

Foresight is a wonderful thing when it comes to planning a network. While every effort is put into designing it with enough capacity and flexibility to grow, inevitably there will come a time when add-ons, patches and extensions start to impact on efficiency and, instead, a full redesign is required. This has certainly been the case for us at LINE Corporation.
Since launching in Japan in 2011, LINE, our flagship app, has more than 160 million active users across Japan, Indonesia, Taiwan and Thailand. Originally and still predominantly used as a messaging app, it has grown to include various products and services including video chat, games, virtual stickers, news streams, video on demand, digital comics and more recently digital payments, all of which have contributed extra load on a network spanning across 30,000 servers.
Having recognized the need to upgrade our network we set about doing so with two objectives in mind: increasing capacity and improving efficiency.
Fed up with large L2 network and complexity
LINE’s original network architecture was a traditional three-tier configuration, with two network switches in one pair. It started to hinder us, particularly as our reliance on machine learning, data analysis, and microservices architecture systems increased, in turn increasing east-west traffic between servers — if one of the switches failed, capacity would degenerate to 50%.
Another deficiency of the original architecture was its complexity. For example:
- It employed a mix of several different protocols and mechanisms for redundancy, including MC-LAG, OSPF, and BGP.
- We had two Top of Rack (ToR) switches installed in each rack, making it redundant — although it is possible to increase availability, packet loss is inevitable when the server and ToR are connected by L2 and switched over.
- As more data centres built with L2 networks were added, so too were the number of VLANs, making the configuration more complex and difficult to operate.
- The BUM traffic problem was also a challenge. Due to the complexity of VLANs, unnecessary traffic such as unknown unicast frames increased, and network traffic efficiency was deteriorating.
Essentially, we were fed up with vendor-dependent protocols and the operation of assigning VLANs to each rack — it was making the configuration more complex and difficult to operate. Also, we needed an infrastructure that could be scaled out horizontally with high capacity.
We decided to redesign the network in the data centre and implement a graceful, automated, and friendly mechanism to enable ToR zero downtime maintenance to address the challenges of the existing network and to increase the traffic in the future as the service expands and the number of users increases.
A new architecture
We have implemented a BGP Clos network (Figure 1) in our data centres that is similar to the model proposed in RFC 7938.
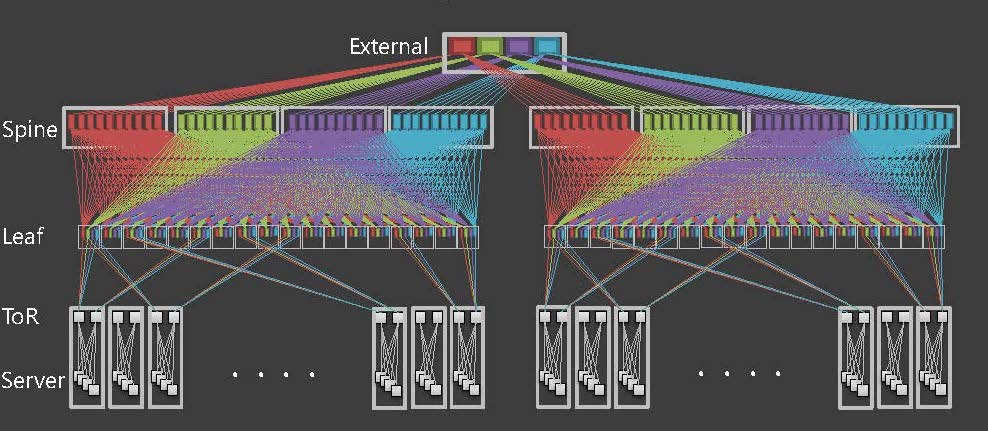
Figure 1 — Overview of LINE’s new network architecture.
A Clos network is a horizontally scalable architecture that overcomes blocking transfer issues of east-west traffic. It has also become a de facto standard design in a number of data centres.
LINE’s Clos network is a 5-stage configuration of ToR-Leaf-Spine (including External Leaf) (Figure 2).
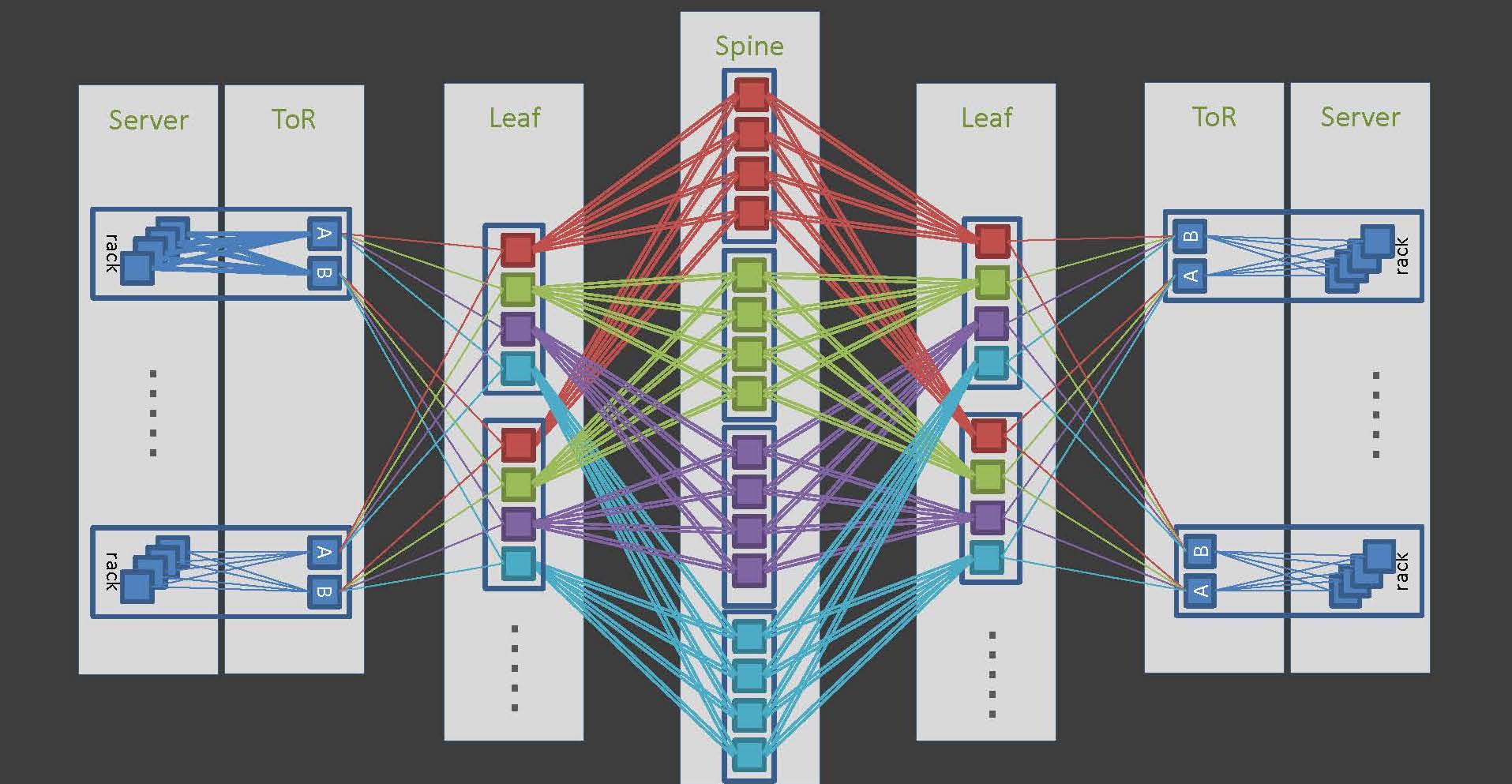
Figure 2 — 5-stage Clos network configuration.
The ToR uplink is 100GE x4 uplinks, and the Leaf and Spine are 100GE x32port form factors, all of which employ off the shelf ‘white box’ switches (Figure 3). The reason for adopting a pizza box switch rather than a modular system switch is to minimize the impact of a single node failure.
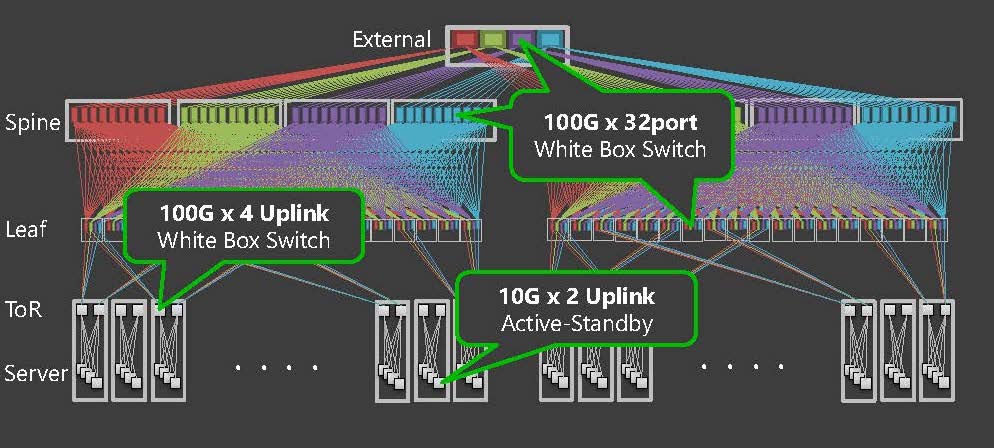
Figure 3 — White box switch deployment.
The server has 10GE x2 uplinks and is connected to a different ToR. It has a capacity of up to 800 Gbps per rack. A key benefit of ToR uplinks is that they can distribute traffic across many paths. This network has a 7.2 Tbps capacity in 1POD and is completely non-blocking even if all servers communicate at 10Gbps (Figure 4).
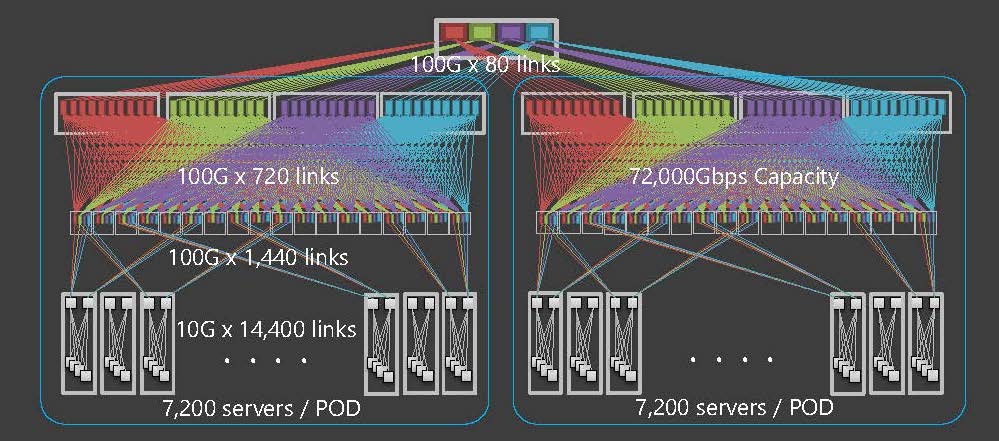
Figure 4 — All servers can communicate at 10Gbps non-blocking.
Overall, more than 1,000 switches are deployed in the data centre.
Why use BGP?
As part of the redesign, we adopted a complete eBGP design and each node is identified by a unique 4-byte private ASN.
We chose to implement BGP because it:
- Is a popular open protocol.
- Allows for easy traffic control.
- Is easy to isolate a particular node.
- Can propagate various information that helps the operation by extending the address family.
- Does not cause periodic multicast packet flooding, such as OSPF.
- Is highly scalable.
Data centre networks using BGP are quite common now, but there are some noteworthy points in LINE’s network. Specifically, all servers speak BGP.
We run the BGP routing daemon on the Hypervisor, on which we establish an eBGP connection to the ToR switch and advertise the host routes of VM running on it. /32 host routes are routed directly, which means we have eliminated the L2 network from our data centres; they are now completely L3 networks (Figure 5).
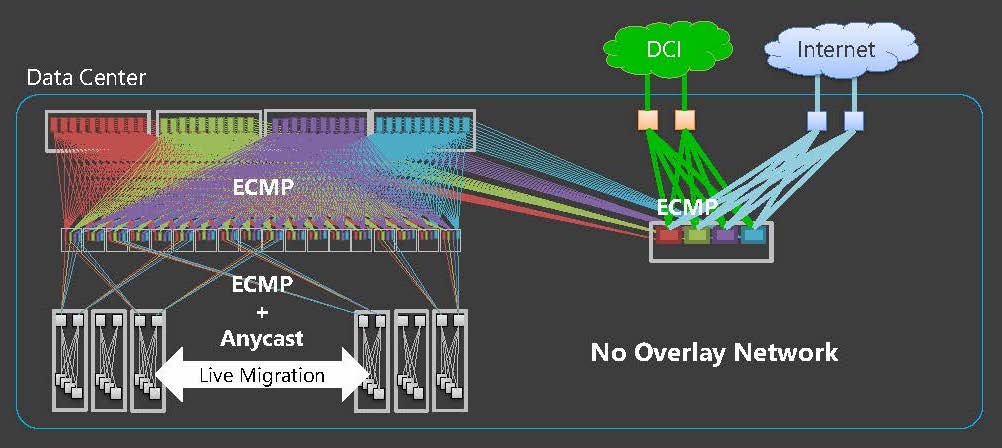
Figure 5 — LINE’s network is now a fully single L3 network comprising BGP data centres.
Moving from a mix of L2 and L3 to just L3 also eliminated not only design complications but also packet encapsulation overheads associated with VLAN management and BUM traffic.
There are some important considerations when applying BGP routing on a server
A BGP configuration requires a separate ASN and a neighbour’s ASN and IP address information. In the case of LINE’s network, where all servers in the data centre are identified by eBGP, more than 10,000 ASNs are required.
It is difficult to assign and manage these ASNs manually. Therefore, we implemented a logic that automatically calculates a unique Private ASN from the 4-byte space by converting the Loopback IP address to decimal.
We extended this automation to most of the network, which my colleagues presented at APRICOT 2019 (see video).
The remaining challenge is to simplify the BGP configuration. We adopted a technology called BGP unnumbered to omit the cumbersome BGP peer configuration. This is a technique that automatically discovers the neighbour using the Router Advertisement (RA) of an IPv6 link-local address that is set in the interface, and then RFC 5549 to exchange the IPv4 NLRI over its IPv6 BGP session. The FRRouting we deployed on the server is a powerful BGP routing daemon that is capable of doing this.

Figure 6 — By employing the BGP unnumbered function and using this logic to automatically calculate the ASN, the BGP configuration has been greatly simplified.
In addition, because the switch must also have the same BGP capability, the deployment of the white box switch was the best way to quickly use the FRRouting function in a network device. We have a unified configuration of the software routing engine that expands the OSS FRRouting on the host and deploys Cumulus Linux (FRRouting works) on the white box switch (Figure 7).

Figure 7 — Advantages of using white box switches.
Simplicity is key
In retrospect, it’s amazing how long our network has been able to cope with the growing number of users in Japan and abroad. After all, LINE was developed to be a quick fix for NHN Japan (a subsidiary of South Korea’s NHN Entertainment Corporation and now under Naver Corporation) staff following the Tōhoku earthquake.
There were many challenges and lessons learned from the experience but the key one for me was the need to employ simplicity.
Throughout the process, LINE pursued the following design philosophies:
Reduce the number of protocols that make up the network — our data centres are now BGP-only.
- Use open protocols wherever possible — BGP is widely implemented meaning that we have no vendor lock-ins.
- Make the network stateless — we have eliminated our overlay network.
Implementing these philosophies and systems required us to completely forget previous operations and ideas and start fresh. It also required a lot of testing and retraining — the system engineers who operate bare metal servers and VMs had to learn basic BGP operations.
Like all major undertakings, it is important to identify trade-offs. These include physical constraints, time constraints and cost constraints. There is no ‘one size fits all’ and we architects must always design to bring out the full power of the network within any such constraints.
By pursuing the ‘simplicity’ of the network, LINE has chosen to manage all constraints as best as possible and solve the problem fundamentally. It was an essential overhaul that has provided us with sufficient capacity and scalability, reduced operational load for the present, and, more importantly, has enabled the network to scale-out to meet the deployment speed that corresponds to the cloud-native era by allowing simple and repeatable elements.
Kobayashi Masayuki is a network engineer for LINE Corporation.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Line team
Brilliant blog: simplicity, L3 everywhere, no vendor lock-in…
Thanks for letting us be part of your journey, wish more DC design use these smart principles
Amit
Nice read. Which hypervisor is being used?