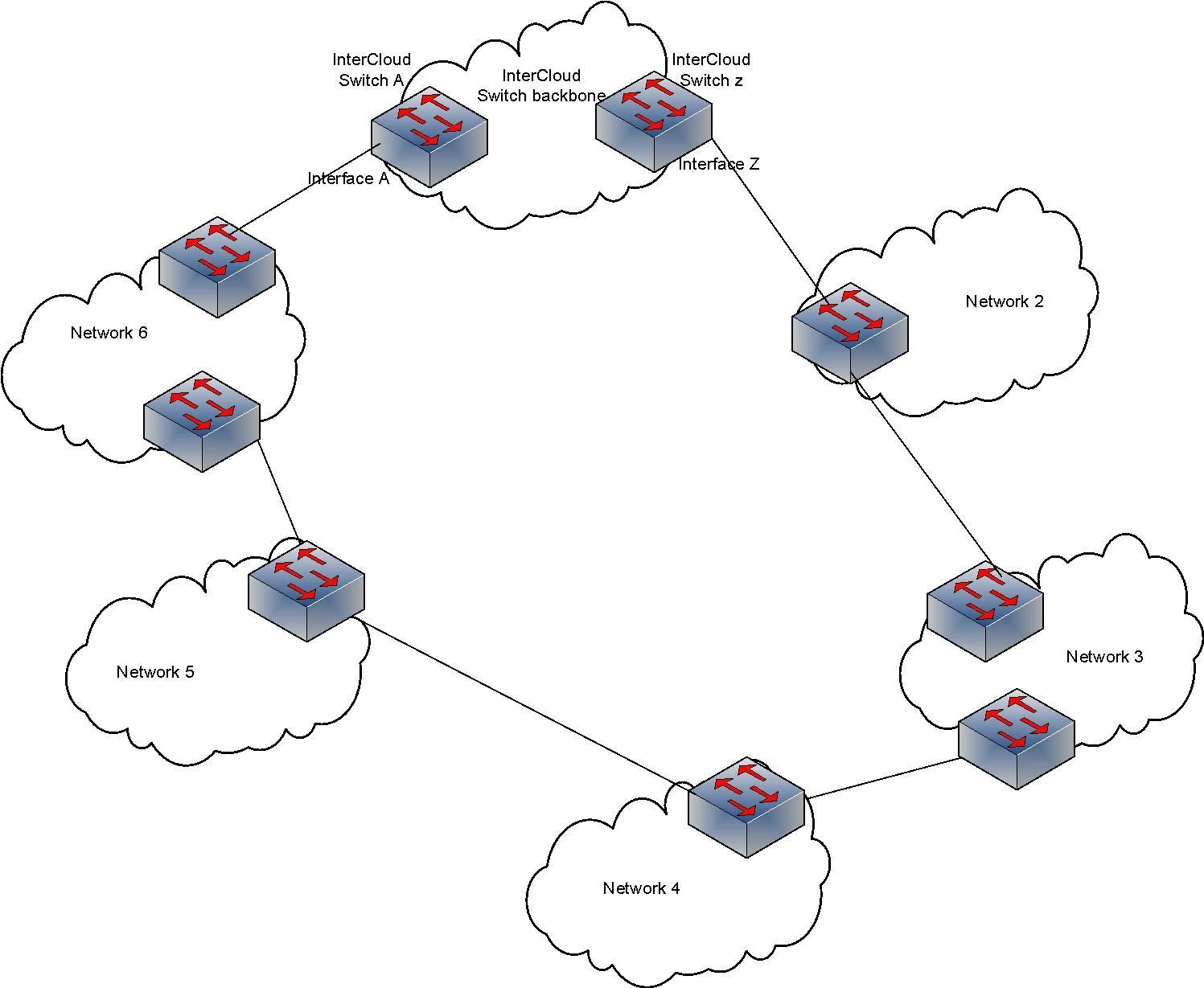
Figure 1 – Nationwide ISPs in Bangladesh can have several zonal ISPs as ‘clients’. These client ISPs peer with other ‘upstream’ ISPs, often via switches. This can cause a switching loop resulting in a broadcast storm.
But even if networks are physically connected in this manner, loops should not occur. In our network we follow a strict policy of allowing specific VLANs in peer-connected interfaces and a specific VLAN is never repeated (for any other peer or service). This means VLANs allowed at Interface A in Figure 1 do not exist at Interface Z, therefore, broadcast domains are completely separate.
Why are we being affected?
To understand this question, I performed some very simple tests with BDCOM switches, which are widely used in Bangladesh. I used BDCOM(TM) S5612 Software, Version 2.2.0C Build 42666. Here are a few of the findings.
When loops are intentionally created, BDCOM switches can detect and prevent loops just fine with STP running. I used a ring of four switches to create a loop for specific VLANs; running STP at only one of the switches still prevented loops by blocking certain interfaces. But the problem occurs when the scenario is something like this:
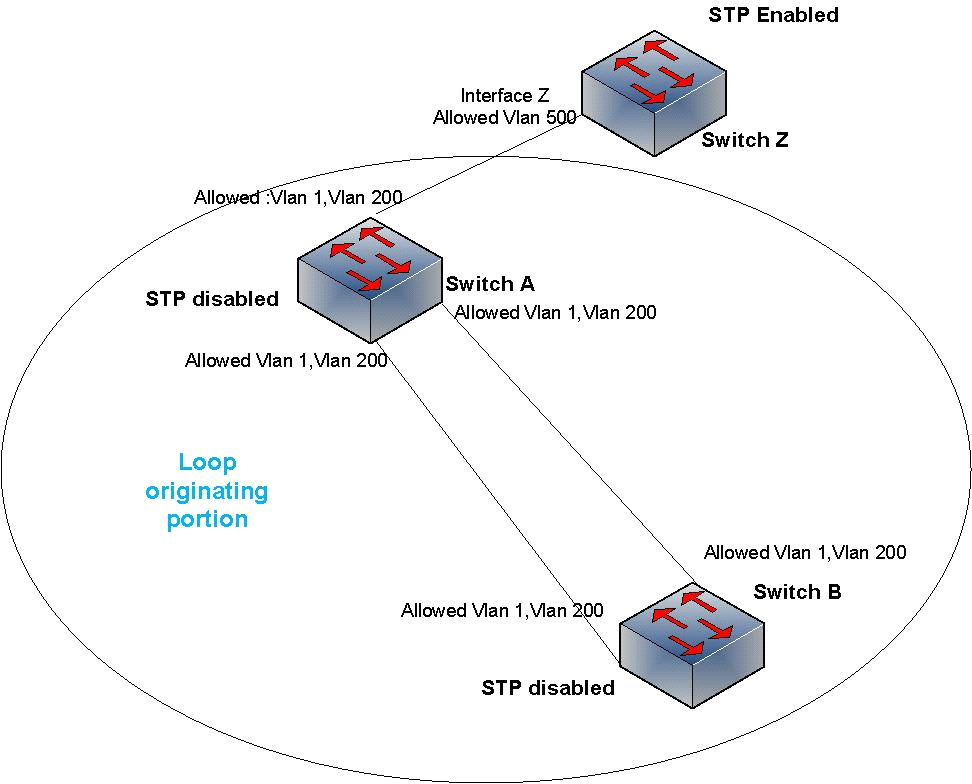
Figure 2 — A loop between switches A and B can cause a broadcast storm affecting switch Z.
I created the loop intentionally at A and B to see how it affects Switch Z. Here the circled portion depicts a network that is connected to our network but we have no control over their STP/VLAN policies. I tried to replicate a network that has STP disabled, and due to a change in physical connectivity, a loop occurred. But our focus is switch Z, as it resembles our device, which is connected to the client/partner.
A single PING to a non-existent IP creates a broadcast storm at switches A and B and takes CPU utilization to 100%. The broadcast storm is occurring in VLANs 1 and 200. But Switch Z should be discarding every packet that does not have a tag of VLAN 500.
So, switch Z itself is not taking part in the loop. But it still becomes unreachable, and CPU utilization becomes 100%.
Switch Z could have saved itself if STP could block the port connected to switch A — a switch detects loops (when STP is enabled) when it sends out BPDU and receives that BPDU on another port. But switch Z is not getting its own BPDU back from switch A via interface Z, which it had sent out through other interfaces. So, there is no reason for STP to conclude that there is any loop and as such does not take the interface into BLK mode.
A single PING from switch A/B to a non-existent IP creates about 900 Mbps traffic at the connected interface of Switch Z. Switch Z is supposed to discard these broadcast packets as the packets do not belong to VLAN 500, but it still has to check every frame, check the VLAN tag and then drop it. Dealing with so many broadcasts leads to CPU utilization of 100%.
And all of these are happening from a broadcast storm that was created by just a single PING. Figure 2 shows what is actually happening in the looping scenarios according to my observations:
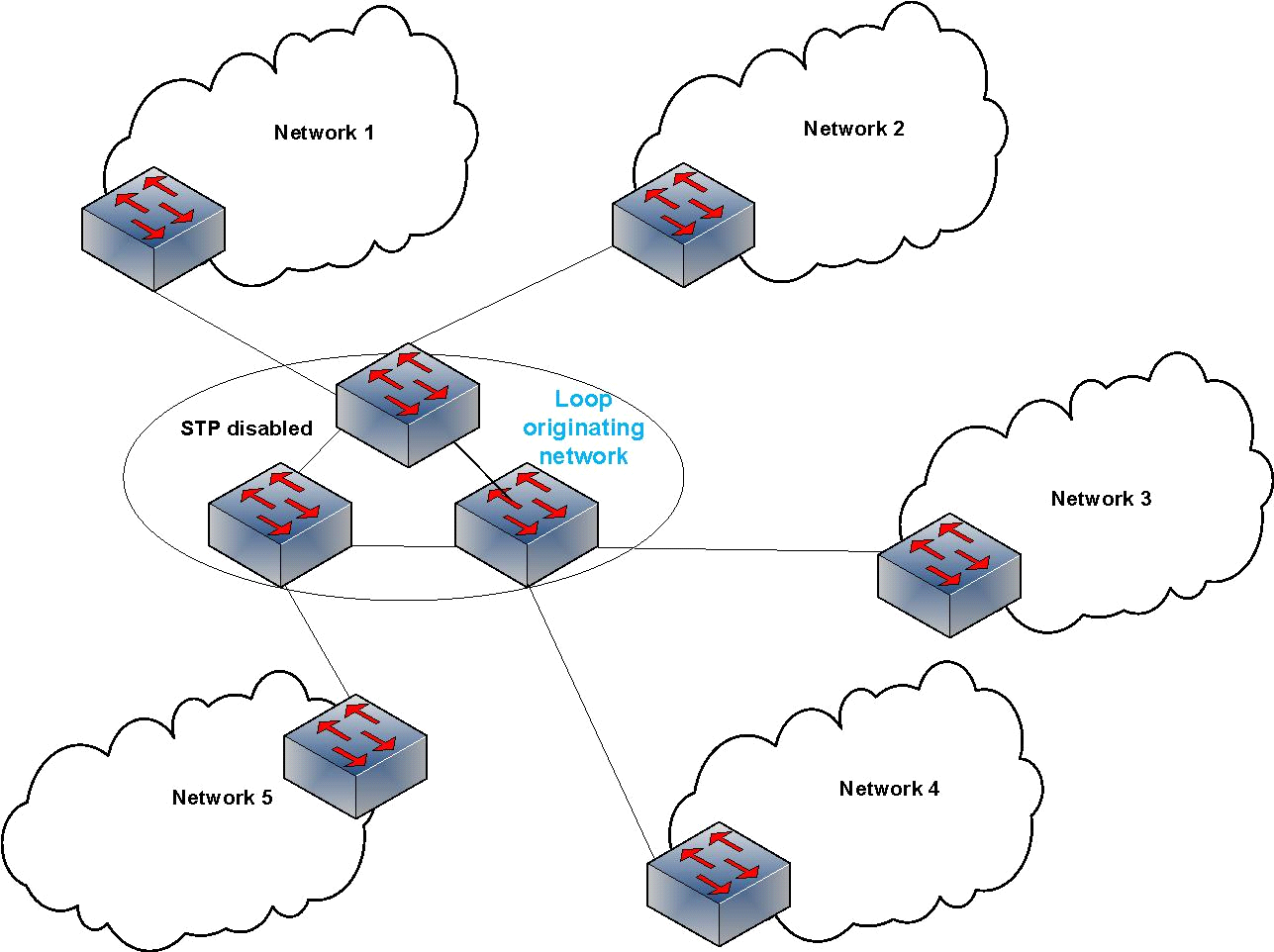
Figure 3 – A switched network with STP disabled can affect all connected networks.
As you can see, not only is the broadcast storm originator network affected but all the attached networks. That is why several networks are affected at the same time.
Recommendations for preventing a broadcast storm
Following my test, I have a few recommendations on how to prevent and manage for broadcast storms:
- Never disable STP in your switching network. PVST+/MSTP can enable efficient use of links. However, you may not have control over switching networks you are peered to.
- To protect yourself from a broadcast storm that could originate in your peer network:
- Connect with your client/partner/peer at their routers rather than their switches.
- If you are compelled to connect to your peers’ switches, configuring the ‘keepalive’ or ‘storm control’ command at client/partner facing interfaces can save the day.
Have you had experience with managing broadcast storms? Share your lessons and thoughts below.
Nafeez Islam is Assistant Manager in Core Network Operations, at NovoCom Limited, Bangladesh.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Really excellent the way you explained…
Thanks for the feedback
Very simple yet strong representation, The content is so true and every single person working with a large infrastructure often deals with this problem. However, it can be prevented by MSTP most efficiently as you’ve mentioned. I would not not say that will be 100% but rest you can manage with smart network architecture
Thanks for the feedback
Any thoughts on how you would come up with reasonable storm control limits to set on interfaces?